Introduction to Multi-Agent Systems
Multi-agent systems are present everywhere around us, be it early in the morning when you're making your way through traffic to get to work or when your favorite soccer players are competing in a game or when a swarm of bees is trying to build a home in your garden.
Let's consider a scenario where an autonomous car is driving you to office. The aim is to reach office quickly and safely. Anytime it wants to accelerate, brake or change lanes, it does so while considering the other cars in its vicinity. Other cars do the same. All of them are trying to enhance their driving skills on the go as they get more and more driving experience.
Contrast this with a scenario where your car is the only car on the road. The fact that now it doesn't have to interact with other cars makes driving much simpler.
This is nothing but a multi-agent system where multiple agents interact with one another. Agents may or may not know everything about all the others in the system. A multi-agent system is more complex than a single one as illustrated before.
Motivation for Multi-Agent Systems
Keep in mind that the ultimate goal of AI is to solve intelligence. We live in a multi-agent world, we do not become intelligent in isolation. As a baby, the closest interactions that shape us are with our parents. In school, we learn to collaborate and compete with others. We try to predict what might surprise our friends for their birthdays. We learn from others, and our own experiences and so on.
Our intelligence is therefore a result of our interactions with multiple agents over our lifetime. If we want to build intelligent agents that are used in the real world, they have to interact with humans, which are just another agent, and also with other agents. This leads to a multi-agent scenario.
If we really want to solve the problem of intelligence, our agents should be able to achieve their goals in very complex environments. The multi-agent case is a very complex kind of environment because all the agents are learning simultaneously and also interacting with one another. Just like we have in real life. There are different kinds of interactions going on between agents, from coordination to competition, to communication, to prediction, negotiation and so on.
To summarize, here are some of the motivations:
- We live in a multi-agent world.
- Intelligent agents have to interact with humans.
- Agents need to work in complex environments.
Applications of Multi-Agent Systems
Here, we'll discuss some potential real life applications of multi-agent systems. A group of drones or robots whose aim is to pick up a package and drop it to the destination is a multi-agent system. In the stock market, each person who is trading can be considered as an agent and the profit maximization process can be modeled as a multi-agent problem.
Interactive robots or humanoids that interact with humans and get some task done are nothing but multi-agent systems if we consider humans to be agents. Windmills in a wind farm can be thought of as multiple agents. It would be cool if all the agents, that is, the wind turbines figured out the optimal direction to face by themselves, and obtained maximum energy from the wind farm. The aim here is to collaborativelly maximize the profit obtained from the wind farm.
Benefits of Multi-Agent Systems
Having multiple agents in a system brings in a few benefits. The agents can share their experiences with one another making each other smarter, just as we learned from our teachers and friends. However, when agents want to share, they have to communicate, which leads to a cost of communication, like extra hardware and software capabilities.
A multi-agent system is robust. Agents can be replaced with a copy when they fail. Other agents in the system can take over the tasks of the failed agent, but the substituting agent now has to do some extra work.
Scalability comes by virtue of design, as most multi-agent systems allow insertion of new agents easily. But, if more agents are added to the system, the system becomes more complex than before. So, it depends on the assumptions made by the algorithm and the software and hardware capabilities of the agents, whether or not these advantages will be exploited.
From here onwards, we'll learn about multi-agent RL, also known as MARL. When multi-agent systems use RL techniques to train the agents and make them learn their behaviors, we call the process MARL.
Markov Games
Consider an example of single agent RL. We have a drone with the task of grabbing a package. The possible actions are going right, left, up, down, and grasping. The reward is +50 for grasping the package, and -1 otherwise.
The difference in MARL is that we have more than one agent. So, say, we have a second drone. Now, both the drones are collaboratively trying to grasp the package. They're both observing the package from their perspective positions. They both have their own policies that returned an action for their observations. Both also have their own set of actions.
The main thing about MARL is that there is also a joint set of actions. Both the left drone and the right drone must begin action. For example, the (D,L) means the left drone moves down and the right drone moves to the left. This example illustrates the Markov game framework, which we want to discuss now.
A Markov game is a tuple written as below:

where n is the number of agents, S is the set of states of the environment, A_i is the set of action of each agent i, A is the joint action space, O_i is the set of observations of agent i, R_i is the reward function of agent i, which returns a real value for acting an action in a particular state, \pi_i is the policy of each agent i, that given its observations, returns a probability distribution over the actions A_i, T is the state transition function. Given the current state and the joint action, it provides a probability distribution over the set of possible next states.
Note that even here the state transitions are Markovian, just like in an MDP. Recall that Markovian means that the next state depends only on the present state and the actions taken in this state.
However, the transition function now depends on the joint action. You may find slightly varying definitions at different places.
Approaches to MARL
So, can we think about adapting the single-agent techniques we've learned about so far to the multi-agent case? Two extreme approaches come to mind.
The simplest approach should be to train all the agents independently without considering the existence of other agents. In this approach, any agent considers all the others to be a part of the environment and learns its own policy. Since all are learning simultaneously, the environment as seen from the prospective of a single agent, changes dynamically. This condition is called non-stationarity of the environment. In most single agent algorithms, it is assumed that the environment is stationary, which leads to certain convergence guarantees. Hence, under non-stationarity conditions, these guarantees no longer hold.
The second approach is the meta-agent approach. The meta-agent approach takes into account the existence of multiple agents. Here, a single policy is lowered for all the agents. It takes as input the present state of the environment and returns the action of each agent in the form of a single joint action vector.
Typically, a single reward function given the environment state and the action vector returns a global reward. The joint action space, as we had discussed before, would increase exponentially with the number of agents. If the environment is partially observable or the agents can only see locally, each agent will have a different observation of the environment state, hence, it will be difficult to disambiguate the state of the environment from different local observations. So this approach works well only when each agent knows everything about the environment.
Cooperation, Competition, Mixed Environments
Let's pretend that you and your sister are playing a game of pong. You're given one bank of 100 coins from which you plan on buying a video game console. For each time either of you misses the ball, you lose one coin from the bank to your parents. Hence, you both will try to keep the ball in the game to have as many coins as possible at the end. This is an example of cooperative environment where the agents are concerned about accomplishing a group task and cooperate to do so.
Consider that now you both have two separate banks. Whoever misses the ball gives a coin from their bank to the other. So, now instead of cooperating, you're competing with one another. One sibling's gain is the other's loss. This is an example of competitive environment where the agents are just concerned about maximizing their own rewards.
Notice how in the cooperative setting both you and your sibling lose a coin while in the competitive setting, one loses a coin when the other gains a coin. So, the way reward is defind makes the agent's behavior apparently competitive or apparently collaborative. In many environments, the agents have to show a mixture of cooperative and competitive behaviors which leads to mixed cooperative-competitive environments.
Research Topics
The field of multi-agent RL is in the cutting edge of research. Recently, OpenAI announced that its team of five neural networks, OpenAI 5 has learned to defeat amatuer DOTA2 players. OpenAI 5 has been trained using a scaled-up version of BPO. Coordination between agents is controlled using a hyperparameter called team spirit. It ranges from 0 to 1, where 0 means agents can only care about the individual reward functions while one means that they completely care about the team's reward function.
Paper Description
There are many interesting papers out there on MARL. For the purposes of this lesson, we will stick to one particular paper called “Multi Agent Actor Critic for Mixed Cooperative Competitive environments “ by OpenAI.
This paper implements a multi-agent version of DDPG. DDPG is an off-policy actor-critic algorithm that uses the concept of target networks. The input of the action network is the current state while the output is a real value or a vector representing an action chosen from a continuous action space.
OpenAI has created a multi-agent environment called multi-agent particle. It consists of particles that is agents and some landmarks. A lot of interesting experimental scenarios have been laid out in this environment. We've chosen one of the many scenarios called physical deception.
Here, any agents cooperate to reach the target landmark out of n landmarks. There is an adversary which is also trying to reach the target landmark, but it doesn't know which out of the n landmarks is the target landmark.
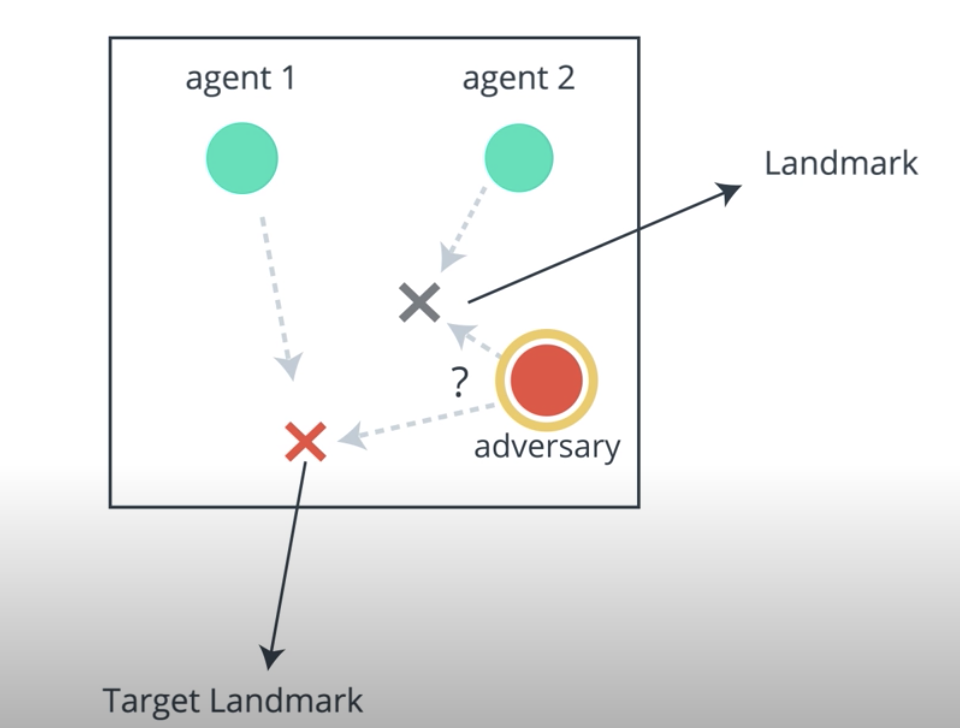
The normal agents are rewarded based on the least distance of any of the agents to the landmark, and pernalized based on the distance between the adversary and the target landmark. Under this reward structure, the agents cooperate to spread out across all the landmarks, so as to deceive the adversary.
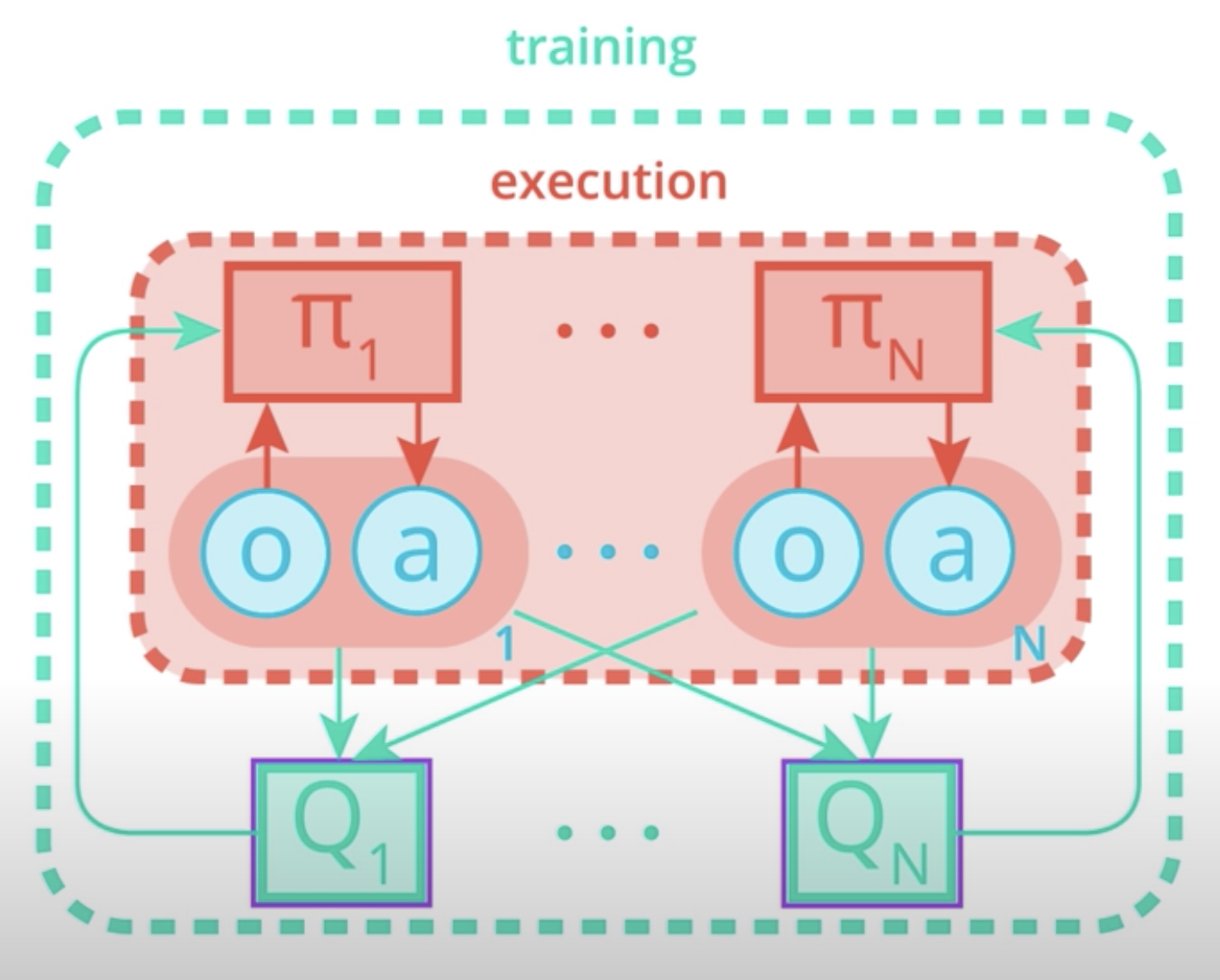
The framework of centralized trading with decentralized execution has been adopted in this paper. This implies that some extra information is used to ease dreaming, but that information is not used during the testing time.
This framework can be naturally implemented using an actor-critic algorithm. Let's see why.
During training, the pretext for each agent uses extra information like states observed and actions taken by all the other regions. As for the actor, you'll notice that there is one for each agent. Each actor has access to only its agent's observation and actions.
During execution time, only the actors are present, and hence, all observations and actions are used.
Learning critic for each agent allows us to use a different reward structure for each. Hence, the algorithm can be used in all, cooperative, competitive, and mixed scenarios.
See the video here.
Lab Instructions
For this Lab, you will train an agent to solve the Physical Deception problem.
This is an ungraded project, Feel free to explore various parameters and see how it affects the way agents approach the problem.
Goal of the environment
Blue dots are the "good agents", and the Red dot is an "adversary". All of the agents' goals are to go near the green target. The blue agents know which one is green, but the Red agent is color-blind and does not know which target is green/black! The optimal solution is for the red agent to chase one of the blue agent, and for the blue agents to split up and go toward each of the target.
Running within the workspace ( Recommended Option)
- No explicit setup commands need to run by you, we have taken care of all the installations in this lab, enjoy exploration.
- ./run_training.sh Let's you run the program based on the parameters provided in the main program.
- ./run_tensorboard.sh will give you an URL to view the dashboard where you would have visualizations to see how your agents are performing. Use this as a guide to know how the changes you made are affecting the program.
- Folder named Model_dir would store the episode-XXX.gif files which show the visualization on how your agent is performing.
Running on your own computer
-
If you choose to run the program on your computer, you should download the files from the workspace and all the above commands should work the same except for few installations below.
-
Use of GPU wouldn't impact the training time for this program, Instead, Multicore environments would be a better choice to increase the training speed.
Requirements
- OpenAI baselines, commit hash: 98257ef8c9bd23a24a330731ae54ed086d9ce4a7
- PyTorch, version: 0.3.0.post4
- OpenAI Gym, version: 0.9.4
- Tensorboard, version: 0.4.0rc3 and Tensorboard-Pytorch, version: 1.0 (for logging)
To Experiment
- Feel free to clear the model_dir and log folder and start training on your own to see how your agent performs. ./clean.sh should help you accomplish this goal.
- This lab is meant to prepare you for the final project, writing your own functions in maddpg.py will improve your learning curve.
- Also experiment with parameter tuning in main.py, Make note that a larger number of episodes would mean greater training time.
- Lab might take more than one hour to train depending on how the parameters are tuned.
Find the codes under codes/DDPG_lab.