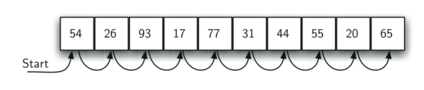
1. Linear Search• In computer science linear search (or sequential search) is a method of finding a target value within a list.• It sequentially checks each element of the list for the target value until a match is found or until all the elements have been searched.– Therefore, the best case scenario time complexity → O(1) and worst case scenario → O(n).
// all of these JS search methods are linear searchvar beasts =['Centaur','Godzilla','Mosura','Minotaur','Hydra','Nessie'];beasts.indexOf('Godzilla');beasts.findIndex(function(item){return item ==='Godzilla';});beasts.find(function(item){return item ==='Godzilla';})beasts.includes('Godzilla')
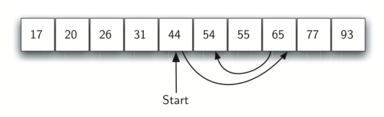
2. Binary search• Is there a better way (instead of checking every single item) to find a number in a sorted list? → We can use binary search.• Let's say we have this sorted list and searching for 34 → [1,4,6,9,12,34,45].• Because the list is sorted, we can discard half the items (instead of one at a time).– We start in the middle of the list and compare the middle element with the number we're searching for, i.e. 34 in our example.– Since 34>9 → we discard everything to the left of 9 → [9,12,34,45]– Next, we repeat the two steps above until we hit 34.* Note: If there's an even number (hence no middle element), we just go to the element next to the middle, i.e. 12 in our example.• Note:If it's sorted, we can do better than O(n), i.e. linear time, as we also see in binary search trees.– By sorting the list, we're essentially creating a binary search tree.– Unlike linear search, we can discard half the items instead of one at a time.• Doesn't sorting itself adds to computational efforts?– Storing data in a data structure like a tree (instead of a linear data structure like an array) is actually more efficient.– As we insert items, if we sort them, it actually gives us better performance than adding it to an unsorted list that we have to search through one day.– Also, trees use divide & conquer approach built-in which give us → O(logn) → since we don't have to visit everything.• Note: The code for binary search is the same as the lookup method in binary search tree.
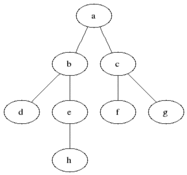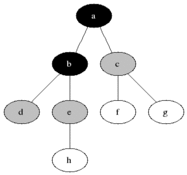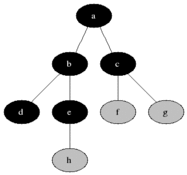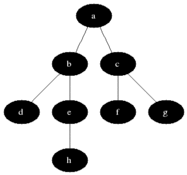
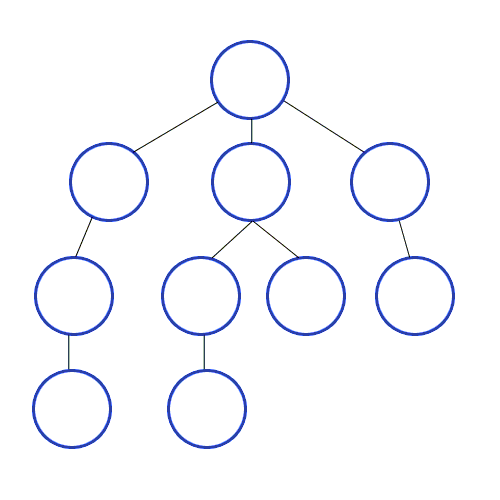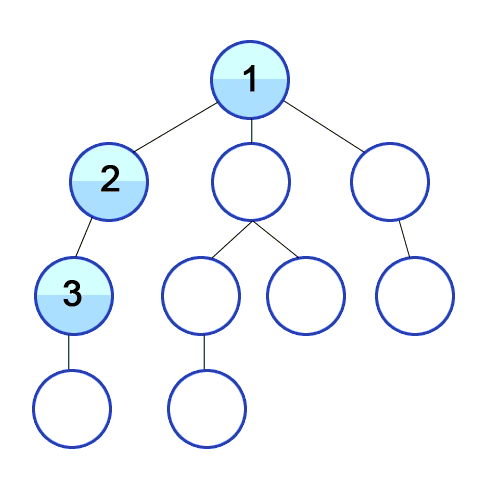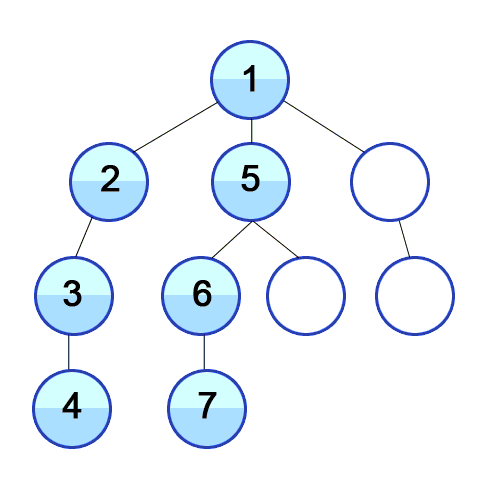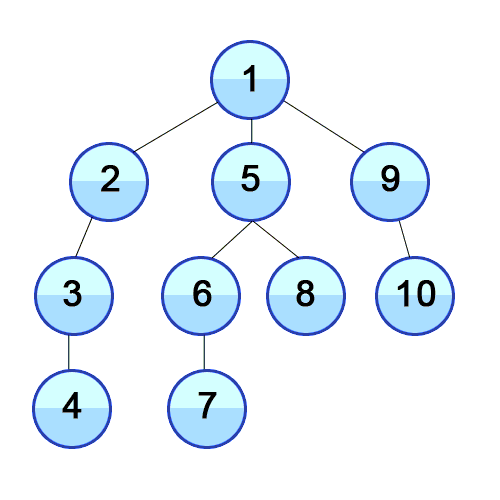
3. Graph + Tree traversals• There are times when we want to do something called traversal.– Note: The name traversal and search is often used interchangeably.– You can think of traversals as visiting every node.– Because we're visiting every node, that's an O(n) operation (linear time).• There are times that we want to do some operations on the same node (e.g. we want to add some property to every node, or perhaps we don't have a sorted tree).– Bottom line, any case that requires us to search/traverse the entire tree/graph.• So far, we have used loops to traverse data structures like arrays, linked lists, hash tables. How do we go about traversing trees and graphs?– Depth-First Search (DFS)– Breadth-First Search (BFS)• Note:The main reason why we don't put complex data into, say, arrays that are sorted is that we get the O(logn) searching (instead of O(n) for arrays). – Same thing for hash tables. Hash tables aren't ordered.– Trees (and graphs) are great data structures for searching and also deleting/inserting items.4. Breadth-First Search (BFS)• The way it works is that you start with the root node and move left to right across the second level, then move left to right across the third level and so on and so forth.– You basically just keep going from left to right level by level until you find what you searched for or reach the end of the tree.– Note: Extra memory, usually a queue, is needed to keep track of the child nodes that were encountered but not yet explored.
Figure 3:Breadth-First Search
classNode{constructor(value){this.left =null;this.right =null;this.value = value;}}classBinarySearchTree{constructor(){this.root =null;}insert(value){const newNode =newNode(value);if(this.root ===null){this.root = newNode;}else{let currentNode =this.root;while(true){if(value < currentNode.value){//Leftif(!currentNode.left){ currentNode.left = newNode;returnthis;} currentNode = currentNode.left;}else{//Rightif(!currentNode.right){ currentNode.right = newNode;returnthis;} currentNode = currentNode.right;}}}}lookup(value){if(!this.root){returnfalse;}let currentNode =this.root;while(currentNode){if(value < currentNode.value){ currentNode = currentNode.left;}elseif(value > currentNode.value){ currentNode = currentNode.right;}elseif(currentNode.value === value){return currentNode;}}returnnull}remove(value){if(!this.root){returnfalse;}let currentNode =this.root;let parentNode =null;while(currentNode){if(value < currentNode.value){ parentNode = currentNode; currentNode = currentNode.left;}elseif(value > currentNode.value){ parentNode = currentNode; currentNode = currentNode.right;}elseif(currentNode.value === value){//We have a match, get to work!//Option 1: No right child: if(currentNode.right ===null){if(parentNode ===null){this.root = currentNode.left;}else{//if parent > current value, make current left child a child of parentif(currentNode.value < parentNode.value){ parentNode.left = currentNode.left;//if parent < current value, make left child a right child of parent}elseif(currentNode.value > parentNode.value){ parentNode.right = currentNode.left;}}//Option 2: Right child which doesnt have a left child}elseif(currentNode.right.left ===null){if(parentNode ===null){this.root = currentNode.left;}else{ currentNode.right.left = currentNode.left;//if parent > current, make right child of the left the parentif(currentNode.value < parentNode.value){ parentNode.left = currentNode.right;//if parent < current, make right child a right child of the parent}elseif(currentNode.value > parentNode.value){ parentNode.right = currentNode.right;}}//Option 3: Right child that has a left child}else{//find the Right child's left most childlet leftmost = currentNode.right.left;let leftmostParent = currentNode.right;while(leftmost.left !==null){ leftmostParent = leftmost; leftmost = leftmost.left;}//Parent's left subtree is now leftmost's right subtree leftmostParent.left = leftmost.right; leftmost.left = currentNode.left; leftmost.right = currentNode.right;if(parentNode ===null){this.root = leftmost;}else{if(currentNode.value < parentNode.value){ parentNode.left = leftmost;}elseif(currentNode.value > parentNode.value){ parentNode.right = leftmost;}}}returntrue;}}}BreadthFirstSearch(){let currentNode =this.root;let list =[];let queue =[]; queue.push(currentNode);while(queue.length >0){ currentNode = queue.shift(); list.push(currentNode.value);if(currentNode.left){ queue.push(currentNode.left);}if(currentNode.right){ queue.push(currentNode.right);}}return list;}// BFS recursiveBreadthFirstSearchR(queue, list){if(!queue.length){return list;}const currentNode = queue.shift(); list.push(currentNode.value);if(currentNode.left){ queue.push(currentNode.left);}if(currentNode.right){ queue.push(currentNode.right);}returnthis.BreadthFirstSearchR(queue, list);}}const tree =newBinarySearchTree();tree.insert(9)tree.insert(4)tree.insert(6)tree.insert(20)tree.insert(170)tree.insert(15)tree.insert(1)console.log('BFS', tree.BreadthFirstSearch());console.log('BFS', tree.BreadthFirstSearchR([tree.root],[]))// 9// 4 20//1 6 15 170functiontraverse(node){const tree ={ value: node.value }; tree.left = node.left ===null?null:traverse(node.left); tree.right = node.right ===null?null:traverse(node.right);return tree;}
5. Depth-First Search (DFS)• The DFS search follows one branch of the tree down as many levels as possible until the target node is found or the end is reached.• When the search can't go on any further, it continues at the nearest ancestor with an unexplored child.• Note:DFS has a lower memory requirement than BFS because it's not necessary to store all the child pointers at each level.• The idea of DFS is that we want to go as deep as possible into a graph, usually starting from the left side, and then start going to the right until the traversal of the tree is done.
Figure 4:Depth-First Search
• There are three ways to implement DFS: 10533101– InOrder → 33,101,105 → left, parent, right– PreOrder → 101,33,105 → parent, left, right– PostOrder → 33,105,101 → left, right, parent
classNode{constructor(value){this.left =null;this.right =null;this.value = value;}}classBinarySearchTree{constructor(){this.root =null;}insert(value){const newNode =newNode(value);if(this.root ===null){this.root = newNode;}else{let currentNode =this.root;while(true){if(value < currentNode.value){//Leftif(!currentNode.left){ currentNode.left = newNode;returnthis;} currentNode = currentNode.left;}else{//Rightif(!currentNode.right){ currentNode.right = newNode;returnthis;} currentNode = currentNode.right;}}}}lookup(value){if(!this.root){returnfalse;}let currentNode =this.root;while(currentNode){if(value < currentNode.value){ currentNode = currentNode.left;}elseif(value > currentNode.value){ currentNode = currentNode.right;}elseif(currentNode.value === value){return currentNode;}}returnnull}remove(value){if(!this.root){returnfalse;}let currentNode =this.root;let parentNode =null;while(currentNode){if(value < currentNode.value){ parentNode = currentNode; currentNode = currentNode.left;}elseif(value > currentNode.value){ parentNode = currentNode; currentNode = currentNode.right;}elseif(currentNode.value === value){//We have a match, get to work!//Option 1: No right child: if(currentNode.right ===null){if(parentNode ===null){this.root = currentNode.left;}else{//if parent > current value, make current left child a child of parentif(currentNode.value < parentNode.value){ parentNode.left = currentNode.left;//if parent < current value, make left child a right child of parent}elseif(currentNode.value > parentNode.value){ parentNode.right = currentNode.left;}}//Option 2: Right child which doesnt have a left child}elseif(currentNode.right.left ===null){if(parentNode ===null){this.root = currentNode.left;}else{ currentNode.right.left = currentNode.left;//if parent > current, make right child of the left the parentif(currentNode.value < parentNode.value){ parentNode.left = currentNode.right;//if parent < current, make right child a right child of the parent}elseif(currentNode.value > parentNode.value){ parentNode.right = currentNode.right;}}//Option 3: Right child that has a left child}else{//find the Right child's left most childlet leftmost = currentNode.right.left;let leftmostParent = currentNode.right;while(leftmost.left !==null){ leftmostParent = leftmost; leftmost = leftmost.left;}//Parent's left subtree is now leftmost's right subtree leftmostParent.left = leftmost.right; leftmost.left = currentNode.left; leftmost.right = currentNode.right;if(parentNode ===null){this.root = leftmost;}else{if(currentNode.value < parentNode.value){ parentNode.left = leftmost;}elseif(currentNode.value > parentNode.value){ parentNode.right = leftmost;}}}returntrue;}}}BreadthFirstSearch(){let currentNode =this.root;let list =[];let queue =[]; queue.push(currentNode);while(queue.length >0){ currentNode = queue.shift(); list.push(currentNode.value);if(currentNode.left){ queue.push(currentNode.left);}if(currentNode.right){ queue.push(currentNode.right);}}return list;}BreadthFirstSearchR(queue, list){if(!queue.length){return list;}const currentNode = queue.shift(); list.push(currentNode.value);if(currentNode.left){ queue.push(currentNode.left);}if(currentNode.right){ queue.push(currentNode.right);}returnthis.BreadthFirstSearchR(queue, list);}DFTPreOrder(currentNode, list){returntraversePreOrder(this.root,[]);}DFTPostOrder(){returntraversePostOrder(this.root,[]);}DFTInOrder(){returntraverseInOrder(this.root,[]);}}functiontraversePreOrder(node, list){ list.push(node.value);if(node.left){traversePreOrder(node.left, list);}if(node.right){traversePreOrder(node.right, list);}return list;}functiontraverseInOrder(node, list){if(node.left){traverseInOrder(node.left, list);} list.push(node.value);if(node.right){traverseInOrder(node.right, list);}return list;}functiontraversePostOrder(node, list){if(node.left){traversePostOrder(node.left, list);}if(node.right){traversePostOrder(node.right, list);} list.push(node.value);return list;}const tree =newBinarySearchTree();tree.insert(9)tree.insert(4)tree.insert(6)tree.insert(20)tree.insert(170)tree.insert(15)tree.insert(1)// tree.remove(170);// JSON.stringify(traverse(tree.root))console.log('BFS', tree.BreadthFirstSearch());console.log('BFS', tree.BreadthFirstSearchR([tree.root],[]))console.log('DFSpre', tree.DFTPreOrder());console.log('DFSin', tree.DFTInOrder());console.log('DFSpost', tree.DFTPostOrder());// 9// 4 20//1 6 15 170functiontraverse(node){const tree ={ value: node.value }; tree.left = node.left ===null?null:traverse(node.left); tree.right = node.right ===null?null:traverse(node.right);return tree;}
6. BFS vs. DFS• When should we use one over the other?• Time complexity of BFS and DFS → O(n)• Rule of thumb when to use BFS → If you have additional information on the location of the target node, and you know that the node is likely in the upper level of a tree, then BFS is better → it searches the closest nodes first.– For DFS → If you know that the node is likely at the lower level of a tree, perhaps DFS is better.– DFS → really good at asking the question: does a path exist to a certain node from a source node to the target node?– DFS → not good at finding the shortest path.– DFS → can get very slow especially with very large trees/graphs.
//If you know a solution is not far from the root of the tree:BFS//If the tree is very deep and solutions are rare, BFS(DFS will take long time.)//If the tree is very wide:DFS(BFS will need too much memory)//If solutions are frequent but located deep in the treeDFS//determining whether a path exists between two nodesDFS//Finding the shortest pathBFS
• A very common question you will get asked in an interview is how to validate a binary search tree! Give it a go (hint, you want to use BFS for this)!7. Graph Traversals• We can apply all above to graphs as well, because trees are just a type of graph.• A nice visual on BFS and DFS on graphs8. Dijkstra + Bellman-Ford algorithm• In interview, you're most likely not going to implement it because they're complicated for an interview session.– However, the interviewer might expect you to know about them and know that you'd use Bellman-Ford or Dijkstra algorithms to figure out the shortest path.• We mentioned in previous sections that BFS is used for shortest path problems. Why do we need these algorithms then?– BFS is great for shortest path problem, but there's one thing it can't do.– It assumes that each path to another node in a graph has the same weight.* Note: With BFS and DFS we don't consider the edge weight.– That's not always the case → for example, in Google Maps, not all roads are equally fast. We have to be able to weigh different roads based on their traffic or the distances are different between different nodes.• Dijkstra or Bellman-Ford algorithms allows for finding the shortest path between two nodes when the graph is weighted.• Bellman-Ford is very effective at solving the shortest path over Dijkstra's algorithm because it can accommodate negative weights.• Bellman-Ford can take a long time to run in terms of complexity → It's not the most efficient algorithm → The worst case time complexity → O(n2)• Dijkstra's algorithm is a little bit faster than Bellman-Ford.• How does Dijkstra's algorithm work?