Motivation
Actor-Critic methods are at the intersection of value-based methods such as DQN and policy-based methods such as REINFORCE.
If a deep RL agent uses a deep neural network to approximate a value function, the agent is said to be value-based. If an agent uses a deep neural network to approximate a policy, the agent is said to be policy-based.
The DQN agent you learned about, is a value-based agent because it learns about the optimal action value function. This is just one of the many functions you can approximate. You can learn about the state value function V_{\pi}, the action value function Q_{\pi}, the advantage function A_{\pi}, and the optimal versions of these. If your agent learns a value function well, deriving a good policy from it is straight forward.
The REINFORCE agent previously learned about is a policy-based agent. These agents parametrizes the policy and learns to optimize it directly. The policy is usually stoachastic in this setting. But you can also learn about deterministic policies.
Remember that stochastic policies, taking a state and returned a probability distribution over the actions. Though what you often see is slightly different notation, in which you taking a state and an action and return the probability of taking that action in that state. But, they're pretty much the same though. Given the same state, the policy could prescribe a different action. This policy is stochastic.
Deterministic policies on the other hand, prescribe a single action for any given state. So, they take in a state and return an action. There's no stochasticity. The policy is deterministic.
Finally, you also learned about using baselines to reduce the variance of policy-based agents. Did you notice that you can use a value function as a baseline?
So, think about it. If we train a neural network to approximate a value function and then use it as a baseline, would this make for a better baseline? And if so, would a better baseline further reduce the variance of policy-based methods?
Indeed. **In fact, that's basically all actor-critic methods are trying to do, to use value-based techniques to further reduce the variance of policy-based methods.
See the video here.
Bias vs. Variance
In machine learning, we're often presented there with a tradeoof between bias and variance. Let's talk about some intuition first.
Let's say you're practicing your soccer shooting skills. The thing you want to do is to put the ball in the top right corner of the goal. You want to be able to repeatedly kicked the ball there. If after a day of training, you place the ball most of the time in the middle right, this means that you have a bias to shoot the ball lower. If also means that you have low variance because the shots where clumped together. Now, say the average of your shots were center on the top right corner, but most of your shots were spread around that spot. Then, you have low bias because you were mostly center where you were aiming in high variance because of the spread.
Obviously, you want to avoid both high bias and high variance, and you want to have both low bias and low variance. The thing is, this is very hard to achieve, but we'll look at several techniques that are designed to accomplish this.
We have to consider the bias-variance tradeoff in RL, when an agent tries to estimate value functions or policies from returns.
A return is calculated using a single trajectory. However, value functions which is what we're trying to estimate are calculated using the expectation of returns.
A big part of the effort in RL and research is an attempt to reduce the variance of algorithms while keeping bias to a minimum.
You know by now that a RL agent tries to find policies to maximize the total expected reward. But since we're limited to sampling the environment, we can only estimate these expectation. The question is, what's the best way to estimate value functions for our actor-critic methods.
See the video here.
Two Ways For Estimating Expected Returns
Let's explore two very distinct and complimentary ways for estimating expected returns. On the one hand, you'd have the Monte-Carlo estimate.
The Monte-Carlo estimate consists of rolling out an episode in calculating the discounted total reward from the rewards sequence. For example, in an episode A, you state in state S_t, take action A_t. The environment then transitions and gives you a reward R_{t+1} and sends you to a new state S_{t+1}. Then, you continue with a new action A_{t+1} and so on until you reach the end of the episode.
The Monte-Carlo estimate just adds all the rewards up, whether discounted or not. When you then have a collection of episodes A, B, C, and D, some of those episodes will have trajectories that go through the same states. Each of these states episodes can give you a different Monte-Carlo estimate for the same value function.
To calculate the value function, all you need to do is average the estimates.
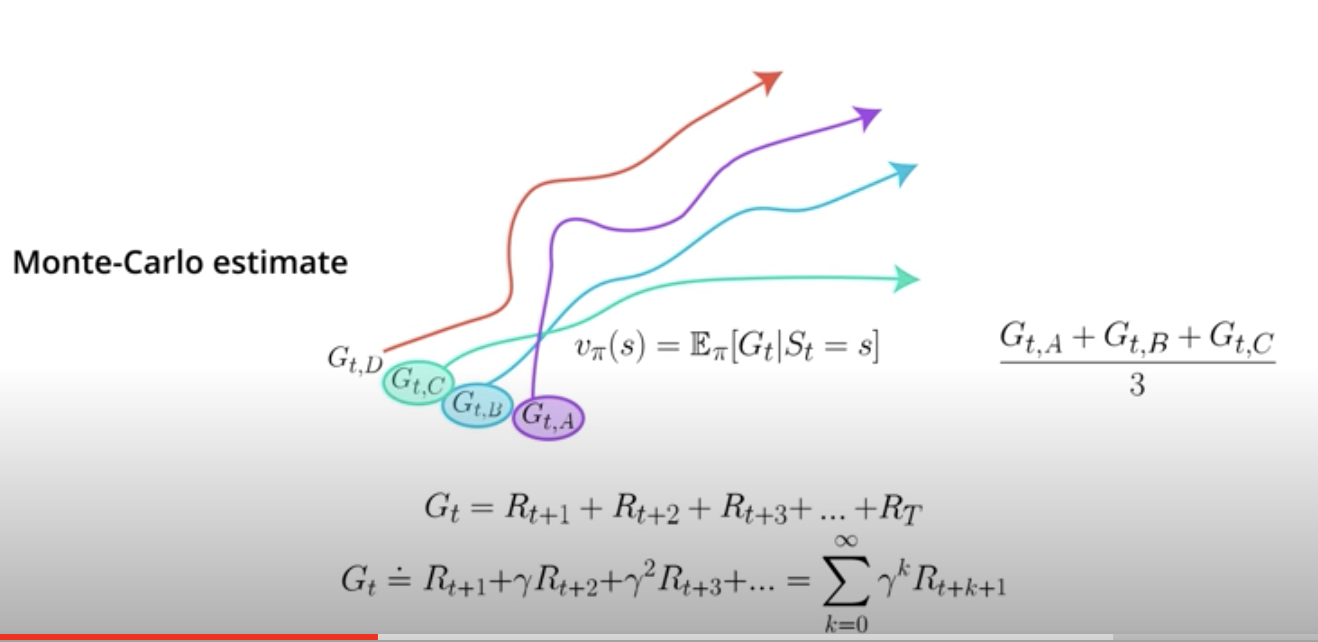
Obviously, the more estimates you have when taking the average, the better your value function will be.
On the other hand, you have the temporal difference or TD estimate. Say, we're estimating a state value function V. For estimating the value of the current state, it uses a single reward sample. In an estimate of the discounted total return, the agent will obtain from the next state onwards. So, you're estimating with an estimate.
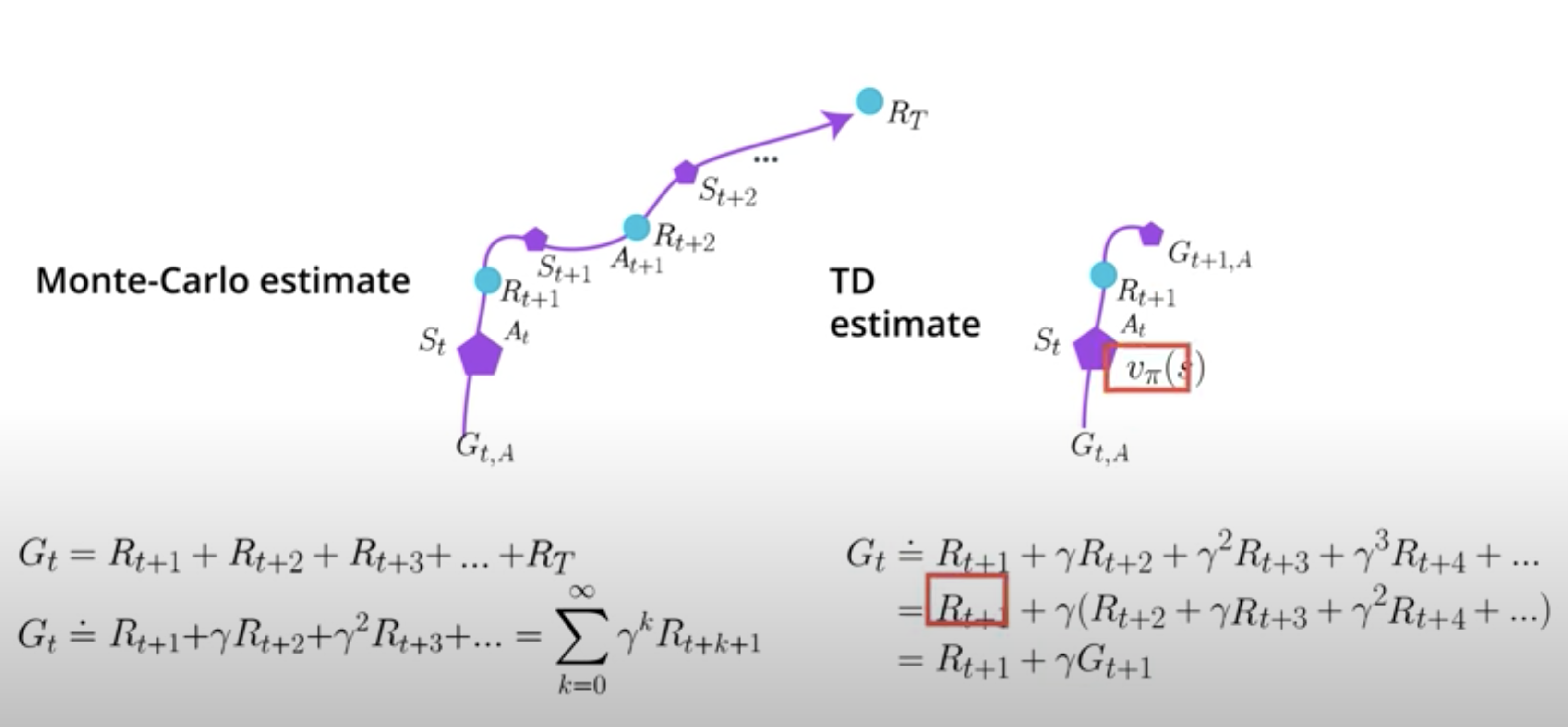
For example, in episode A, you start in state S_t, take action A_t, the environment then transitions and gives you a reward R_{t+1}, and sends you to a new state S_{t+1}. But, then you can actually stop there. By the magic of dynamic programming, you're allowed to do what is called bootstrapping, which basically means that you can leverage the esimtate you're currently have for for the next state in order to calculate a new estimate for the value function of the current state.
Now, the estimates of the next state will probably be off, particularly early on, but that value will become better and better as your agenct sees more data, making it turn other values better, clever right?
After doing this many many times, you will have estimated desired value function well. As you can imagine, Monte-Carlo estimates will have high variance because estimates for a state can vary greatly across episodes. G_{t,A} here could be -100, while G_{t,B} could be +100, and G_{t,C} could be +1000.
The reason these high variance is likely, is because you are compounding lots of random events that happened during the course of a single episode. But Monte-Carlo methods are unbiased. You are not estimating using estimates. You're only using the true rewards you obtained. So, given lots and lots of data, your estimates will be accurate.
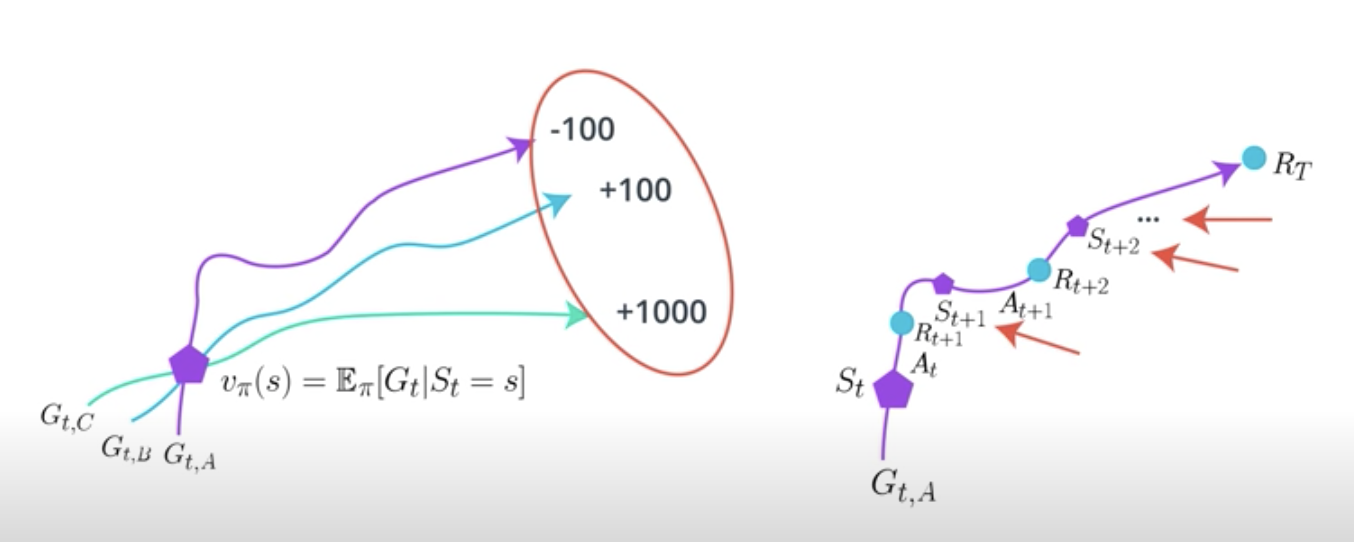
TD estimates are low variance because you're only compounding a single time step of randomness instead of a full rollout. Though because you're bootstrapping on the next state estimates and those are not true values, you're adding bias into your calculations. Your agent will learn faster, but we'll have more problem converging.
See the video here.
Baselines and Critics
You now know that the Monte-Carlo estimate is unbiased but has high variance, and that the TD estimate has low variance but it is biased.
What are these facts good for?
We you studies REINFORCE, you learned that the return G was calculated as the total discounted return. This way of calculating G, which is simply a Monte-Carlo estimate, has high variance. You then use a baseline to reduce the variance of the REINFORCE algorithm. However, this baseline was also calculated using a Monte-Carlo approach.
Let's now assume you use deep learning to learn this baseline. Even if you still use the Monte-Carlo approach which has high variance, using function approximation still gives you an advantage. Namely, you now gain the power of generalization. That means when you encounter a new state S', whether you had visitor or not, your deep neural network will potentially come up with better estimates, since it's been trained to generalize from similar data.
Note that at this point, we're still not using a critic even though we are using function approximation. This might be confusing as the literature is often not consistent. They recall a Monte-Carlo estimate has high variance and no bias, and that the TD esimtate has low variance but is biased.
Now, the word critic implies that bias has been introduced and the Monte-Carlo estimate is unbiased. If instead of using Monte-Carlo estimates to train baselines, we used TD estimates, then we can say we have a critic.
Sure, we will be introducing bias but we will be reducing variance thus improving our convergence properties and speeding up learning.
In actor-critic methods, all we are trying to do is to continue to reduce the high-variance commonly associated with policy-based agents. By using a TD critic instead of a Monte-Carlo baseline, we further reduce the variance of policy-based methods. This leads to faster learning than policy-based agents alone and we also see better and more consistent convergence than value-based agents alone.
See the video here.
The argument you often hear as to why to call a neural network trained with Monte-Carlo estimates a "Critic" is because function approximators, such as a neural network, are biased as a byproduct that they are not perfect. That's a fair point, though, I prefer the distinction based on whether we pick a Monte-Carlo or a TD estimate to train our function approximator. Now, definitely we should not be calling Actor-Critic methods every method that uses 2 neural networks. You'll be surprised!
The important takeaway for you, though, is that there are inconsistencies out there. You often see methods named "Actor-Critic" when they are not. I just want to bring the issue to your attention.
Policy-based, Value-based and Actor-Critic
Now that you have some foundational concepts down, let's talk about some intuition.
Let's say you want to get better at tennis. The actor or policy-based approach you roughly learns this way. You play a bunch of matches. You then go home, lay on the couch, and commit to yourself to do more of what you did in matches you won, and less of what you did in matches you lost. After many many times repeating this process, you will have increased the probability of actions that led to a win, and decreased the probability of actions that led to losses.
But you can see how these approaches are rather inefficient as it needs lots of data to learn a useful policy. Many of the actions that occur within the game that ended up in a loss could have been really good actions. So, decreasing the probability of good actions taking in a match only because you lost is not the best idea.
Sure, if you repeat this process infinitely, you're likely to end up with a good policy, but at the cost of slow learning.
It is clear that policy-based agents have high variance. The critic or value-based approach learns differently.
You start playing a match, and even before you get started, you start guessing what the final score is going to be like. You continue to make guesses throughout the match. At first, your guesses will be off. But as you get more and more experience, you will be able to make pretty solid guesses. The better your guesses, the better you'll tell good from bad actions. The better you can make these distinctions, the better you'll perform. Of course, given that you select good actions.
Though this is not a perfect approach either, guesses introduce a bias because they'll sometimes be wrong, particularly because of a lack of experience. Guesses are prone to under or overestimation. Though, guesses are more consistent through time. If you think you'll win a match five minutes into it, chances are you'll still think so 10 minutes into it. This is what makes the TD estimate have lower variance.
As you can see, in a policy-based approach, the agent is learning to act, and it is good at that. Whereas in a value-based approach, the agent is learning to estimate situations and actions, and it's pretty good at that. Combining these two approaches sounds like a great idea, and it often yields better results.
Actor-critic agents learn by playing games and adjusting the probabilities of good and bad actions just as with the actor alone. But this time, you'll also use a critic to be able to tell good from bad actions more quickly, and speed up learning.
In the end, actor-critic agents are moer stable than value-based agents, and need fewer samples than policy-based agents.
See the video here.
A Basic Actor-Critic Agent
You know now that an actor-critic agent is an agent that uses function approximation to learn a policy any value function. So, we will then use two neural networks; One for the actor and one for the critic.
The critic will learn to evaluate the state value function V_{\pi} using TD estimate. Using the critic, we will calculate the advantage function and train the actor using this value. A very basic online actor-critic agent is as follows:
You have two networks. One network, the actor, takes in a state and outputs the distribution over actions. The other network, the critic takes in a state and outputs a state value function of policy \pi, V({\pi}).
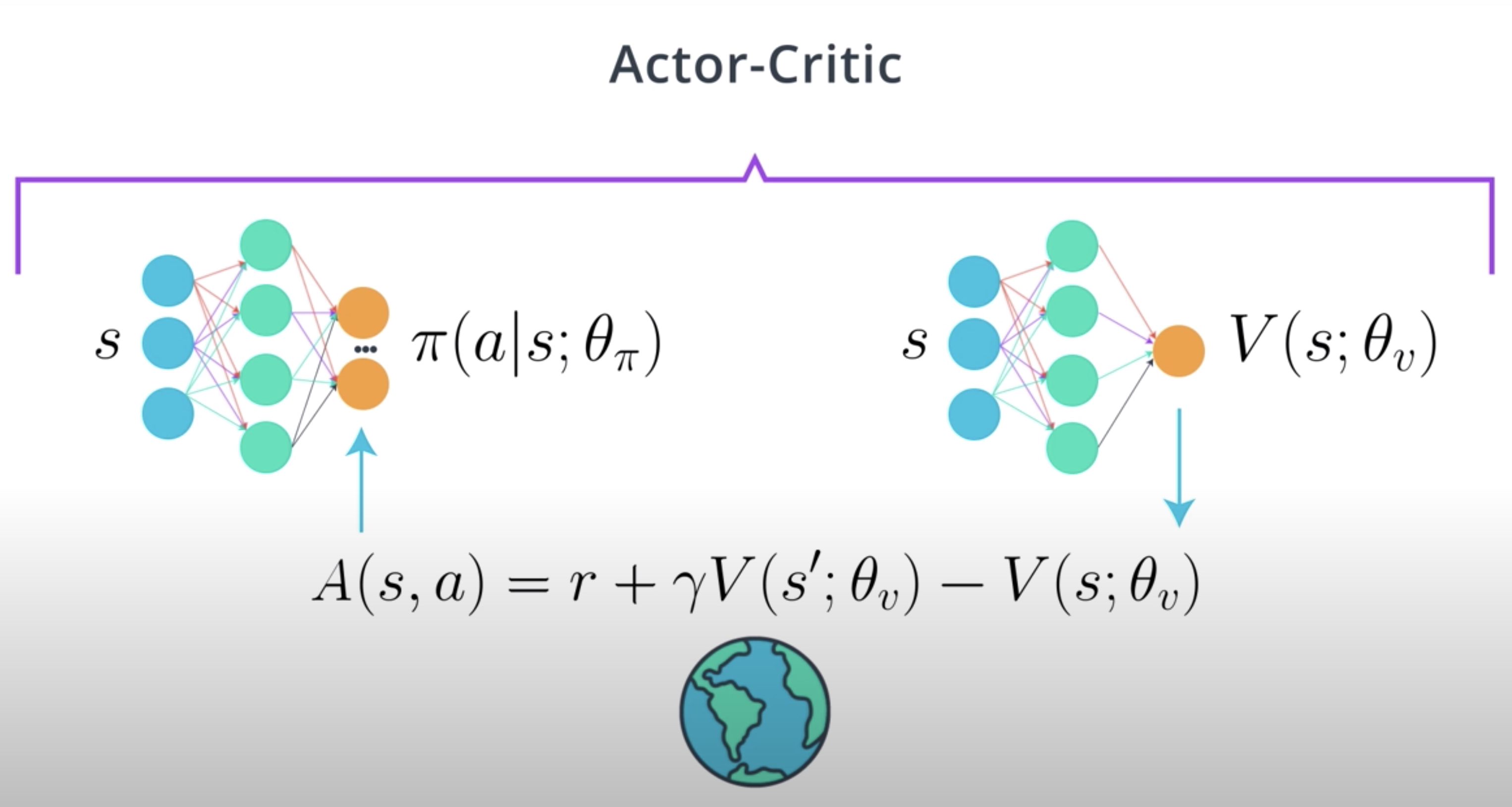
The algorithm goes like this.
Input the current state into the actor and get the action to take in that state. Onserve next state and reward to get your experience tuple (s,a,r,s').
Then, using the TD estimate which is the reward r plus the critic's estimate for s'. So, r + \gamma V(s';\theta_v). You train the critic.
Next, to calculate the advantage A_{\pi}(s,a) (equation in the picture above). We also use the critic.
Finally, we train the actor using the calculated advantage as a baseline. We'll focus on few of the most popular actor-critic agents in the next sections.
See the video here.

A3C: Asynchronous Advantage Actor-Critic, N-step Bootstrapping
A3C stands for Asynchronous Advantage Actor-Critic. As you can probably infer from the name, we'll be calculating the advantage function, A_{\pi}(s,a), and the critic will be learning to estimate V_{\pi} to help with that just as before.
If you're using images as inputs to your agent, A3C can use a single convolutional neural network with the actor and critic sharing weights, in two separate heads, one for the actor, and one for the critic.
Note that A3C does not have to be used exclusively with CNN's and images. But if you were to use it, sharing weights to some more efficient, more complex approach, and can be harder to train.
It's a good idea to start with two separate networks, and change it only to improve performance.
Now, one interesting aspect of A3C, is that instead of using a TD estimate, it will use another estimate commonly referred to as N-step bootstrapping.
N-step bootstrapping is simply an abstraction and a generalization of a TD and Monte-Carlo estimates.
TD is a one-step bootstrapping. Your agent goes out and experiences one-time-step of real rewards, and then bootstraps right there.
Monte-Carlo goes out all the way, and it does not bootstrap because it doesn't need to. Monte-Carlo estimate is an infinite step bootstrapping.
But, how about going more than one step, but not all the way out?
This is called _n-step bootstrapping, and A3C uses this kind of return to train the critic.
For example, in our tennis example, n-step bootstrapping means that you will wait a little bit before guessing what the final score will look like. Waiting to experience the environment for a little longer before you calcualte the expected return of the original state, allows you to have less bias in your prediction, keeping variance under control.
In practice, only a few steps out, say 4- or 5-step bootstrapping, are often the best.
By using n-step bootstrapping, A3C propagates values to the last end states visited, which allows for faster convergence with less experience required while still keeping variance under control.
See the video here.
A3C: Asynchronous Advantage Actor-Critic, Parallel Training
Unlike in DQN, A3C does not use a replay buffer. The main reason we needed a replay buffer was so that we could de-correlate experience tuple.
In RL, an agent collects experience in a squential manner. The experience collected at time step t+1 will be correlated to the experience collected at time step t because it is the action taken at time step t that is partially responsible for the reward and the state observed at time step t+1, and that state will influence all our future decisions. There's no way out of that.
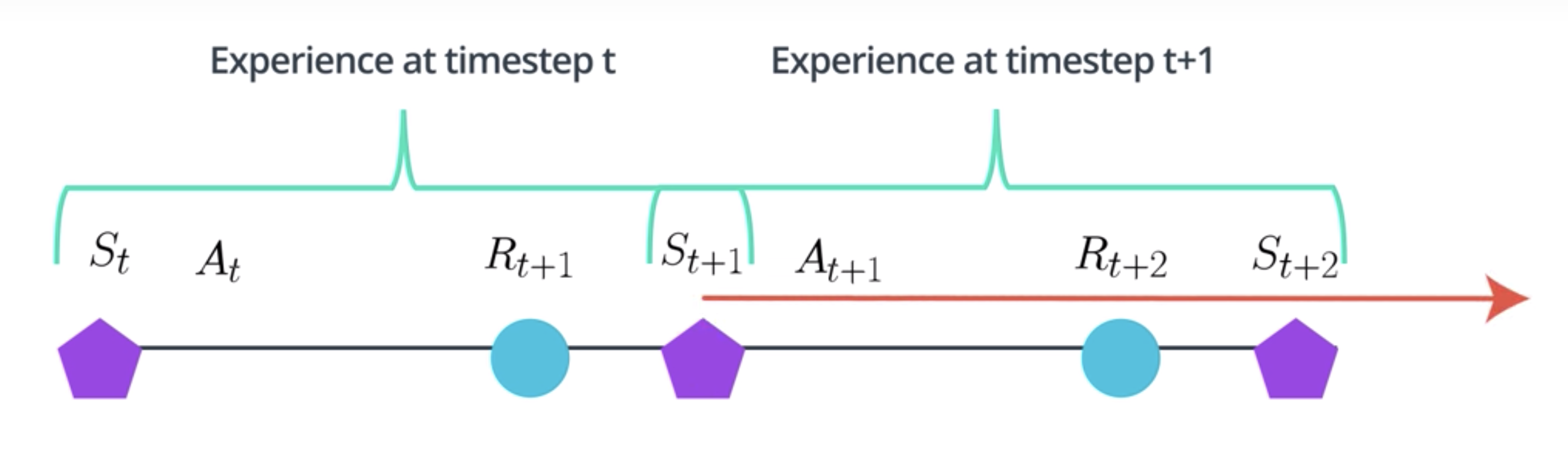
The replay buffer allows us to collect these experiences sequentially by adding them one at a time to the replay buffer for later processing.
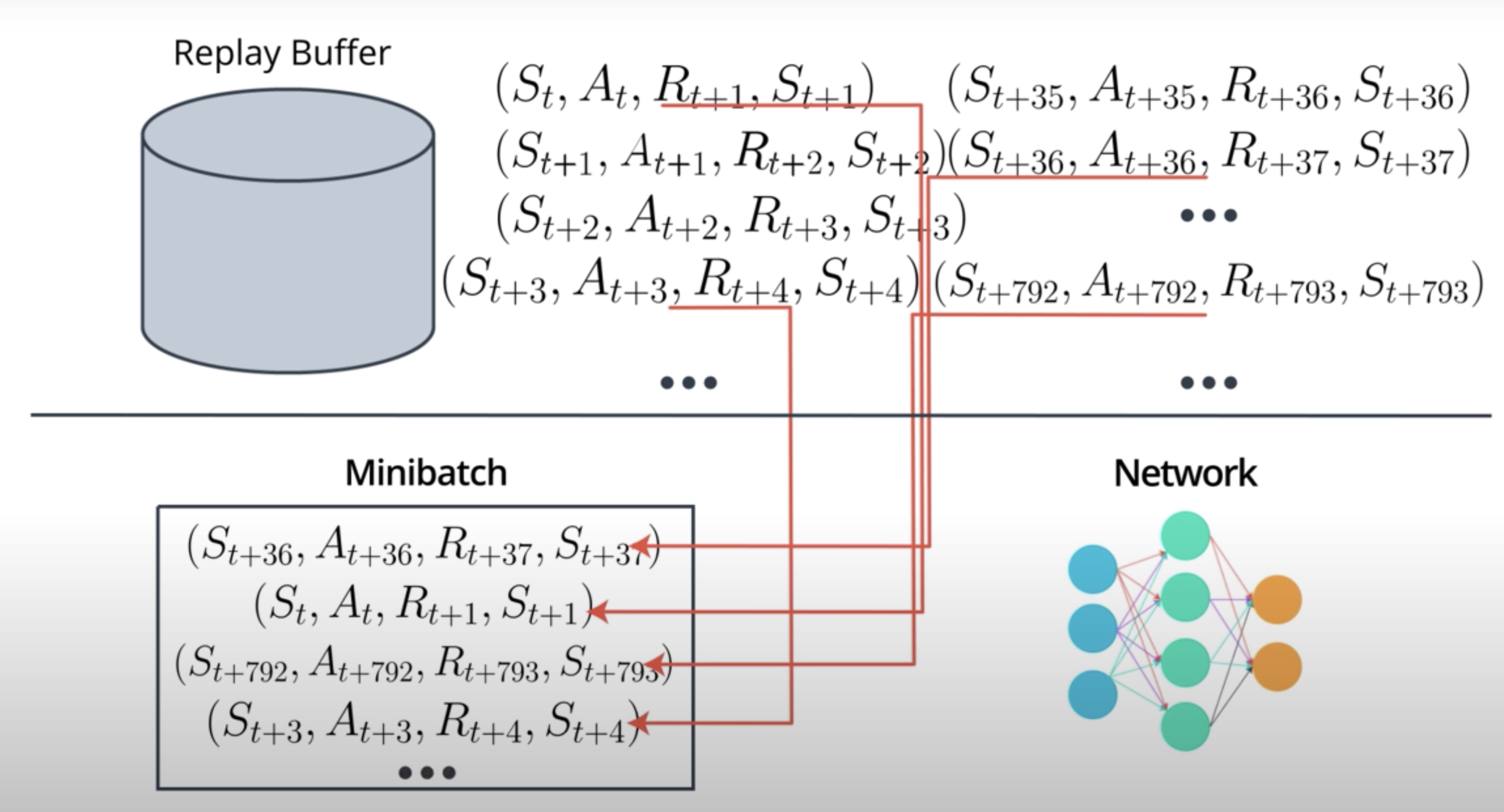
So, independent from the data collection process, we can randomly select experiences from the replay buffer into mini batches.
The experiences in the mini batches will not show the same correlation. This allows us to train our network successfully.
Interestingly, A3C replaces the replay buffer with parallel training. By creating multiple instances of the environment and agent and running them all at the same time, your agent will receive mini batches of the correlated experiences just as we need.
Samples will be de-correlated because agents will likely be experiencing different states at any given time.
On top of that, this way of training allows us to use on-policy learning in our learning algorithm, which is often associated with more stable learning.
See the video here.
A3C: Asynchronous Advantage Actor-Critic, Off-policy vs. On-policy
In case you're not clear on what on-policy vs. off-policy learning is, let's review it here.
On-policy learning is when the policy used for interacting with the environment is also the policy being learned.
Off-policy learning is when the policy used for interacting with the environment is different than the policy being learned.
Sarsa is a good example of an on-policy learning agent. A Sarsa agent uses the same policy to interact with the environment as the policy it is learning. On the other hand, Q-learning is a good example of a off-policy learning agent. A Q-learning agent learns about the optimal policy, though the policy that generates behavior is an exploratory policy, often epsilon-greedy.
Looking at the update equations for these two methods, helps us understand them better.
As you can see below, in Sarsa the action used for calculating the TD target and the TD error is the action the agent will take in the following time step, A'. In Q-learning, however, the action used for calculating the target is the action with the highest value. But this action is not guaranteed to be used by the agent for interaction with the environment in the following time step. In other words, this is not necessarily A'. The Q-learning agent choose an exploratory action the next step. In Sarsa that action, exploratory or not, is already been chosen.
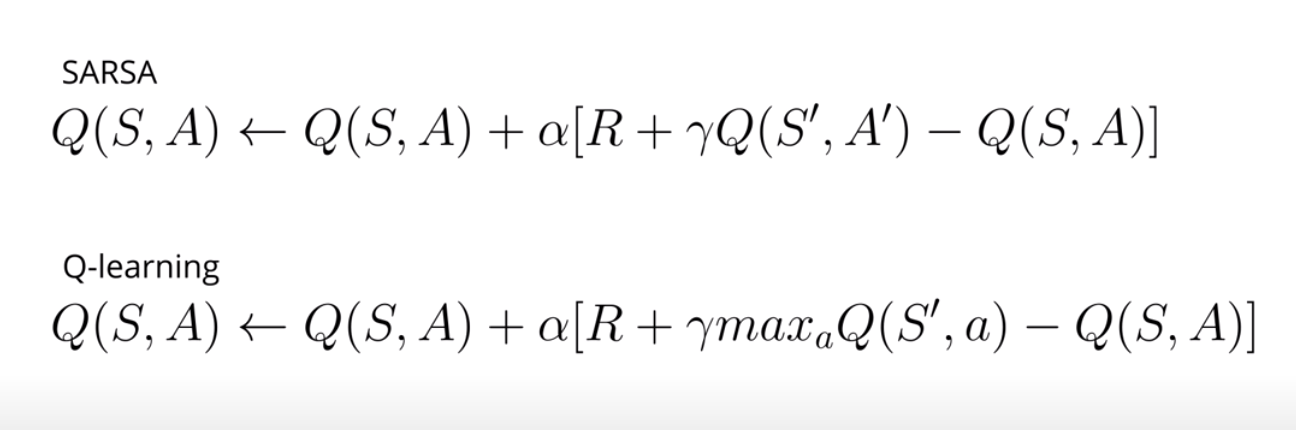
Q-learning learns a deterministic optimal policy even if its behavior policy is totally random. Sarsa learns the best exploratory policy, that is the best policy that still explores.
DQN is also an off-policy learning method. Your agent behaves with some exploratory policy, say epsilon-greedy, where it learns about the optimal policy.
When using off-policy learning, agents are able to learn from many different sources including experiences generated by all versions of the agent itself, thus the replay buffer. However, off-policy learning is known to be unstable and often diverge with deep neural networks.
A3C on the other hand is an on-policy learning method. With on-policy learning, you only use the data generated by the policy currently being learned about, and anytime you imrpove the policy, you toss out old data and go out collect some more.
On-policy learning is a bit inefficient in the use of experiences, but it often has more stable and consistent convergence properties.
A simple analogy of on- and off-policy goes this way. On-policy is learning from your own hands-on experience. For example, the projects in this Nano-degree. As you can imagine that is a pretty good way of learning, but it is somewhat data inefficient, you can only do so many projects before you run out of time.
Off-policy on the other hand, is learning from someone else's experience and as such it is more sample efficient because you can learn from many different sources. However, this way of learning is more prone to misunderstandings. I might not be able to explain things in a way that you understand well. The Nano-degree analogy in the off-policy case is learning from watching the lessons for example. You learn much faster this way but again, perhaps not as good as you would from your own hands-on experience.
Usually a good balance between these two ways of learning allows for the best performing deep RL agents and perhaps the best performing humans too, maybe?!
Now, if you want to learn more about agents who combine on- and off-policy learning, you can read the paper titled "Q-Prop: Sample-Efficient Policy Gradient with An Off-Policy Critic" linked here.
See the video here.
A2C: Advantage Actor-Critic
You may be wondering what the asynchronous part in A3C is about?
A3C accumulates gradient updates and applies those updates asynchronously to a global neural network. Each agent in simulation does this at its own time. So, the agents use a local copy of the network to collect experience, calculate, and accumulate gradient updates across multiple time steps, and then they apply these gradients to a global network asynchronously.
Asynchronous here means that each agent will update the network on its own. There is no synchronization between the agents. This also means that the weights an agent is using might be different from the weights in use by another agent at any given time.
There is a synchronous implementation of A3C called Advantage Actor-Critic or A2C. A2C has some extra bit of code that synchronizes all agents. It waits for all agents to finish a segment of interaction with its copy of the environment, and then updates the network at once, before sending the updated weights back to all agents.
A2C is arguably simpler to implement, yet it gives pretty much the same result, and allegedly in some cases performs even better.
A3C is most easily train on a CPU, while A2C is more straightforward to extend to a GPU implementation.
See the video here.
A2C Code Walk-through
Check out the codes from Shangtong Zhang for an implementation in his GitHub page.
For a walk-through of the A2C code, watch this video.
NOTE: Zhang has also implemented all the Sutton's book codes in Python (I believe the original codes are in LISP). Check out his Github repo for those codes.
GAE: Generalized Advantage Estimation
There is another way for estimating expected returns called the lambda return. The intuition goes this way.
Say after you try n-step bootstrapping you realize that numbers of n larger than 1 often perform better. But it's still hard to tell what that number should be. To make the decision even more difficult, in some problems small numbers of n are better while in others large number of n are better. How do you get this right?
The idea of lambda return is to create a mixture of all n-step bootstrapping estimates at once. Lambda is hyperparameter used for weighting the combination of each n-step estimate to the lambda return. The weights depends on the value you set for lambda and it decays exponentially at the rate of that value.
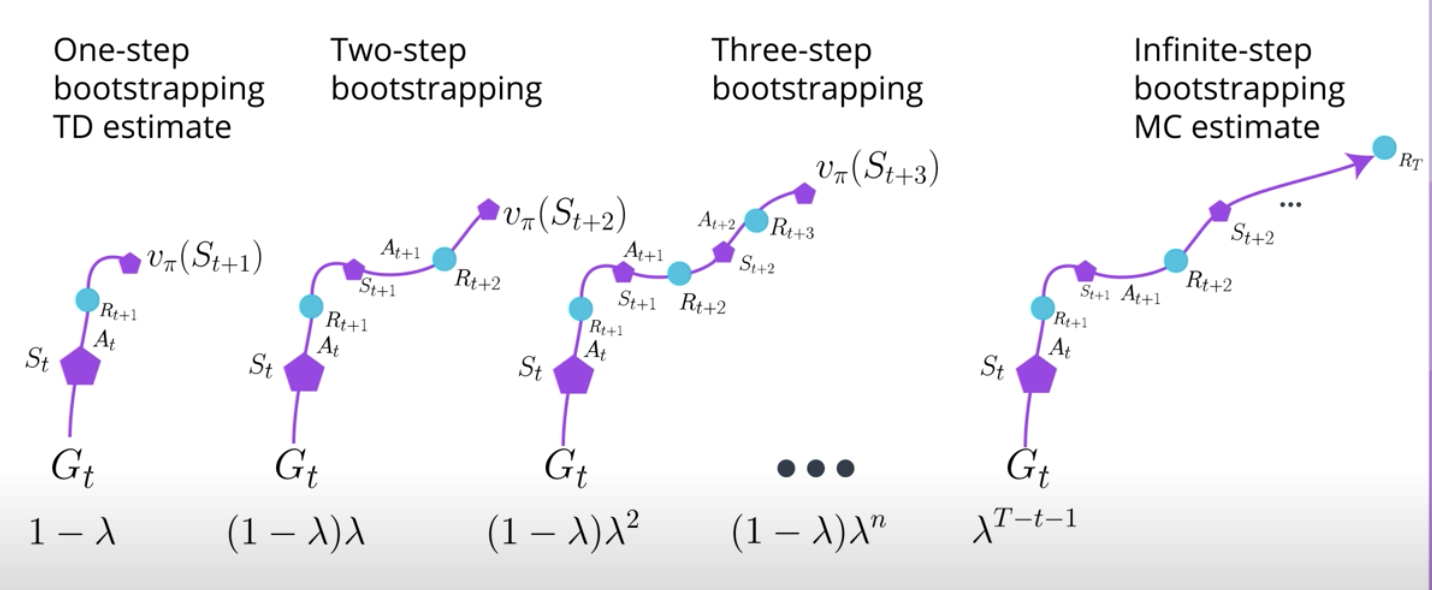
So, for calculating the lambda return for state S at time step t, we would use all n-step returns and multiply each of the n-step return by the corresponding weight. Then add them all up. Remember, that sum will be the lambda return for state S at time step t.
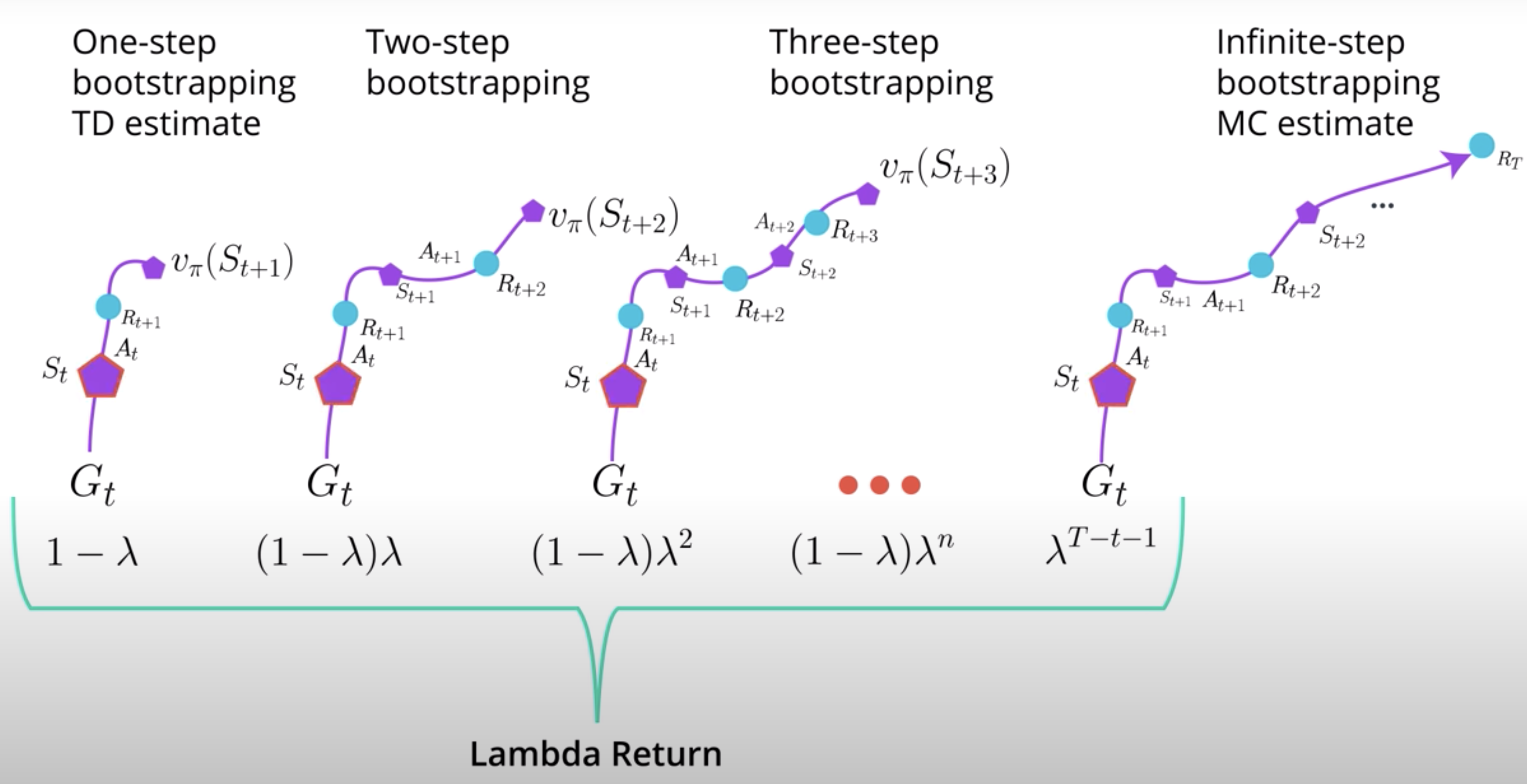
Interestingly, when lambda is set to 0, the 2-step, 3-step, and all n-step return other than the 1-step return, will be equal to zero. So, the lambda return when the lambda is set to zero will be equivalent to the TD estimate. If your lambda is set to one, all n-step return other than the infinite step return will be equal to zero. So, the lambda return when lambda is set to one, will be equivalent to the Monte-Carlo estimate.
Again, a number between 0 and 1 gives a mixture of all n-step bootstrapping estimate. But, isn't this amazing that a single algorithm can do that?
GAE is a way to train the critic with this lambda return. You can fit the advantage function just like in A3C and A2C or using a mixture of n-step bootstrapping estimates.
It's important to highlight that this type of return can be combined with virtually any policy-based method. In fact, in the paper that introduced GAE, TRPO was the policy-based method used. By using this type of estimation, this algorithm, TRPO + GAE trains very quickly because multiple value functions are spread on every time step due to the lambda return start estimate. Here is the link to the paper
See the video here.
DDPG: Deep Deterministic Policy Gradient, Continuous Action-space
DDPG is a different kind of actor-critic method. In fact, it could be seen as kind of approximate DQN, instead of an actual actor critic. The reason for this is that the critic in DDPG is used to approximate the maximizer over the Q values of the next state, and not as a learned baseline. Though, this is still a very important algorithm and it is good to discuss it in more detail.
One of the limitations of the DQN agent is that it is not straightforward to use in continuous action spaces.
Imagine a DQN network that takes in a state and outputs the action value function. For example, for two actions, say "Up" and "Down", Q(s, "Up") gives you the estimated expected value for selecting the "Up" action in state s, similarly for the "Down" action. To find the max action value function for this state, you just calculate the max of these values (pretty easy!). It's very easy to do a max operation in this example because this is a discrete action space. Even if you had more actions, or if it was high dimensional with many, many more actions, it would still be doable. But, what if you need an action with continuous range? How do you get the value of a continuous action with this architecture? Say, you want the "Jump" action to be continuous, a variable between 1 and 100 centimeters. How do you find the value of jump? This is one of the problems DDPG solves.
In DDPG, we use two deep neural networks. We can call one the actor and the other the critic. Now, the actor here is used to approximate the optimal policy deterministically. That means we want to always output the best believed action for any given state. This is unlike a stochastic policies in which we want the policy to learn a probability distribution over the actions.
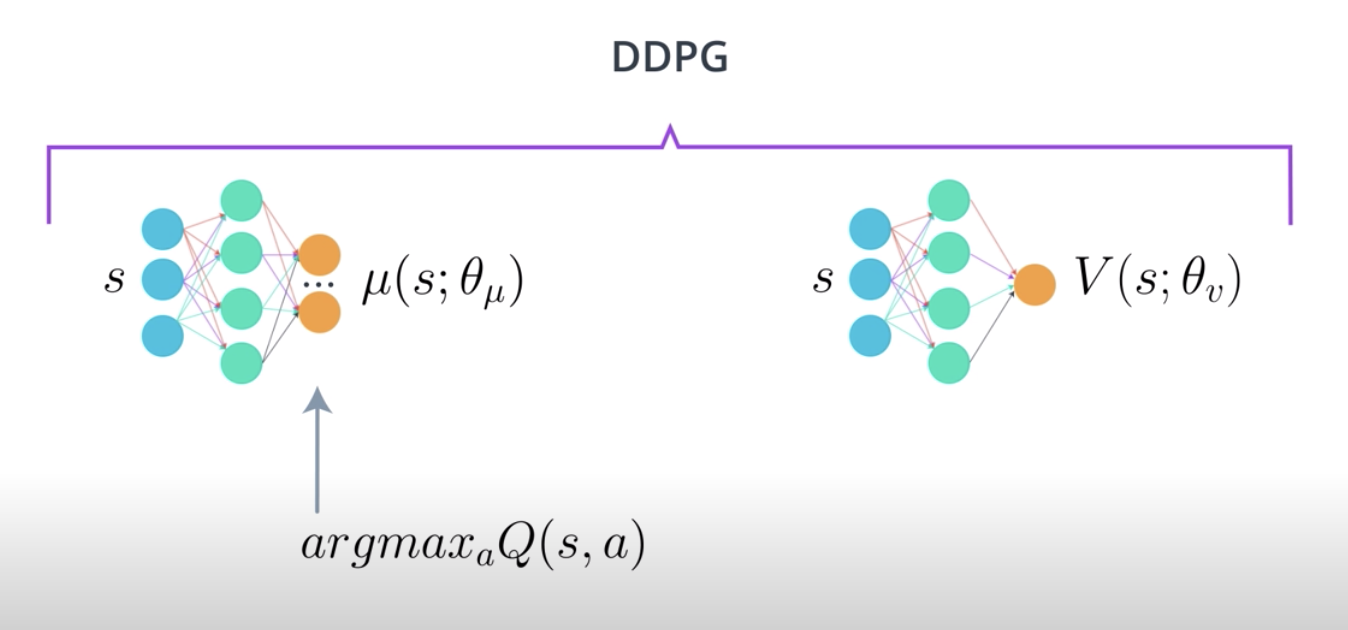
In DDPG, we want the believed best action every single time we query the actor network. That is a deterministic policy.
The actor is basically learning the argmax_{a}Q(s,a), which is the best action. The critic learns to evaluate the optimal action value function by using the actor's best believed action.
Agina, we use this actor, which is an approximate maximizer, to calculate a new target value for training the action value function, much in the way DQN does.
See the video here.
In the DDPG paper, they introduced this algorithm as an "Actor-Critic" method. Though, some researchers think DDPG is best classified as a DQN method for continuous action spaces (along with NAF). Regardless, DDPG is a very successful method and it's good for you to gain some intuition.
DDPG: Deep Deterministic Policy Gradient, Soft Updates
Two other interesting aspects of DDPG are:
- The use of a replay buffer,
- The soft updates to the target networks.
You already know how the replay buffer part works. But the soft updates are a bit different.
In DQN, you have two copies of your network weights, the regular and the target network. In the Atari paper in which DQN was introduced, the target network is updated every 10,000 time steps. You simply copy the weights of your regular network into your target network. That is the target network is fixed for 10,000 time steps and then it gets a big update.

In DDPG, you have two copies of your network weights for each network, a regular for the actor, a regular of the critic, a target for the actor, and a target for the critic. But in DDPG, the target networks are updated using a soft update strategy.
A soft update strategy consists of slowly blending your regular network weights with your target network weights. So, every time step you make your target network be 99.99% of your target network weights and only a 0.01% of your regular network weights. You slowly mix in your regular network weights into your target network weights.

Recall that the regualr network is the most up to date network because it's the one we're training, while the target network is the one we use for prediction to stabilize training.
In practice, you'll get faster convergence by using this update strategy, and in fact, this way for updating the target network weights can be used with other algorithms that use target networks including DQN.
See the video here.
DDPG Code Walkthrough
For the codes, again, refer to the Shangtong Zhang's GitHub repo.
See the walkthtough video here.