Preface
Lesson: Introduction to Policy-Based Methods
In this lesson, you will learn about methods such as hill climbing, simulated annealing, and adaptive noise scaling. You'll also learn about cross-entropy methods and evolution strategies.
Lesson: Policy Gradient Methods
In this lesson, you'll study REINFORCE, along with improvements we can make to lower the variance of policy gradient algorithms.
Lesson: Proximal Policy Optimization
In this lesson, you'll learn about Proximal Policy Optimization (PPO), a cutting-edge policy gradient method.
Lesson: Actor-Critic Methods
In this lesson, you'll learn how to combine value-based and policy-based methods, bringing together the best of both worlds, to solve challenging reinforcement learning problems.
Lesson: Deep RL for Finance (Optional)
In this optional lesson, you'll learn how to apply deep reinforcement learning techniques for optimal execution of portfolio transactions.
Resources (Optional)
- Read the most famous blog post on policy gradient methods.
- Implement a policy gradient method to win at Pong in this Medium post.
- Learn more about evolution strategies from OpenAI.
Introduction
In this lesson, you'll learn all about policy-based methods. Watch the video below to learn what policy-based methods are, and how they differ from value-based methods!
RL is uttimately about learning an optimal policy from interaction with the environment. So far, we've been looking at value-based methods, where we first tried to find an estimate of the optimal action value function.
For small state spaces, this optimal value function was represented in a table with one row for each state and one column for each action. Then, we use the table to build the optimal policy one state at a time. For each state, we just pull its corresponding row from the table and the optimal action is just the action with the largest entry.
But, what about environments with much larger state spaces? For instance, consider the cartpole environment, where the goal is to teach an agent to balance a pole that's attached to a moving cart.
At each time step, the agent pushes the cart either to the left or to the right to try to keep the pole from failing down. The stated ending timestamp is a vector with four numbers containing the cart's position and velocity, along with the pole's angle and velocity.

There's a huge number of possible states corresponding to every possible value that these board numbers (picture above) can have. So, without some sort of discretization technique, it's impossible to represent the optimal action value function in a table. This is because we would need a row for each possible state, and that would make the table way too big to be useful in practice.
So, we investigated how to represent the optimal action value function with a nerual network which formed the basis for the deep Q learning algorithm. In this case, neural network took the environment state as input. As output, it returned the value of each possible action.
In the case of cartpole, for instance, the possible actions are to move the cart left or right. Then, identical to the previous setting where we used the table, we can easily obtain the best action for any state by just looking at the values of the input state produces in the network. It's just the action that maximizes these values.
But the important message here is that in both cases, whether we used a table for small state spaces or a neural network for much larger state spaces, we had to first estimate the optimal action value function before we could tackle the optimal policy.
But now the question is: can we directly find the optimal policy without worrying about a value function at all? The answer is yes, and we accomplish this through a class of algorithms known as policy-based methods.
See the video here.
Policy Function Approximation
How might we approach this idea of estimating an optimal policy?
Let's consider the cartpole example. In this case, the agent has two possible actions, he can push the cart either left or right. So, at each time step, the agent picks one of these two options. We can construct a neural network that approximates the policy, that accepts the state as input. As output, it can return the probability that the agent selects each possible action. So, if there are two possible actions, the output layer will have two nodes.
The agent uses the policy to interact with the environment by just passing the most recent state to the network. It outputs action probabilities and then the agent samples from those probabilities to select an action in response.
Our objective then is to determine appropriate values for the network weights so that for each state that we pass into the network it returns action probabilities where the optimal action is most likely to be selected.
This will help the agent with its goal to maximize expected return. This is an iterative process where the weights are initially set to random values. Then, as the agent interacts with the environment and learns more about what strategies are best for maximizing reward, it amends those weights. As a direct result, the agent starts to choose the appropriate action for each date and it gradually masters the task.
See the video here.
More on the Policy
In the previous video, you learned how the agent could use a simple neural network architecture to approximate a stochastic policy. The agent passes the current environment state as input to the network, which returns action probabilities. Then, the agent samples from those probabilities to select an action.
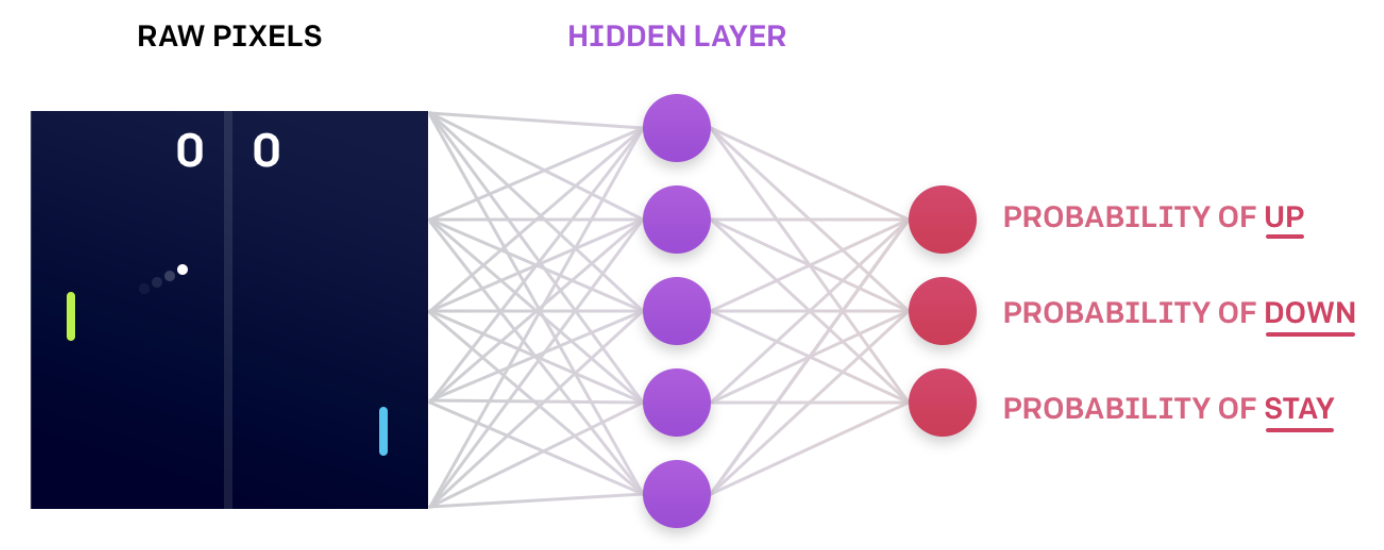
The same neural network architecture can be used to approximate a deterministic policy. Instead of sampling from the action probabilities, the agent need only choose the greedy action.
What about continuous action spaces?
The CartPole environment has a discrete action space. So, how do we use a neural network to approximate a policy, if the environment has a continuous action space?
As you learned above, in the case of discrete action spaces, the neural network has one node for each possible action.
For continuous action spaces, the neural network has one node for each action entry (or index). For example, consider the action space of the bipedal walker environment, shown in the figure below.
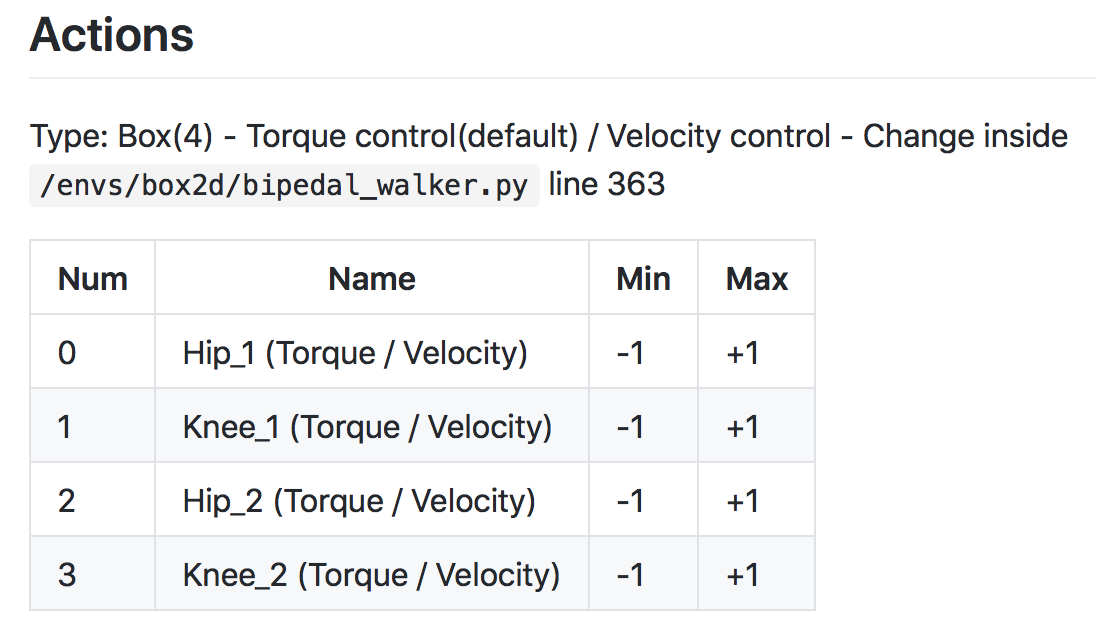
Action space of BipedalWalker-v2 (Source)
In this case, any action is a vector of four numbers, so the output layer of the policy network will have four nodes.
Since every entry in the action must be a number between -1 and 1, we will add a tanh activation function to the output layer.
As another example, consider the continuous mountain car benchmark. The action space is shown in the figure below. Note that for this environment, the action must be a value between -1 and 1.
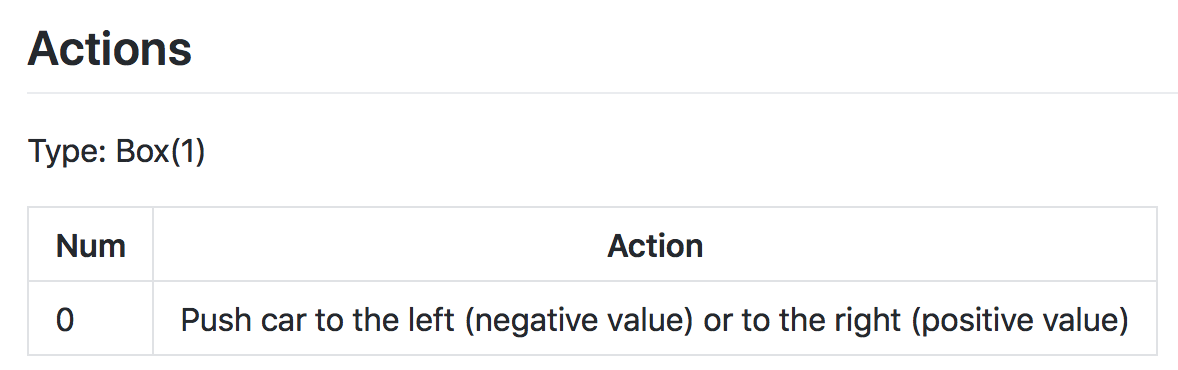
Action space of MountainCarContinuous-v0 (Source)
Hill Climbing
So far, you've learned how to represent a policy as neural network. This network takes the current environment state as input, then if the environment has a discrete action space it outputs the action probabilities that the agent uses to select its next action.
Here, we'll describe an algorithm that the agent can use to gradually improve the network weights. So, remember that the agent's goal is always to maximize expected return. Let's denote the expected return by .
We'll refer to the set of weights in the neural network as , there is some mathematical relationship between
and the expected return
. This is because
encodes the policy which makes some actions more likely than others, and then depending on the action the influences the reward and then we sum up the rewards to get the return.
Actually, it sounds potentially quite complicated. But the main idea is that it's possible to write the expected return as a function of
and that function looks like this:
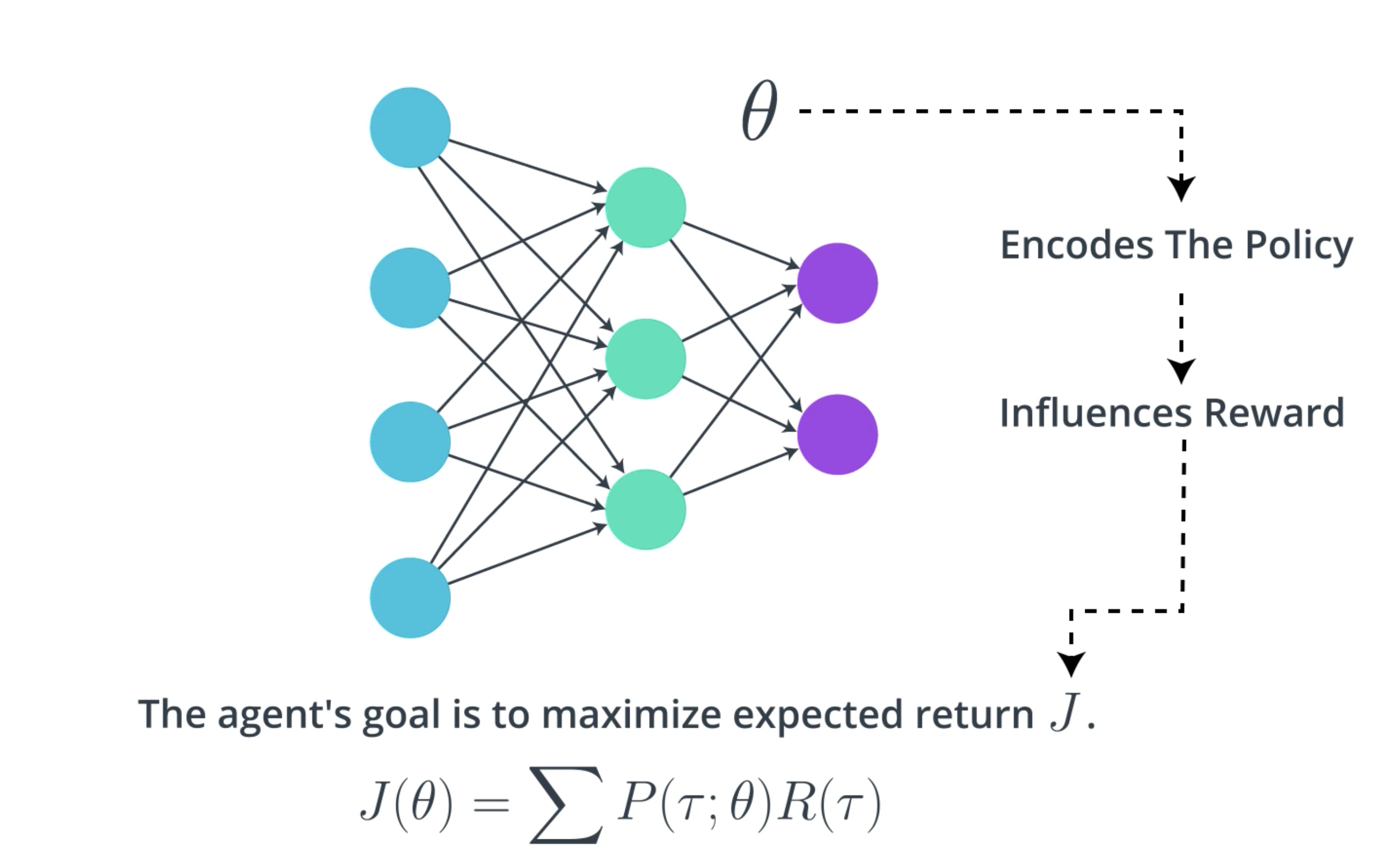
Now, this equation shouldn't make any sense to you yet, but we'll come back to it later on. For now, just know that it exists, and our goal is to find the values for , or the values for the weights that maximizes
.
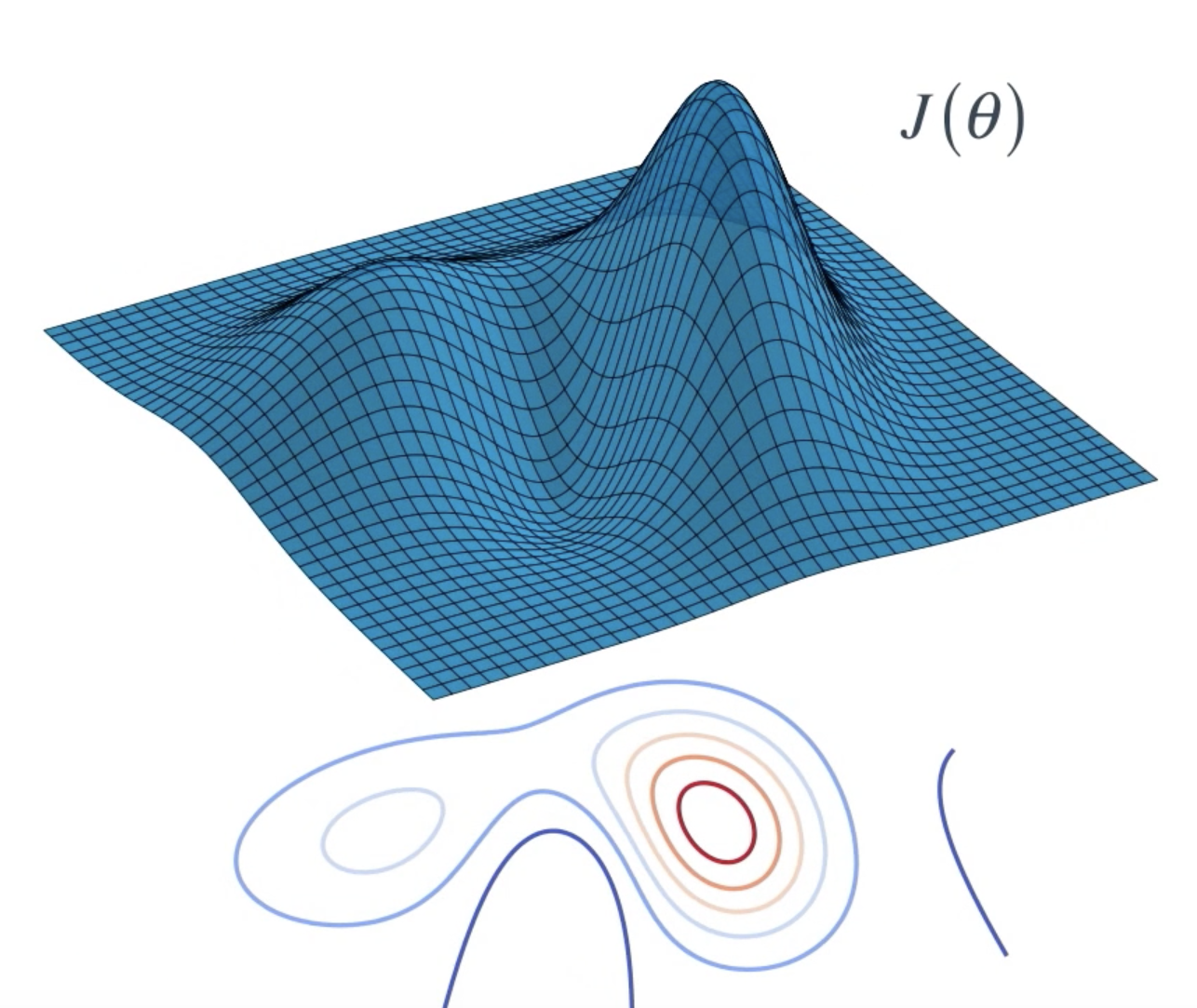
To understand this better, let's draw a picture. Consider a case that the neural network has only two weights: . Then, we can plot the expected return
as a function of the values of both of the weights, for each weight gets a different axis, and once we have that function we can use it to find the value of
or the values of both of the weights that maximizes expected return.
Maybe, you're familiar with one algorithm that could be useful for this called gradient ascent.
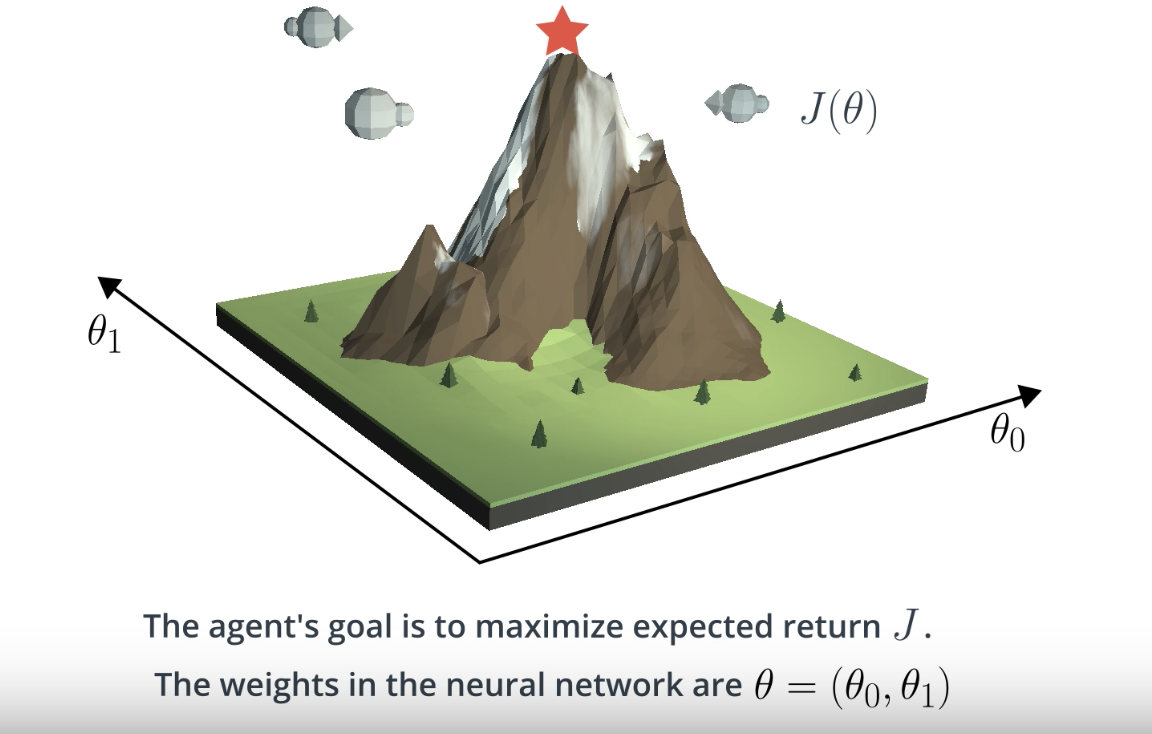
Gradient ascent begins with an initial guess for the value of that maximizes the function, then we evaluate the gradient at that point (gredient points to the steepest direction in a function), and so we can make a small step in that direction, in the hope that we end up at a new value of
or the value of the function is a little bit larger. Then, we repeat with evaluating the gradient and taking a step until we eventually reach the maximum of the function.
Now, in order to do this, we have to take the gradient of the function. We'll discuss this later. For now, we'll discuss a different algorithm called Hill Climbing, that's a little bit simpler.
As with gradient ascent, we begin with an initially random set of weights . We collect a single episode with the policy that corresponds to those weights and then record the return. This return is an estimation of what the surface looks like at that value of
.
Now, it's not going to be perfect estimate because the return we just collected is unlikely to be equal to the expected return, but in practice the estimates often turns out to be good enough. Then, we'll add a little bit of random noise to those weights to give us another set of candidate weights we can try.
To see how good those new weights are, we'll use the policy that they give us to again interact with the environment for an episode and add up the return. If the new weights give us more return than our current best estimate, we focus our attention on that new value, and then we just repeat by iteratively proposing new policies in the hope that they outperform the existing policy.
In the event that they don't, we just go back to our last best guess for the optimal policy and iterate until we end up with the optimal policy.
See the video here.
Gradient Ascent
Gradient ascent is similar to gradient descent.
- Gradient descent steps in the direction opposite the gradient, since it wants to minimize a function.
- Gradient ascent is otherwise identical, except we step in the direction of the gradient, to reach the maximum.
While we won't cover gradient-based methods in this lesson, you'll explore them later in the course!
Local Minima
In the video above, you learned that hill climbing is a relatively simple algorithm that the agent can use to gradually improve the weights \thetaθ in its policy network while interacting with the environment.
Note, however, that it's not guaranteed to always yield the weights of the optimal policy. This is because we can easily get stuck in a local maximum. In this lesson, you'll learn about some policy-based methods that are less prone to this.
Additional Note
Note that hill climbing is not just for reinforcement learning! It is a general optimization method that is used to find the maximum of a function.
Hill Climbing Pseudocode
Now that we have a mental picture of how the hill climbing algorithm should work, we're ready to dig into the pseudocode.
- We begin with an initially random set of weights
.
- We'll collect an episode with the policy that correspond to those weights, and then record the return
.
- At the start, this value
. We'll also record the return as the highest return we've gotten so far,
.
- Then, we add a little bit of random noise to these weights to give us another set of candidate weights we can try out. Let's call them
.
- To see how good those new weights are, we'll use the policy that they give us to interact with the environment, then we calculate the return we got which we refer to as
.
- If the new weights give us more return than our current best estimate ,
, we update the best weights to that new value,
.
- Then, we just repeat these steps until we solve the environment. That's it!
See the video here.

What's the difference between G and J?
You might be wondering: what's the difference between the return that the agent collects in a single episode (, from the pseudocode above) and the expected return
?
Well ... in reinforcement learning, the goal of the agent is to find the value of the policy network weights that maximizes expected return, which we have denoted by
.
In the hill climbing algorithm, the values of are evaluated according to how much return
they collected in a single episode. To see that this might be a little bit strange, note that due to randomness in the environment (and the policy, if it is stochastic), it is highly likely that if we collect a second episode with the same values for
, we'll likely get a different value for the return
. Because of this, the (sampled) return
is not a perfect estimate for the expected return
, but it often turns out to be good enough in practice.
Beyond Hill Climbing
In the previous section, you learned about the hill climbing algorithm.
We denoted the expected return by . Likewise, we used
to refer to the weights in the policy network. Then, since
encodes the policy, which influences how much reward the agent will likely receive, we know that
is a function of
.
Despite the fact that we have no idea what that function looks like, the hill climbing algorithm helps us determine the value of
that maximizes it. Watch the video below to learn about some improvements you can make to the hill climbing algorithm!
Note: We refer to the general class of approaches that find through randomly perturbing the most recent best estimate as stochastic policy search. Likewise, we can refer to
as an objective function, which just refers to the fact that we'd like to maximize it!
With an objective function in hand, we can now think about finding a policy that maximizes it. An objective function can be quite complex. Think of it as a surface with many peaks and valleys.
Here, it's a function of two parameters with the height indicating the policy's objective value . But the same idea extends to more than two parameters.
Now, we don't know anything about this surface. So, how do we find the spot where the objective value is at its maximum?
Our first approach is to search for the best policy by repeatedly nudging it around. Let's start with some arbitrary policy , defined by its parameters
, and evaluate it by applying that policy in the environment. This gives us an objective value. So you can imagine the policy lying somewhere on the objective function surface.
Now, we can change the policy parameters slightly so that the objective value also changes. This can be achieved by adding some small Guassian noise to the parameters.
If the new policies value is better than our best value so far, we can set this policy to be our bew best policy and iterate.
This general approach is known as hill climbing. You literally walk the objective function surface till you reach the top of a hill.
The best part is that you can use any policy function. It does not need to be differentiable or even continuous, but because you're taking random steps, this may not result in the most eficient path up the hill.
One small improvement to this approach is to choose a small number of neighboring policies at each iteration and pick the best among them.
It's easier to understand this by looking at a contour plot. Again, starting with an arbitrary policy, evaluate it to find out where it lies. Generate a few candidate policies by perturbing the parameters randomly and evaluate each policy by interacting with the environment. This gives us an idea of the neighborhood of the current policy.
Now, pick the candidate policy that looks most promising and iterate. This variation is known as steepest ascent hill climbing and it helps reduce the risk of selecting a next policy that may lead to a suboptimal solution.

You could still get stuck in local optima. But there are some modifications that can help mitigate that, for example, by using random restarts or simulated annealing.
Simulated annealing uses a predefined schedule to control how the policy space is explored. Starting with a large noise parameter, that is a broad neighborhood to explore, we gradually reduce the noise or radius as we get closer to the optimal solution. This is somewhat like annealing an iron by heating it up and then letting it cool down gradually. It allows iron molecules to settle into an optimal arrangement resulting in a hardened metal, hence the name.
We can also make our approach more adaptive to the changes in policy values being observed. Here's the intuition.
Adaptive Noise Scaling:
Whenever we find a better policy than before, we're likely getting closer to the optimal policy. So, it makes sense to reduce our search radius for generating the next policy. This translates to reducing or decaying the variance of the Gaussian noise we add. So far, it's just like simulated annealing. But, if we don't find a better policy it's probably a good idea to increase our search radius and continue exploring from the current best policy. This small tweak to stochastic policy search makes it much less likely to get stuck, especially in domains with a complicated objective function.
See the video here.
More Black-Box Optimization
All of the algorithms that you’ve learned about in this lesson can be classified as black-box optimization techniques.
Black-box refers to the fact that in order to find the value of that maximizes the function
, we need only be able to estimate the value of
at any potential value of
.
That is, both hill climbing and steepest ascent hill climbing don't know that we're solving a reinforcement learning problem, and they do not care that the function we're trying to maximize corresponds to the expected return.
These algorithms only know that for each value of , there's a corresponding number. We know that this number corresponds to the return obtained by using the policy corresponding to
to collect an episode, but the algorithms are not aware of this. To the algorithms, the way we evaluate
is considered a black box, and they don't worry about the details. The algorithms only care about finding the value of
that will maximize the number that comes out of the black box.
In the video below, you'll learn about a couple more black-box optimization techniques, to include the cross-entropy method and evolution strategies.
So far, you've learned about a couple of different algorithms that we can use to optimize the weights of the policy networks.
Hill climbing begins with a best guess for the weights, then it adds a little bit of noise to propose one new policy that might perform better. Steepst ascent hill climbing does a little bit more work by generating several neighboring policies at eac iteration. But, in both cases, only the best policy prevails. For steepest ascent hill climbing there's a lot of useful information that we're throwing out.
Here, we're going to learn about some methods that leverage useful information from the weights that aren't selected as best. So what if instead of selecting only the best policy, we select the top 10 or 20 percent of them, and took the average? This is what the Cross Entropy Method does.
Another approach is to look at the return that was collected by each candidate policy. The best policy will be a weighted sum of all of these, where policies that got higher return are given more say or get a higher weight. This technique is called Evolution Strategies. The name originally comes from the idea of biological evolution, where the idea is that the most successful individuals in the policy population, who have the most influence on the next generation or iteration.
That said, it's best to think of evolution strategies as just another black-box optimization technique.
See the video here.
Coding Exercise
In the following, you will explore implementations of two different policy-based methods.
OpenAI Request for Research
So far in this lesson, you have learned about many black-box optimization techniques for finding the optimal policy. Run each algorithm for many random seeds, to test stability.
Take the time now to implement some of them, and compare performance on OpenAI Gym's CartPole-v0 environment.
Note: This suggested exercise is completely optional.
Once you have completed your analysis, you're encouraged to write up your own blog post that responds to OpenAI's Request for Research! (This request references policy gradient methods. You'll learn about policy gradient methods in the next lesson.)
Implement (vanilla) hill climbing and steepest ascent hill climbing, both with simulated annealing and adaptive noise scaling.
If you also want to compare the performance to evolution strategies, you can find a well-written implementation here. To see how to apply it to an OpenAI Gym task, check out this repository.
To see one way to structure your analysis, check out this blog post, along with the accompanying code.
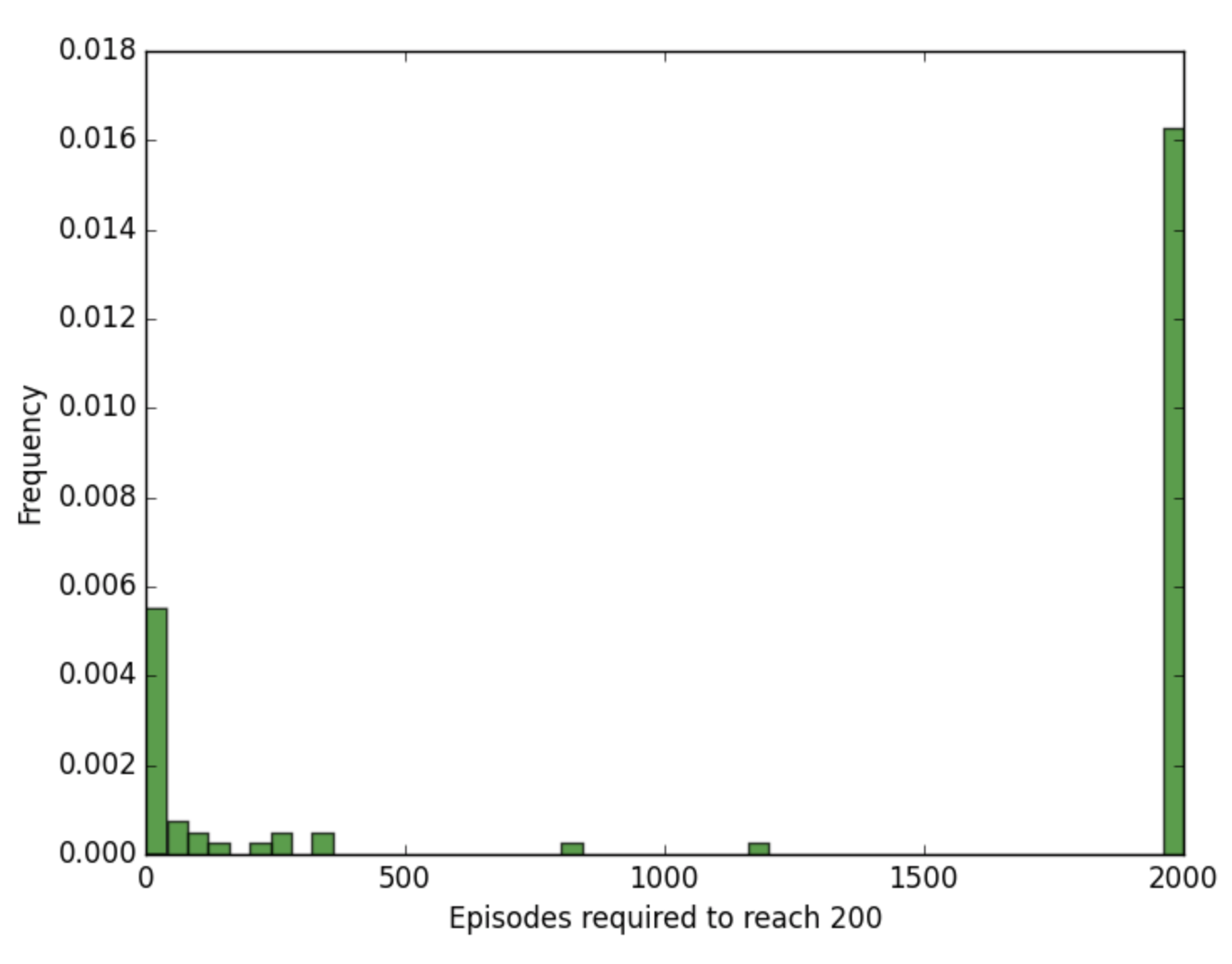
For instance, you will likely find that hill climbing is very unstable, where the number of episodes that it takes to solve CartPole-v0 varies greatly with the random seed. (Check out the figure below!)
Why Policy-Based Methods?
In this lesson, you've learned about several policy-based methods. But why do we need policy-based methods at all, when value-based methods work so well?
You may be wondering why do we need to find optimal policies directly when value-based methods seem to work so well.
There are three arguments we'll consider:
- Simplicity
- Stochastic Policies
- Continuous Action Spaces
Simplicity
Remember that in value-based methods like Q-learning, we invented this idea of a value function as an intermediate step towards finding the optimal policy. It helps us rephrase the problem in terms of something that is easier to understand and learn.

Stochastic Policies
But if our ultimate goal is to find that optimal policy, do we really need this value function? Can we directly estimate the optimal policy? What would such a policy look like?
If we go with a deterministic approach, then the policy simply needs to be a mapping or function from states to actions. And in the stochastic case, this would be the conditional probability of each action given a certain state.

We would then choose an action based on this probability distribution. This is simpler in the sense that we are directly getting to the problem at hand, but it also avoids having to store a bunch of additional data that may or may not always be useful.
For example, large portions of the state space may have the same value. Formulating the policy in this manner allows us to make such generalizations where possible and focus more the complicated regions of the state space.
One of the main advantages of policy-based methods over value-based methods is that they can learn true stochastic policies. This is like picking a random number from a special kind of machine. One where the chances of each number being selected depends on some state variables that can be changed.
In contrast, when we apply epsilon-greedy action selection to a value function, that does add some randomness, but it's a hack. Flip a coin, if it's heads follow a deterministic policy, hence pick an action at random. The underlying value function can still drive us towards certain actions more than others. Let's see how this can be problematic.
Say you're learning to play rock paper scissors. Your opponent reveals their move at the same time as you. So you can't really use that to decide what to pick. In fact, it turns out that the optimal policy here is to choose an action uniformly at random. Anything else, like a deterministic policy or even a stochastic policy with some non-uniformity can be exploited by the opponent.
Aliased States:
Another situation where the stochastic policy helps is when we have aliased states, that is, two or more states that we perceive to be identical but are actually different. In this sense, their environment is partially observable, but such situations can arise more often than you think. Consider this grid world for instance, which consists of smooth white and rough gray cells, and there is banana in the bottom middle cell and a chili each in the bottom left and right corners. Obviously, agent George needs to find a reliable policy to get to the banana and avoid landing on the chilies no matter what cell he starts in.

But here's is the catch, all he can sense is whether the current cell is smooth or rough and whether it has a wall on each side. Think of these as the only observations or features that are available from the environment. He can't sense anything about neighboring cells either.
When George is in the top middle cell, he can sense it's smooth and only has a single wall to the north. So, he can relialbly take a step downwards and reach the banana. When he is in either of the top left or right cells, he can sense the side walls, so, he can recognize which of the two extreme cells he is in and can learn to reliably step away from the chilies and toward the center.
The trouble is, when he's in one the rough gray cells, he can't tell which one he's in. All the features are identical. If he's using a value function representation, then the value of these cells is equal, since they both map to the same state and the corresponding best action must also be identical. So, depending on his experiences, George might learn to either go right or left from both these cells, resulting in an overall policy like the picture below, whic is fine, expect for that orange region. George will keep oscillating between these two cells and never get out.
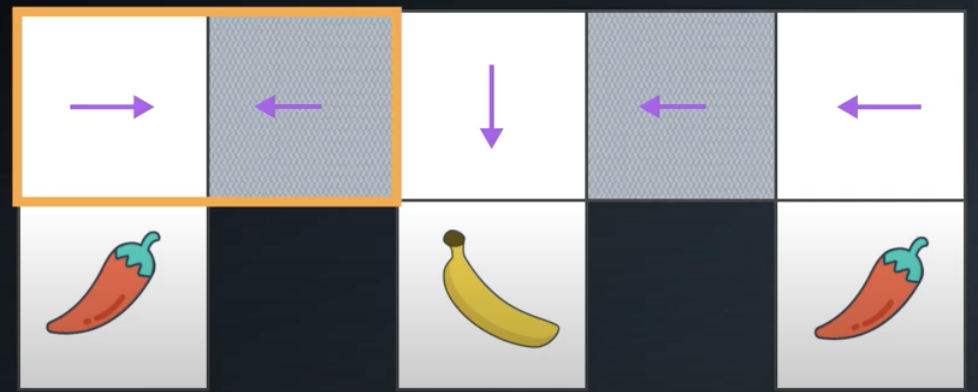
With a small epsilon-greedy policy, George might be able to come out by chance, but that's very inefficient and could take indefinitely long. And if he kept a high epsilon, that might result in bad actions in other states.
We can clearly see that the other value-based policy would not be ideal either.
The best he can do is to assign equal probability to moving left or right from these aliased states. He's much more likely to get out of the traps soon.
A value-based approach tends to learn a deterministic or near deterministic policy, whereas a policy-based approach in this situation can learn the desired stochastic policy.
Continuous Action Spaces
Our final reason for exploring policy-based methods, is that they are well-suited for continuous action spaces.
When we use a value-based method even with a function approximator, our output consists of a value for each action. Now, if the action space is discrete, and there are a finite number of actions, we can easily pick the action with the maximum value.
But, if the action space is continuous, then this max operation turns into an optimization problem itself.
It's like trying to find a global maximum of a continuous function which is non-trivial, especially if the function is not convex.
A similar issue exists in higher dimensional action spaces, lots of possible actions to evaluate. It would be nice if we could map a given state to an action directly. Even if the resulting policy is a bit more complex, it would significantly reduce the computation time needed to act, and that's something a policy-based method can enable.
See the video here.
Summary
Policy-Based Methods
- With value-based methods, the agent uses its experience with the environment to maintain an estimate of the optimal action-value function. The optimal policy is then obtained from the optimal action-value function estimate.
- Policy-based methods directly learn the optimal policy, without having to maintain a separate value function estimate.
Policy Function Approximation
- In deep reinforcement learning, it is common to represent the policy with a neural network.
- This network takes the environment state as input.
- If the environment has discrete actions, the output layer has a node for each possible action and contains the probability that the agent should select each possible action.
- The weights in this neural network are initially set to random values. Then, the agent updates the weights as it interacts with (and learns more about) the environment.
More on the Policy
- Policy-based methods can learn either stochastic or deterministic policies, and they can be used to solve environments with either finite or continuous action spaces.
Hill Climbing
- Hill climbing is an iterative algorithm that can be used to find the weights
- At each iteration,
- We slightly perturb the values of the current best estimate for the weights
- We slightly perturb the values of the current best estimate for the weights
- These new weights are then used to collect an episode. If the new weights
Beyond Hill Climbing
- Steepest ascent hill climbing is a variation of hill climbing that chooses a small number of neighboring policies at each iteration and chooses the best among them.
- Simulated annealing uses a pre-defined schedule to control how the policy space is explored, and gradually reduces the search radius as we get closer to the optimal solution.
- Adaptive noise scaling decreases the search radius with each iteration when a new best policy is found, and otherwise increases the search radius.
More Black-Box Optimization
- The cross-entropy method iteratively suggests a small number of neighboring policies, and uses a small percentage of the best performing policies to calculate a new estimate.
- The evolution strategies technique considers the return corresponding to each candidate policy. The policy estimate at the next iteration is a weighted sum of all of the candidate policies, where policies that got higher return are given higher weight.
Why Policy-Based Methods?
- There are three reasons why we consider policy-based methods:
- Simplicity: Policy-based methods directly get to the problem at hand (estimating the optimal policy), without having to store a bunch of additional data (i.e., the action values) that may not be useful.
- Stochastic policies: Unlike value-based methods, policy-based methods can learn true stochastic policies.
- Continuous action spaces: Policy-based methods are well-suited for continuous action spaces.