Introduction

Introduction
For this coding exercise, you will use OpenAI Gym's Taxi-v2 environment to design an algorithm to teach a taxi agent to navigate a small gridworld. The goal is to adapt all that you've learned in the previous lessons to solve a new environment!
Before proceeding, read the description of the environment in subsection 3.1 of this paper.
You can verify that the description in the paper matches the OpenAI Gym environment by peeking at the code here.
Instructions
Open the workspace in the next concept in a new window.

Open the workspace in a new window.
Next, open a terminal by clicking on NEW TERMINAL. You will notice some output as the environment is configured.
Open a new terminal.
The workspace contains three files:
agent.py: Develop your reinforcement learning agent here. This is the only file that you should modify.monitor.py: Theinteractfunction tests how well your agent learns from interaction with the environment.main.py: Run this file in the terminal to check the performance of your agent.
Open all three of these files in the workspace.
Open agent.py, Monitor.py, and main.py.
Next, run main.py by executing python main.py in the terminal.
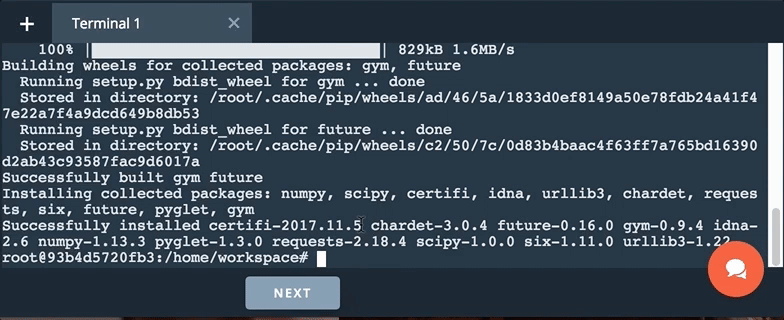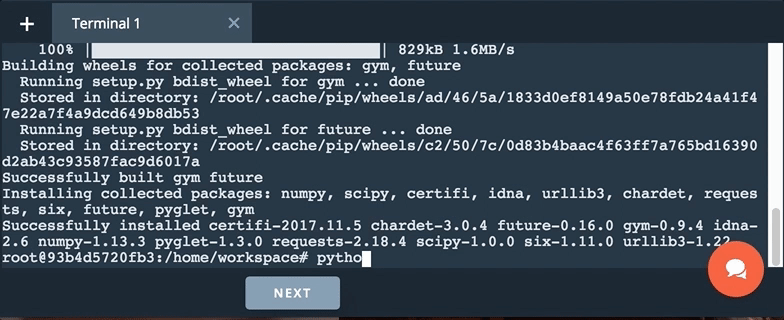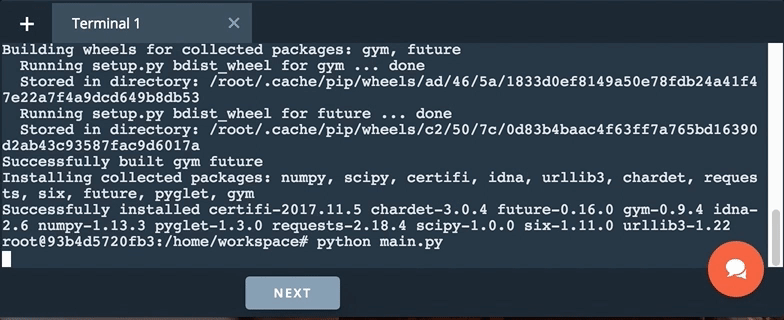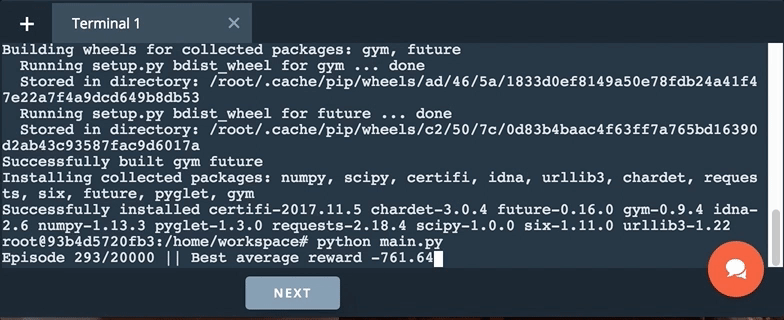
Run python main.py in the terminal.
When you run main.py, the agent that you specify in agent.py interacts with the environment for 20,000 episodes. The details of the interaction are specified in monitor.py, which returns two variables: avg_rewards and best_avg_reward.
avg_rewardsis a deque whereavg_rewards[i]is the average (undiscounted) return collected by the agent from episodesi+1to episodei+100, inclusive. So, for instance,avg_rewards[0]is the average return collected by the agent over the first 100 episodes.best_avg_rewardis the largest entry inavg_rewards. This is the final score that you should use when determining how well your agent performed in the task.
Your assignment is to modify the agents.py file to improve the agent's performance.
- Use the
__init__()method to define any needed instance variables. Currently, we define the number of actions available to the agent (nA) and initialize the action values (Q) to an empty dictionary of arrays. Feel free to add more instance variables; for example, you may find it useful to define the value of epsilon if the agent uses an epsilon-greedy policy for selecting actions. - The
select_action()method accepts the environment state as input and returns the agent's choice of action. The default code that we have provided randomly selects an action. - The
step()method accepts a (state,action,reward,next_state) tuple as input, along with thedonevariable, which isTrueif the episode has ended. The default code (which you should certainly change!) increments the action value of the previous state-action pair by 1. You should change this method to use the sampled tuple of experience to update the agent's knowledge of the problem.
Once you have modified the function, you need only run python main.py to test your new agent.
While you are welcome to implement any algorithm of your choosing, note that it is possible to achieve satisfactory performance using some of the approaches that we have covered in the lessons.
Evaluate your Performance
OpenAI Gym defines "solving" this task as getting average return of 9.7 over 100 consecutive trials.
While this coding exercise is ungraded, we recommend that you try to attain an average return of at least 9.1 over 100 consecutive trials (best_avg_reward > 9.1).
Not sure where to start?
Note that this exercise is intentionally open-ended, and we won't provide an official solution. For help with this exercise, please reach out to your instructors and fellow students! As a first step, you should figure out how to adapt your implementation in the Temporal-Difference Methods lesson to implement an agent to learn in this new environment. The code will likely be very similar to the notebook from the Temporal-Difference Methods lesson, where you need only modify very few things to fit this slightly different format.
Share your Results
If you arrive at an implementation that you are proud of, please share your results with the student community! You can also reach out to ask questions, get implementation hints, share ideas, or find collaborators!
As a final step, towards sharing your ideas with the wider RL community, you may like to create a write-up and submit it to the OpenAI Gym Leaderboard!
Mini Project
Copied the codes from the Udacity workspace.
# agent.py import numpy as np from collections import defaultdict class Agent: def __init__(self, nA=6): """ Initialize agent. Params ====== - nA: number of actions available to the agent """ self.nA = nA self.Q = defaultdict(lambda: np.zeros(self.nA)) def select_action(self, state): """ Given the state, select an action. Params ====== - state: the current state of the environment Returns ======= - action: an integer, compatible with the task's action space """ return np.random.choice(self.nA) def step(self, state, action, reward, next_state, done): """ Update the agent's knowledge, using the most recently sampled tuple. Params ====== - state: the previous state of the environment - action: the agent's previous choice of action - reward: last reward received - next_state: the current state of the environment - done: whether the episode is complete (True or False) """ self.Q[state][action] += 1
# main.py from agent import Agent from monitor import interact import gym import numpy as np env = gym.make('Taxi-v2') agent = Agent() avg_rewards, best_avg_reward = interact(env, agent)
# monitor.py from collections import deque import sys import math import numpy as np def interact(env, agent, num_episodes=20000, window=100): """ Monitor agent's performance. Params ====== - env: instance of OpenAI Gym's Taxi-v1 environment - agent: instance of class Agent (see Agent.py for details) - num_episodes: number of episodes of agent-environment interaction - window: number of episodes to consider when calculating average rewards Returns ======= - avg_rewards: deque containing average rewards - best_avg_reward: largest value in the avg_rewards deque """ # initialize average rewards avg_rewards = deque(maxlen=num_episodes) # initialize best average reward best_avg_reward = -math.inf # initialize monitor for most recent rewards samp_rewards = deque(maxlen=window) # for each episode for i_episode in range(1, num_episodes+1): # begin the episode state = env.reset() # initialize the sampled reward samp_reward = 0 while True: # agent selects an action action = agent.select_action(state) # agent performs the selected action next_state, reward, done, _ = env.step(action) # agent performs internal updates based on sampled experience agent.step(state, action, reward, next_state, done) # update the sampled reward samp_reward += reward # update the state (s <- s') to next time step state = next_state if done: # save final sampled reward samp_rewards.append(samp_reward) break if (i_episode >= 100): # get average reward from last 100 episodes avg_reward = np.mean(samp_rewards) # append to deque avg_rewards.append(avg_reward) # update best average reward if avg_reward > best_avg_reward: best_avg_reward = avg_reward # monitor progress print("\rEpisode {}/{} || Best average reward {}".format(i_episode, num_episodes, best_avg_reward), end="") sys.stdout.flush() # check if task is solved (according to OpenAI Gym) if best_avg_reward >= 9.7: print('\nEnvironment solved in {} episodes.'.format(i_episode), end="") break if i_episode == num_episodes: print('\n') return avg_rewards, best_avg_reward