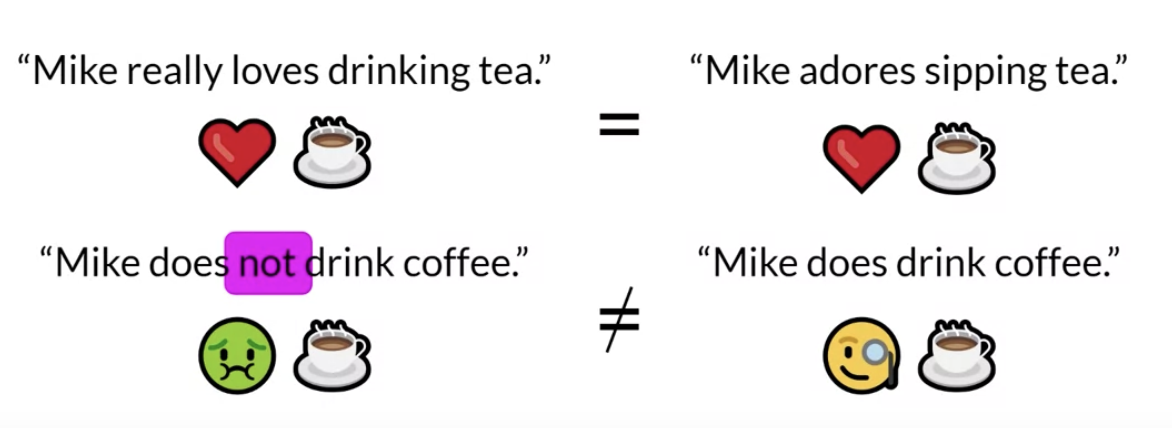1. Fine-tuning LLMs with Instructions1.1. Introduction• When you have your base model, the thing that's initially pretrained, it's encoded a lot of really good information, usually about the world. – So it knows about things, but it doesn't necessarily know how to be able to respond to our prompts, our questions. – So when we instruct it to do a certain task, it doesn't necessarily know how to respond. – Predicting what's the next word on the Internet is not the same as following instructions.• Instruction fine-tuning helps it to be able to change its behavior to be more helpful for us.• One of the things to watch out for, is catastrophic forgetting → that's where you train the model on some extra data in instruct fine-tuning, and then it forgets all of that stuff that it had before, or a big chunk of that data that it had before. • – One way to combat that doing instruct fine-tuning across a broad range of different intruction types. • There are two types of fine-tuning that are very worth doing.❏ Instruct fine-tuning❏ Fine-tuning for a spcialized application• One of the problems with fine-tuning is you take a giant model and you fine-tune every single parameter in that model. You have this big thing to store around and deploy, and it's actually very compute and memory expansive → There are better techniques than that.• ❏ Parameter Efficient Fine-Tuning (PEFT)* One of the PEFT techniques is LoRA.Back To Top1.2. Instruction Fine-Tuning• In previous chapter, we saw that some models are capable of identifying instructions contained in a prompt (i.e. In-context learning, ICL) and correctly carrying out zero/one/few-shot inference. Note that as we mentioned before, some smallers LLMs might fails with ICL.
• The ICL strategy has a couple of drawbacks:➔ It may not work for smaller models.➔ Examples take up space in the context window.• In such case, we can do fine-tuning.• Fine-tuning with instruction prompts is the most common way to fine-tune LLMs these days.
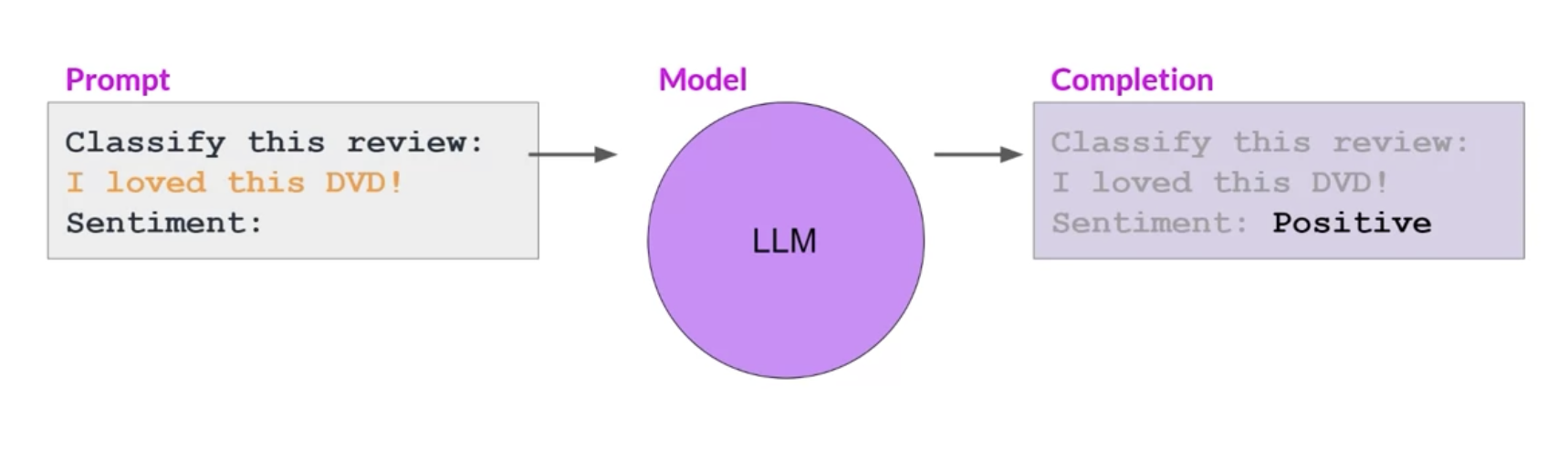
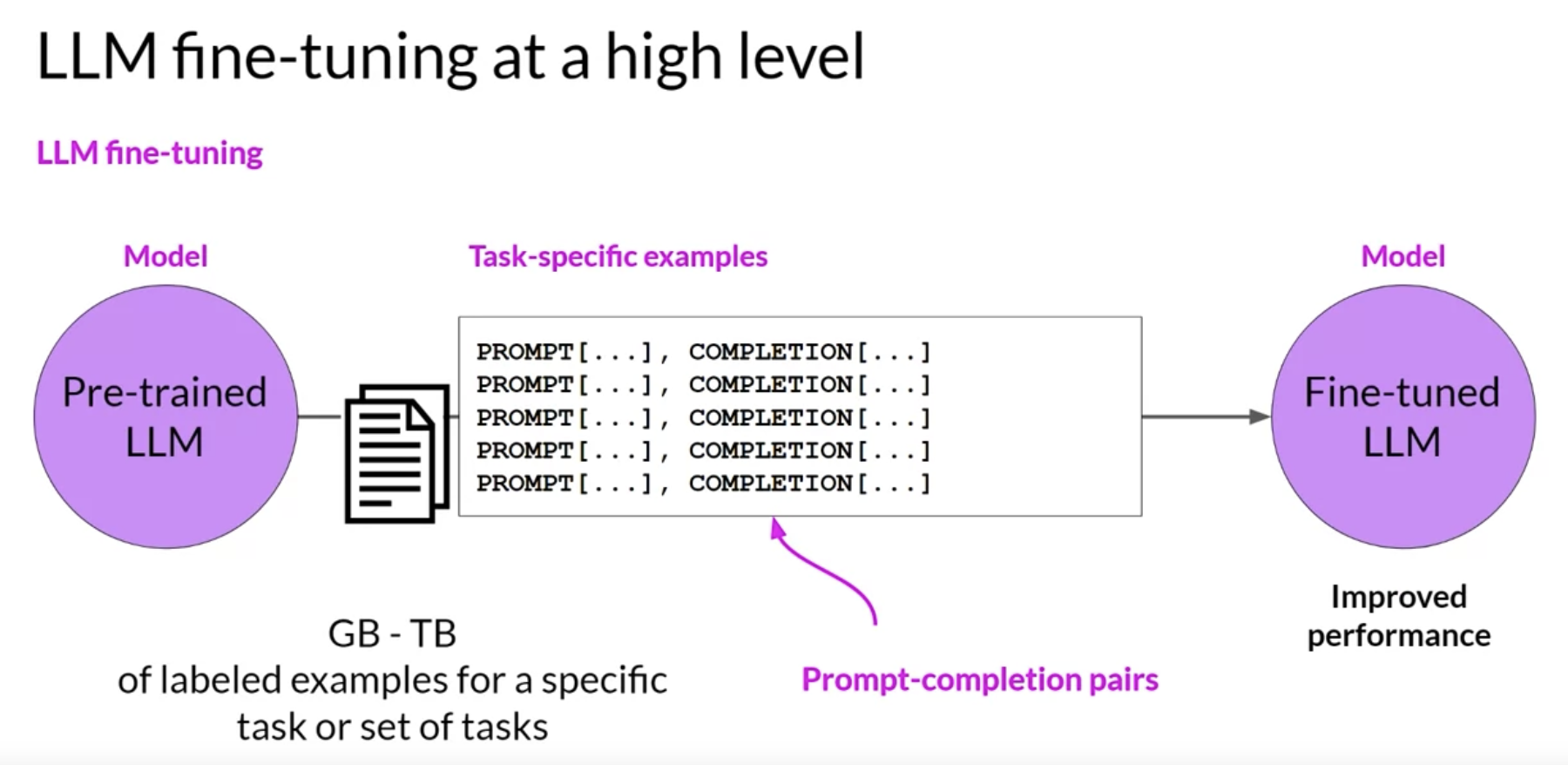
• In contrast to pre-training, where you train the LLM using vast amounts of unstructured textual data via selfsupervised learning, fine-tuning is a supervised learning process where you use a data set of labeled examples to update the weights of the LLM.• – The labeled examples are prompt completion pairs, the fine-tuning process extends the training of the model to improve its ability to generate good completions for a specific task.– – One strategy, known as instruction fine tuning, is particularly good at improving a model's performance on a variety of tasks.
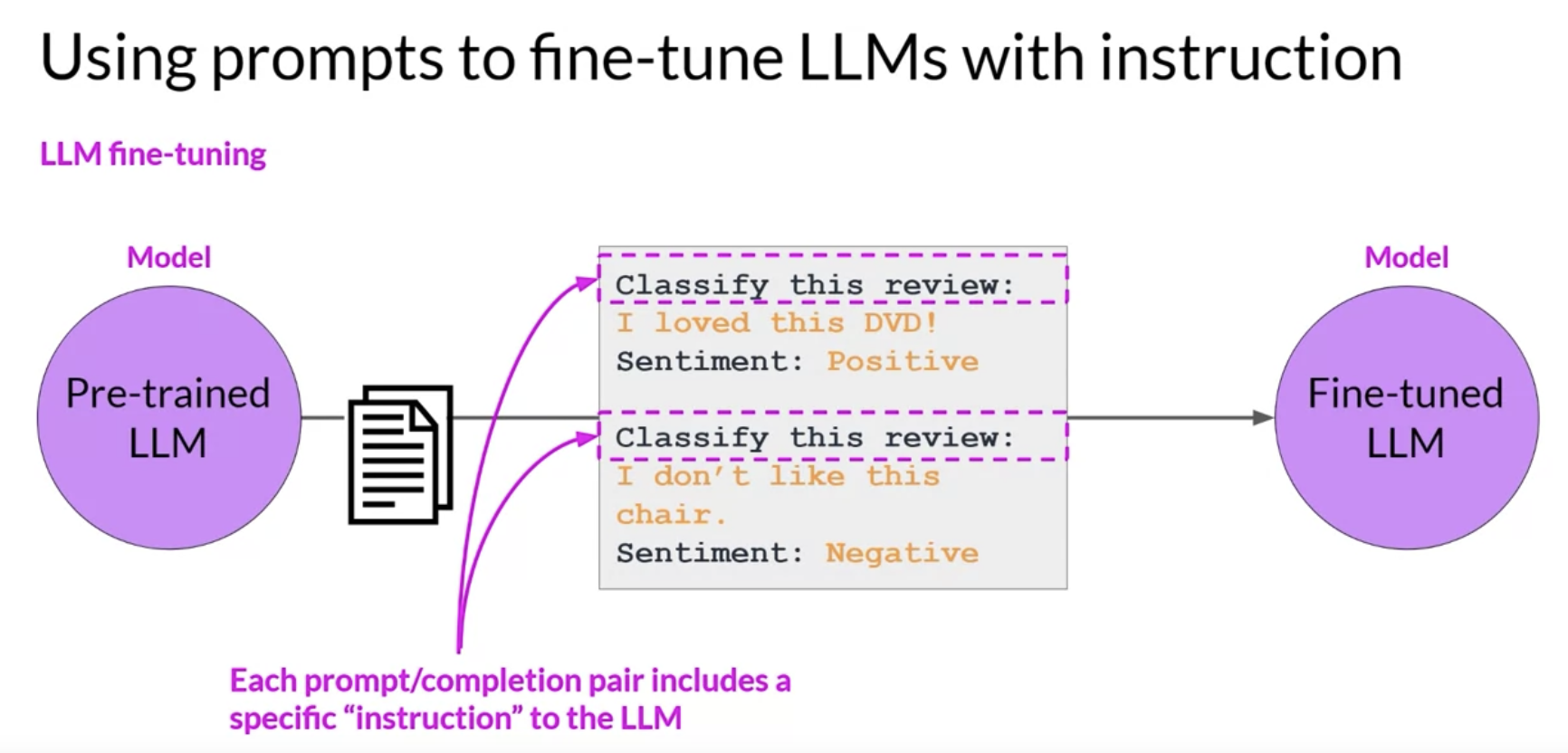
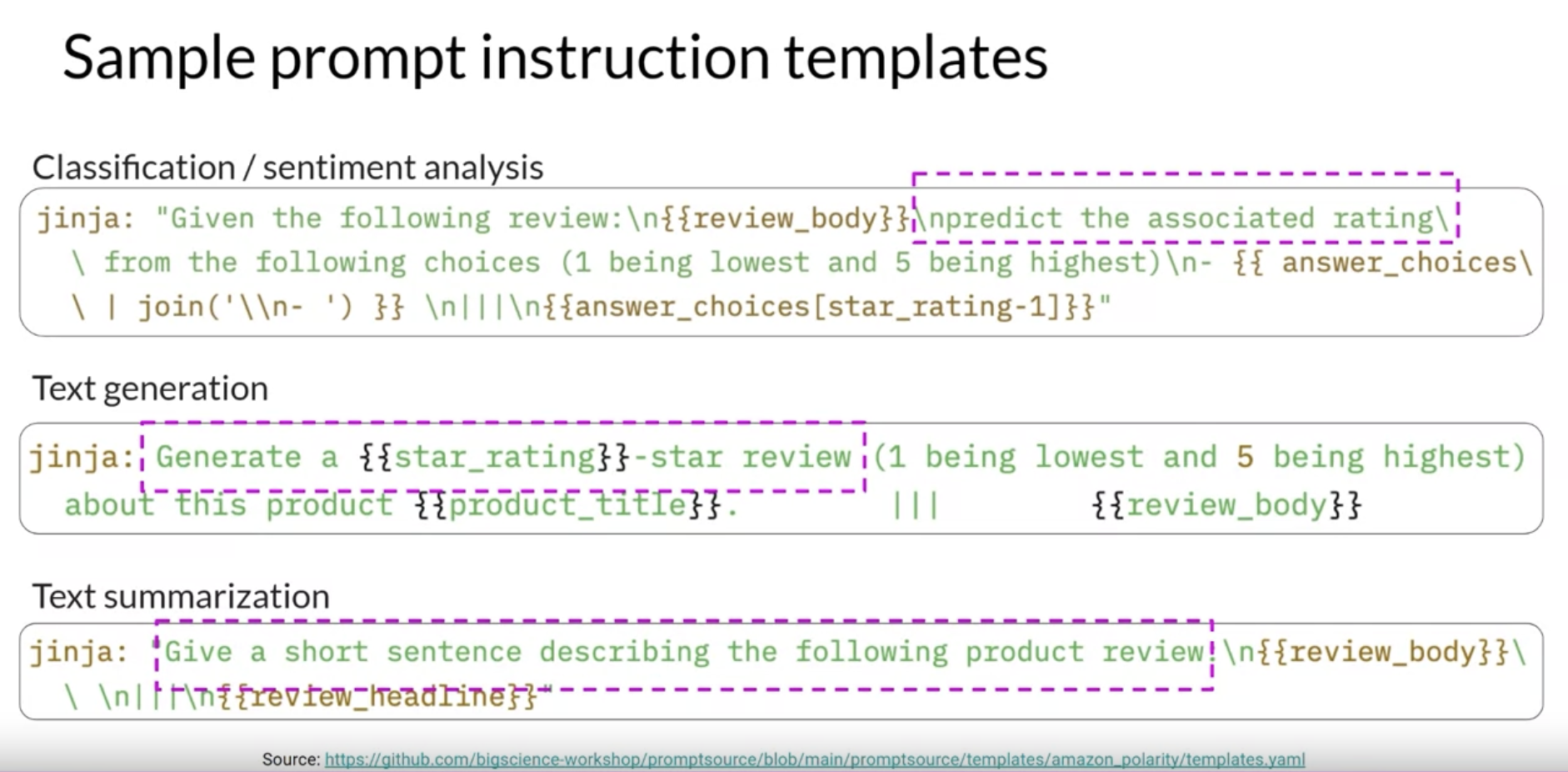
• Instruction fine-tuningtrains the model using examples that demonstrate how it should respond to a specific instruction. • – For example,* if you want to fine tune your model to improve its summarization ability, you'd build up a data set of examples that begin with the instruction summarize, the following text or a similar phrase. * if you are improving the model's translation skills, your examples would include instructions like translate this sentence. • These prompt completion examples allow the model to learn to generate responses that follow the given instructions.• NOTE → Just like pre-training, full fine tuning requires enough memory and compute budget to store and process all the gradients, optimizers and other components that are being updated during training.Back To Top1.2.1. How do you actually go about instruction, fine-tuning and LLM?• Step 1 is to prepare your training data.• – There are many publicly available datasets that have been used to train earlier generations of language models, although most of them are not formatted as instructions.– – Developers have assembled prompt template libraries that can be used to take existing datasets, for example, the large data set of Amazon product reviews and turn them into instruction prompt datasets for fine-tuning.– * Prompt template libraries include many templates for different tasks and different data sets.* Here are three prompts that are designed to work with the Amazon reviews dataset and that can be used to fine tune models for classification, text generation and text summarization tasks. · You can see that in each case you pass the original review, here called review_body, to the template, where it gets inserted into the text that starts with an instruction like predict the associated rating, generate a star review, or give a short sentence describing the following product review. · → The result is a prompt that now contains both an instruction and the example from the data set.
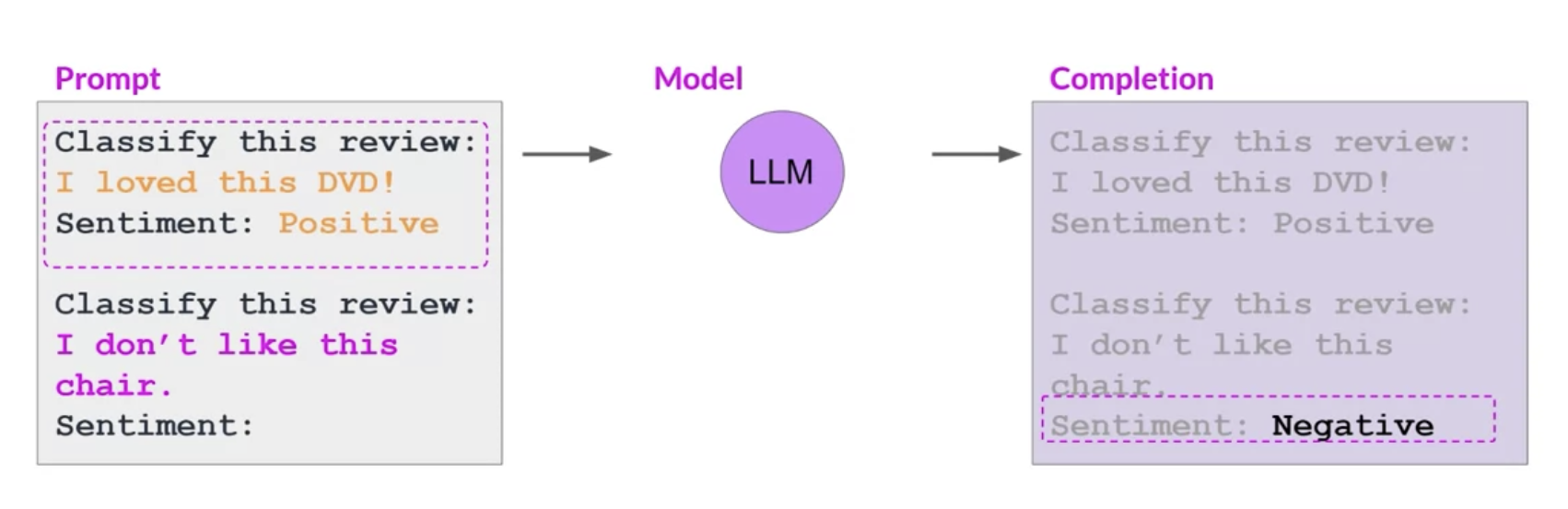
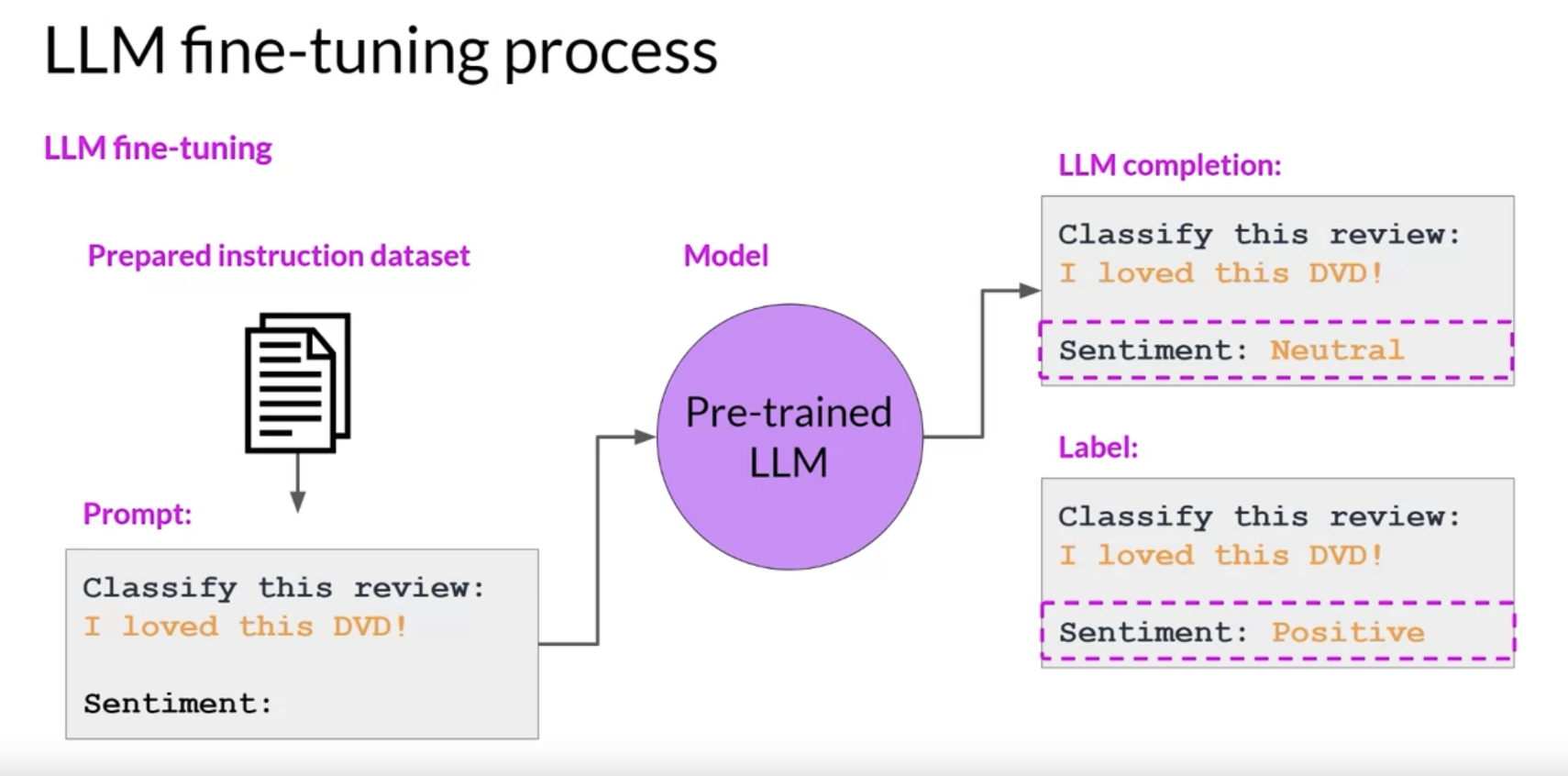
• Step 2 is to divide the data set into training validation and test splits.• – During fine tuning, you select prompts from your training data set and pass them to the LLM, which then generates completions. Next, you compare the LLM completion with the response specified in the training data.•
Figure 1:Here that the model didn't do a great job, it classified the review as neutral, which is a bit of an understatement. The review is clearly very positive.
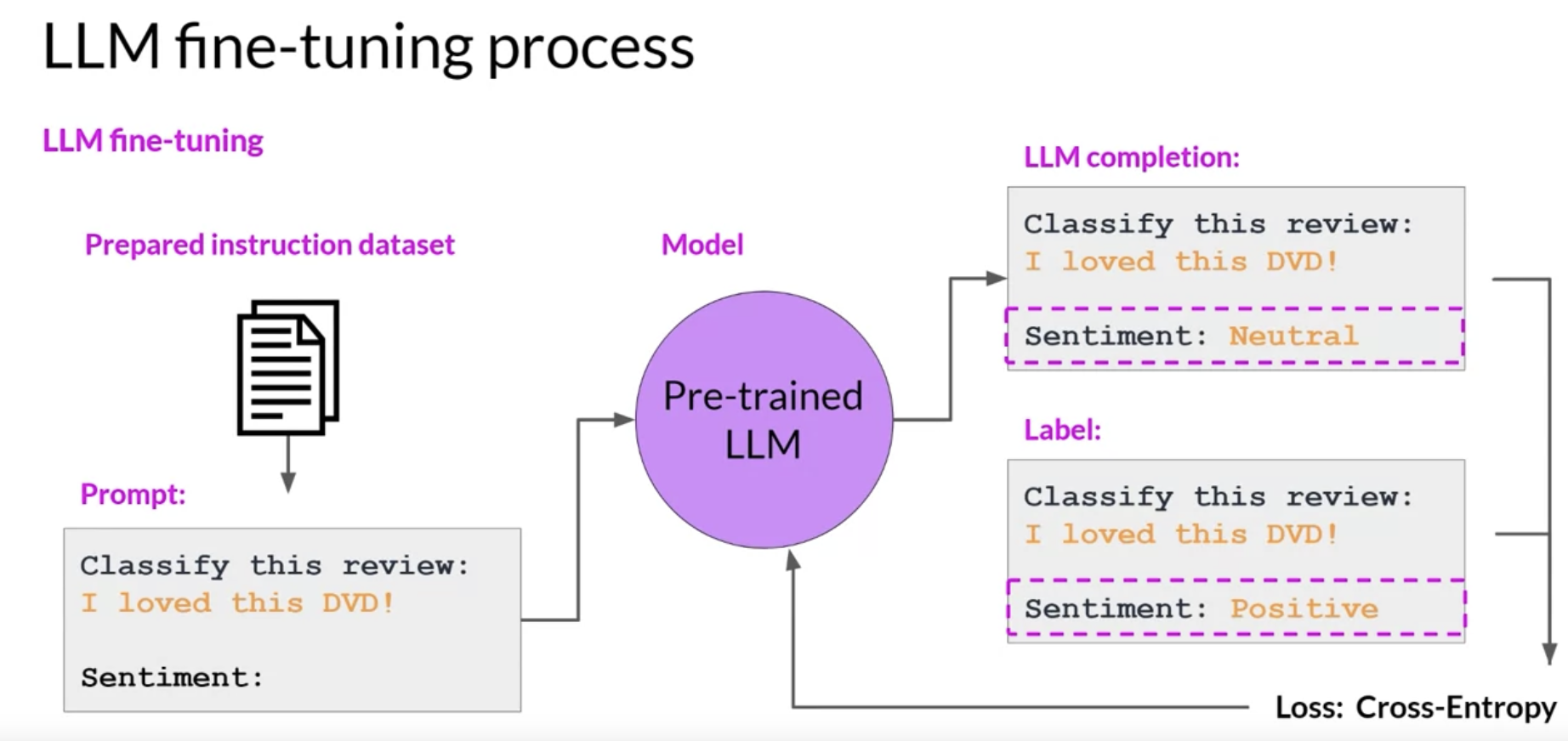
• – Remember that the output of an LLM is a probability distribution across tokens. So you can compare the distribution of the completion and that of the training label and use the standard crossentropy function to calculate loss between the two token distributions. – * And then use the calculated loss to update your model weights in standard backpropagation. * You'll do this for many batches of prompt completion pairs and over several epochs, update the weights so that the model's performance on the task improves.
Back To Top1.3. Fine-tuning on a Single Task• Your application may only need to perform a single task. In this case, you can fine-tune a pre-trained model to improve performance on only the task that is of interest to you. For example, summarization using a dataset of examples for that task.• Good results can be achieved with relatively few examples.• – Often just 500-1,000 examples can result in good performance in contrast to the billions of pieces of texts that the model saw during pre-training. 1.3.1. Catastrophic Forgetting• There is a potential downside to fine-tuning on a single task.• – The process may lead to a phenomenon called catastrophic forgetting. – * Catastrophic forgetting happens because the full fine-tuning process modifies the weights of the original LLM. * While this leads to great performance on the single fine-tuning task, it can degrade performance on other tasks.* For example, while fine-tuning can improve the ability of a model to perform sentiment analysis on a review and result in a quality completion, the model may forget how to do other tasks.1.3.2. What options do you have to avoid catastrophic forgetting?• First of all, it's important to decide whether catastrophic forgetting actually impacts your use case.• If you do want or need the model to maintain its multitask generalized capabilities, you can perform fine-tuning on multiple tasks at one time.• NOTE → Good multitask fine-tuning may require 50-100,000 examples across many tasks, and so will require more data and compute to train.• Our second option is to perform parameter efficient fine-tuning, or PEFT for short instead of full fine-tuning.• ➔ PEFT is a set of techniques that preserves the weights of the original LLM and trains only a small number of task-specific adapter layers and parameters.➔ ➔ PEFT shows greater robustness to catastrophic forgetting since most of the pre-trained weights are left unchanged.Back To Top1.4. Multi-task Instruction Fine-Tuning• Multitask fine-tuning is an extension of single task fine-tuning, where the training dataset is comprised of example inputs and outputs for multiple tasks.
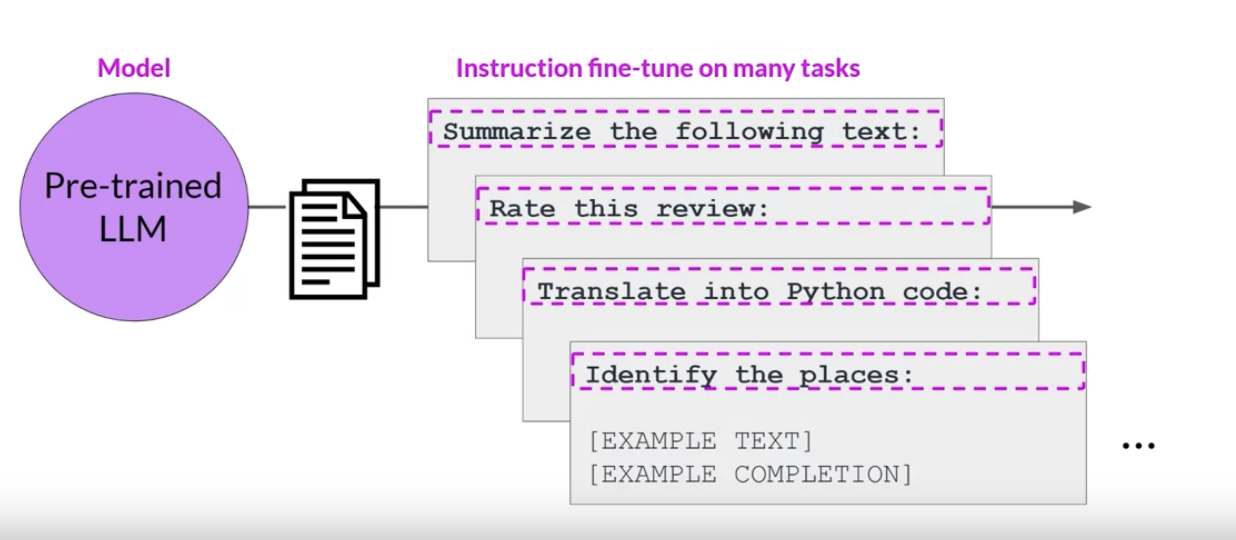
Figure 2:Here, the dataset contains examples that instruct the model to carry out a variety of tasks, including summarization, review rating, code translation, and entity recognition.
• You train the model on this mixed dataset so that it can improve the performance of the model on all the tasks simultaneously, thus avoiding the issue of catastrophic forgetting. • One drawback to multitask fine-tuning is that it requires a lot of data. You may need as many as 50-100,000 examples in your training set.• – However, it can be really worthwhile and worth the effort to assemble this data.1.4.1. FLAN Family of Models• Instruct model variance differ based on the datasets and tasks used during fine-tuning. • – One example is the FLAN family of models.– FLAN (Fine-tuned Language Net) → is a specific set of instructions used to fine-tune different models.– – FUN FACT →Because they're FLAN fine-tuning is the last step of the training process the authors of the original paper called it the metaphorical dessert to the main course of pre-training quite a fitting name.– – FLAN-T5, the FLAN instruct version of the T5 foundation model while FLAN-PALM is the FLAN instruct version of the PALM foundation model. – * FLAN-T5 is a great general purpose instruct model. In total, it's been fine tuned on 473 datasets across 146 task categories. Those datasets are chosen from other models and papers as shown here. *
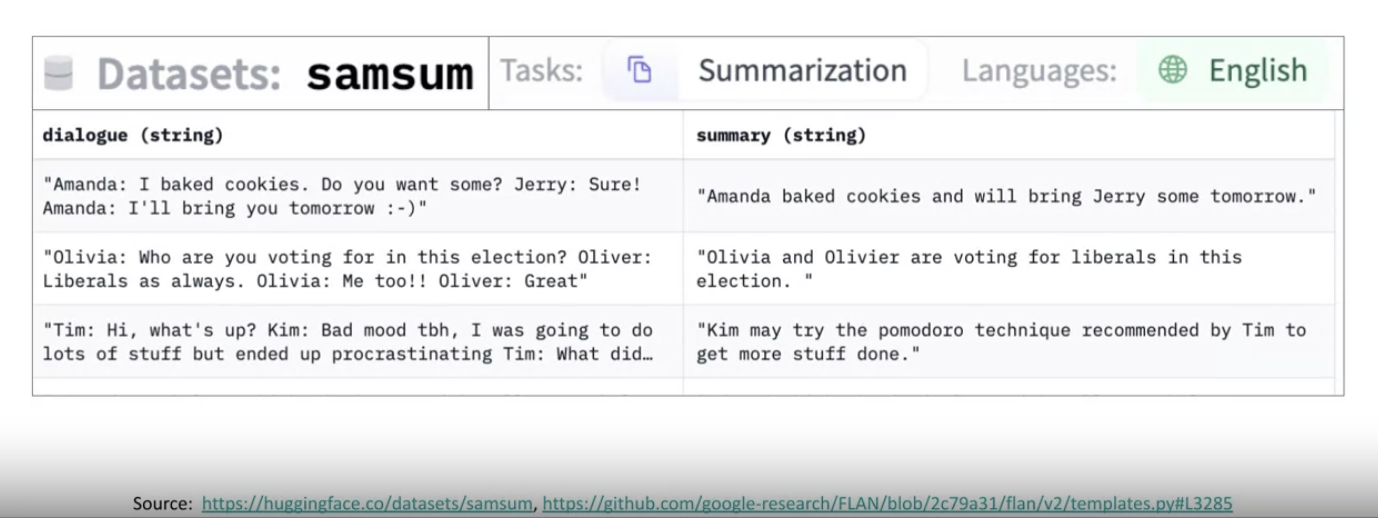
• One example of a prompt dataset used for summarization tasks in FLAN-T5 is SAMSum.• – It's part of the Muffin collection of tasks and datasets and is used to train language models to summarize dialogue.– – SAMSum is a dataset with 16,000 messenger like conversations with summaries.– – The dialogues and summaries were crafted by linguists for the express purpose of generating a high-quality training dataset for language models.– * The linguists were asked to create conversations similar to those that they would write on a daily basis, reflecting their proportion of topics of their real life messenger conversations.
• Here is a prompt template designed to work with this SAMSum dialogue summary dataset. – NOTE → Including different ways of saying the same instruction helps the model generalize and perform better.– Just like the prompt templates you saw earlier, in each case, the dialogue from the SAMSum dataset is inserted into the template wherever the dialogue field appears.– The summary is used as the label.– After applying this template to each row in the SAMSum dataset, you can use it to fine tune a dialogue summarization task.
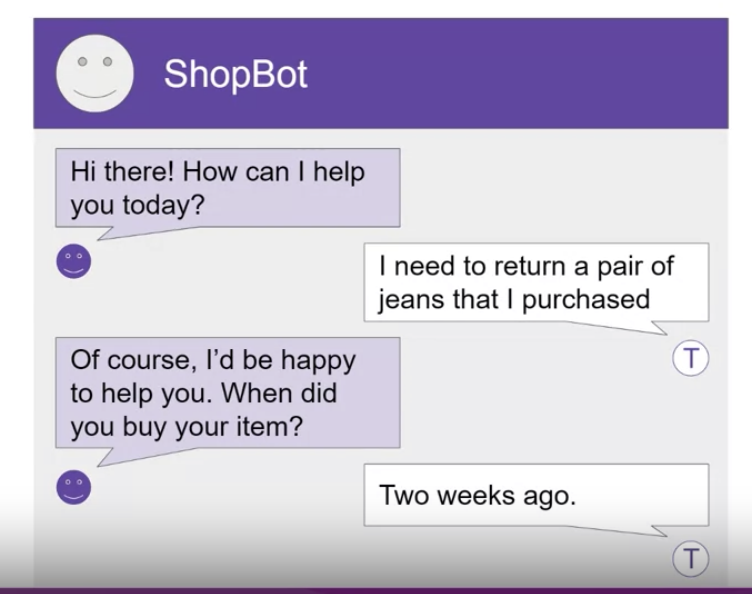
• While FLAN-T5 is a great general use model that shows good capability in many tasks. You may still find that it has room for improvement on tasks for your specific use case. • For example,• – Imagine you're a data scientist building an app to support your customer service team, process requests received through a chat bot, like the one shown below. – – Your customer service team needs a summary of every dialogue to identify the key actions that the customer is requesting and to determine what actions should be taken in response.– – The SAMSum dataset gives FLAN-T5 some abilities to summarize conversations. – – However, the examples in the dataset are mostly conversations between friends about day-to-day activities and don't overlap much with the language structure observed in customer service chats. –
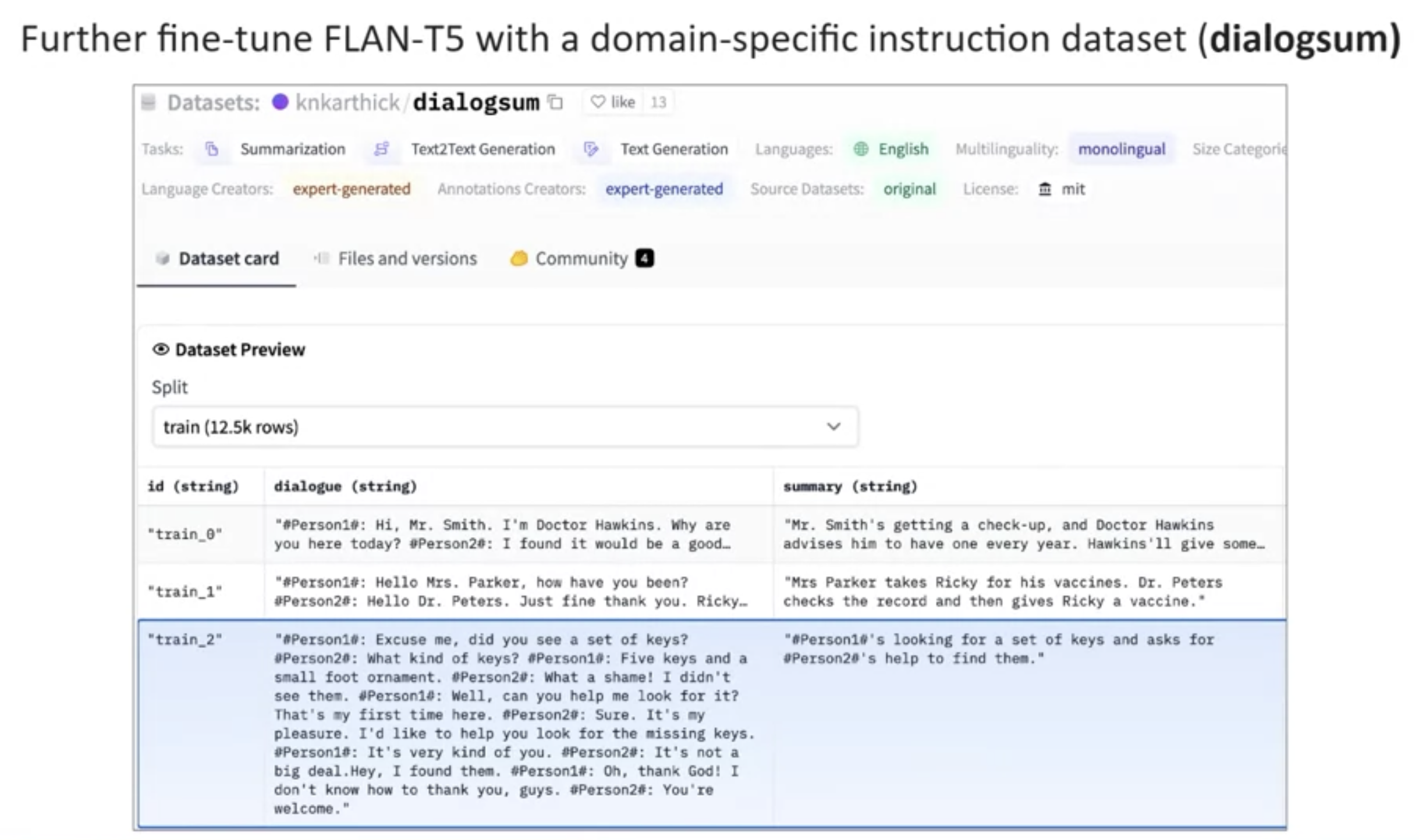
• – You can perform additional fine-tuning of the FLAN-T5 model using a dialogue dataset that is much closer to the conversations that happened with your bot.– – In the lab for this chapter, we'll work on exactly this problem.* You'll make use of an additional domain specific summarization dataset called dialogsum to improve FLAN-T5's is ability to summarize support chat conversations.* This dataset consists of over 13,000 support chat dialogues and summaries. * NOTE → The dialogsum dataset is not part of the FLAN-T5 training data, so the model has not seen these conversations before.*
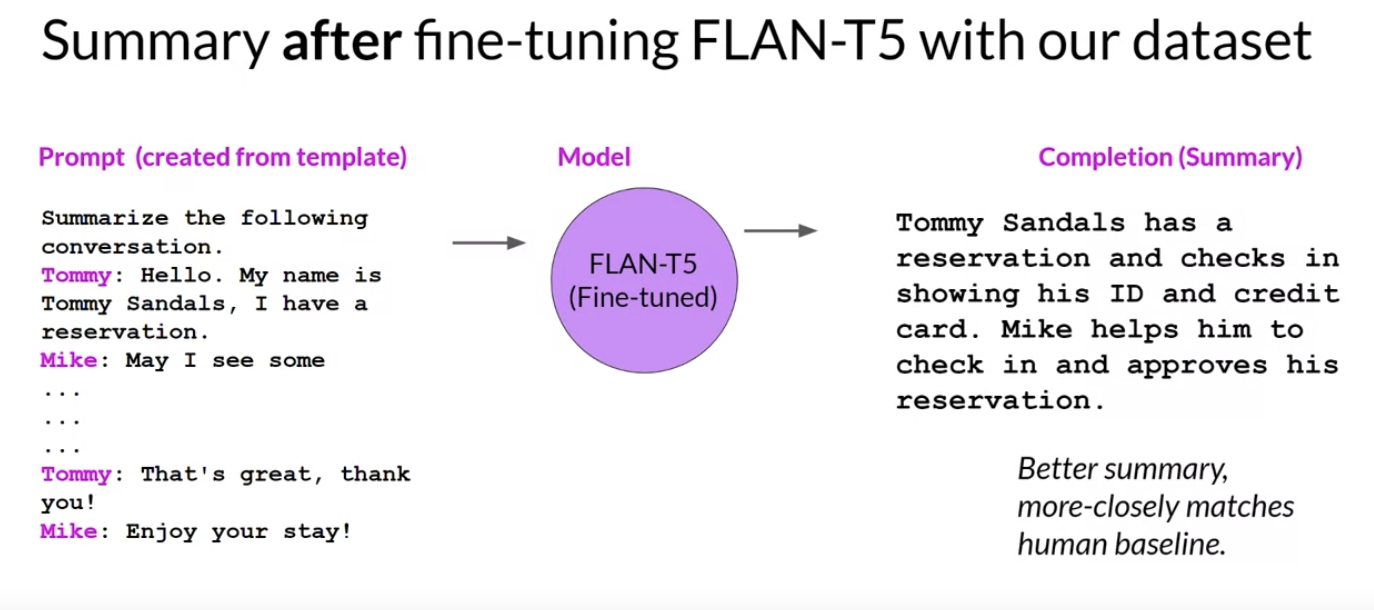
Back To Top1.4.2. How a further round of fine-tuning can improve the model?• Below is a support chat that is typical of the examples in the dialogsum dataset. • The conversation is between a customer and a staff member at a hotel check-in desk.•
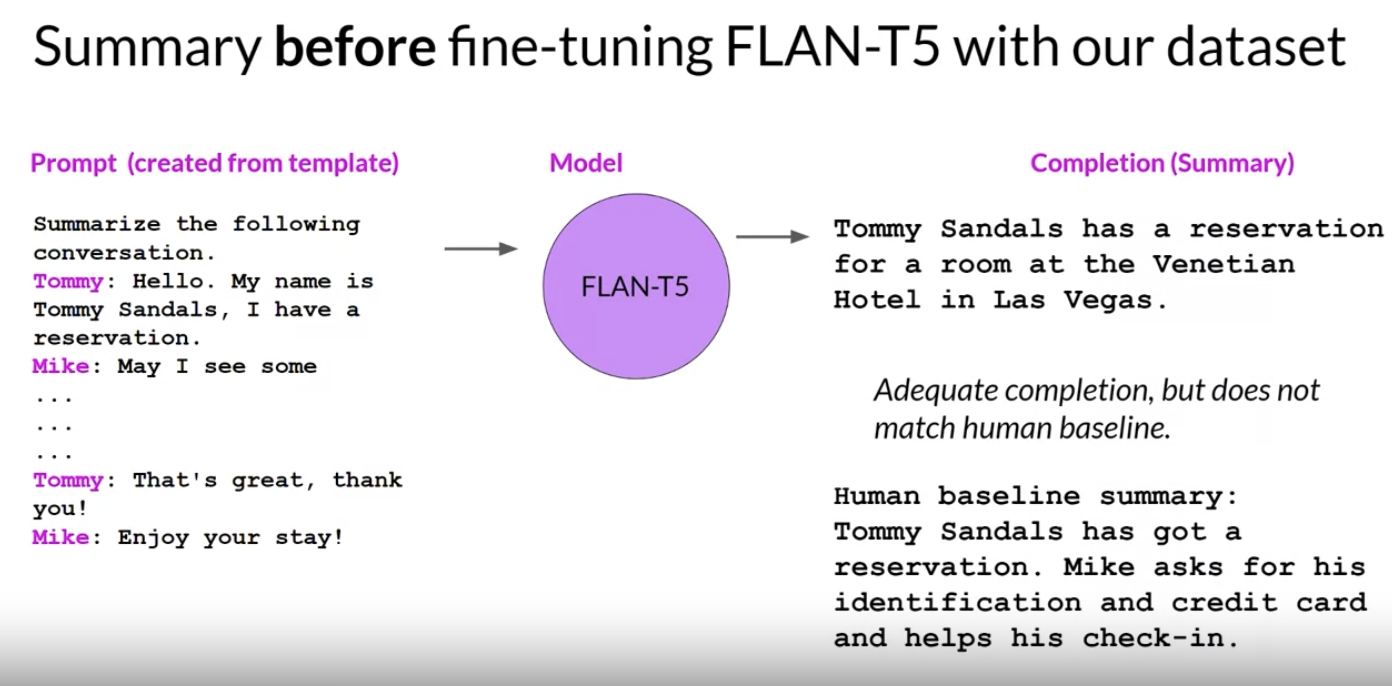
• NOTE → The chat has had a template applied so that the instruction to summarize the conversation is included at the start of the text. • Let's take a look at how FLAN-T5 responds to this prompt before doing any additional fine-tuning.• – The model does OK as it's able to identify that the conversation was about a reservation for Tommy. – However, it does not do as well as the human-generated baseline summary, which includes important information such as Mike asking for information to facilitate check-in and the models completion has also invented information that was not included in the original conversation → Specifically the name of the hotel and the city it was located in.
• Now let's take a look at how the model does after fine-tuning on the dialogue some dataset.• – This is closer to the human-produced summary. – There is no fabricated information and the summary includes all of the important details, including the names of both people participating in the conversation.
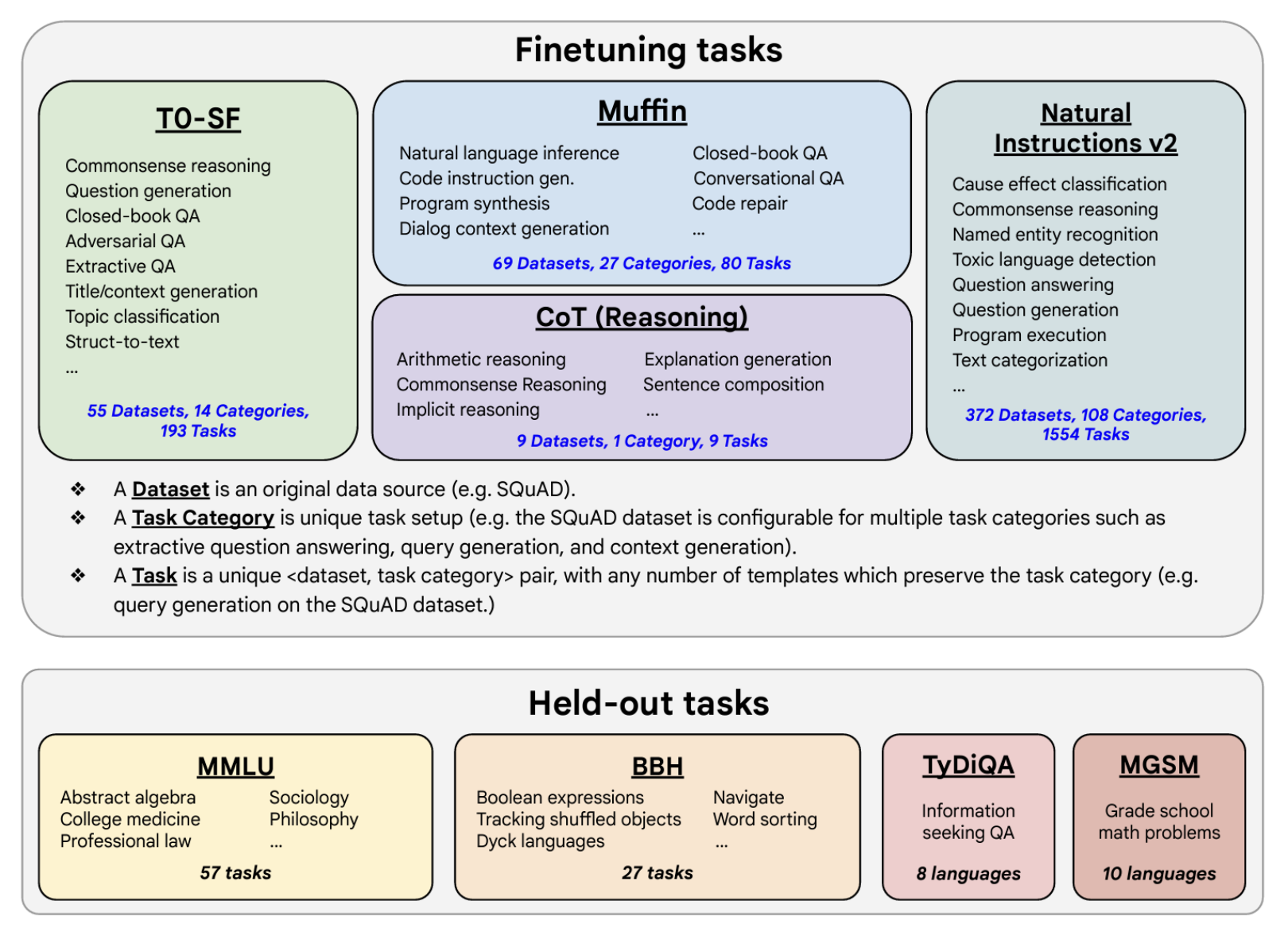
• NOTE → This example, use the public dialogue, some dataset to demonstrate fine-tuning on custom data. In practice, you'll get the most out of fine-tuning by using your company's own internal data. For example, the support chat conversations from your customer support application. – This will help the model learn the specifics of how your company likes to summarize conversations and what is most useful to your customer service colleagues.Back To Top1.5. Scaling Instruct Models• This paper introduces FLAN (Fine-tuned LAnguage Net), an instruction finetuning method, and presents the results of its application. • The study demonstrates that by fine-tuning the 540B PaLM model on 1836 tasks while incorporating Chain-of-Thought Reasoning data, FLANachieves improvements in generalization, human usability, and zero-shot reasoning over the base model. • The paper also provides detailed information on how each these aspects was evaluated.• Here is the image from the lecture slides that illustrates the fine-tuning tasks and datasets employed in training FLAN. – The task selection expands on previous works by incorporating dialogue and program synthesis tasks from Muffin and integrating them with new Chain of Thought Reasoning tasks. – It also includes subsets of other task collections, such as T0 and Natural Instructions v2. – Some tasks were held-out during training, and they were later used to evaluate the model's performance on unseen tasks.
Back To Top1.6. Model Evaluation• How can you formalize the improvement in performance of your fine-tuned model over the pre-trained model you started with?• NOTE → As opposed to traditional ML where the output is deterministic, with LLMs, where the output is non-deterministic, language-based evaluation is much more challenging. • – For example, how to measure the similarity between these two sentences which basically mean the same?* In the second example, there's only one work difference but the meaning is completely different.
1.6.1. ROUGE & BLEU• ROUGE and BLEU, are two widely used evaluation metrics for different tasks.• ROUGE (R ecall-Oriented Understudy for Gisting Evaluation) → is primarily employed to assess the quality of automatically generated summaries by comparing them to human-generated reference summaries. • • BLEU (Bilingual Evaluation Understudy) → is an algorithm designed to evaluate the quality of machine-translated text, again, by comparing it to human-generated translations.
• In the anatomy of language, a unigram is equivalent to a single word.• A bigram is two words and n-gram is a group of n-words.• You can perform simple metric calculations similar to other ML tasks using recall, precision, and F1.1.6.2. ROUGE• ROUGE-1• • Very basic metrics that only focused on individual words, hence the one in the name, and don't consider the ordering of the words.– → NOTE → Imagain the two sentences where different only by one word "not". It would give the same score here!
• ROUGE-2• By working with pairs of words you're acknowledging in a very simple way, the ordering of the words in the sentence.
• Rather than continue on with ROUGE numbers growing bigger to n-grams of three or fours, let's take a different approach.• – Instead, you'll look for the longest common subsequence (LCS) present in both the generated output and the reference output.
• Collectively, these three quantities are known as the Rouge-L score.• NOTE → As with all of the rouge scores, you need to take the values in context. You can only use the scores to compare the capabilities of models if the scores were determined for the same task → e.g., summarization.• – Rouge scores for different tasks are not comparable to one another. • A particular problem with simple rouge scores is that it's possible for a bad completion to result in a good score.• – See example below:
• ROUGE Clipping → One way you can counter this issue is by using a clipping function to limit the number of unigram matches to the maximum count for that unigram within the reference.• You'll still be challenged if their generated words are all present, but just in a different order.• – NOTE → Whilst using a different rouge score can help experimenting with a n-gram size that will calculate the most useful score will be dependent on the sentence, the sentence size, and your use case.
• NOTE → Many language model libraries, e.g. HuggingFace, include implementations of rouge score that you can use to easily evaluate the output of your model.1.6.3. BLEU• BLEU score is useful for evaluating the quality of machine-translated text.• The score is calculated using the average precision over multiple n-gram sizes. → Just like ROUGE-1 score, but calculated for a range of n-gram sizes and then averaged.• The BLEU score quantifies the quality of a translation by checking how many n-grams in the machine-generated translation match those in the reference translation.• To calculate the score, you average precision across a range of different n-gram sizes → There are libraries that calculates the score, e.g. HuggingFace.
• Both ROUGE and BLEU are quite simple metrics and are relatively low-cost to calculate. • You shouldn't use them alone to report the final evaluation of a large language model → Use ROUGE for diagnostic evaluation of summarization tasks and BLEU for translation tasks.• For overall evaluation of your model's performance, however, you will need to look at one of the evaluation benchmarks that have been developed by researchers.Back To Top1.7. Benchmarks• LLMs are complex, and simple evaluation metrics like the rouge and blur scores, can only tell you so much about the capabilities of your model.• For a more holistic evaluation, you can make use of pre-existing datasets, and associated benchmarks that have been established by LLM researchers specifically for this purpose.• Selecting the right evaluation dataset is vital, so that you can accurately assess an LLM's performance, and understand its true capabilities.• – You'll find it useful to select datasets that isolate specific model skills, like reasoning or common sense knowledge, and those that focus on potential risks, such as disinformation or copyright infringement.• NOTE → An important issue that you should consider is whether the model has seen your evaluation data during training. • Benchmarks, such as GLUE, SuperGLUE, or HELM, cover a wide range of tasks and scenarios → They do this by designing or collecting datasets that test specific aspects of an LLM. •
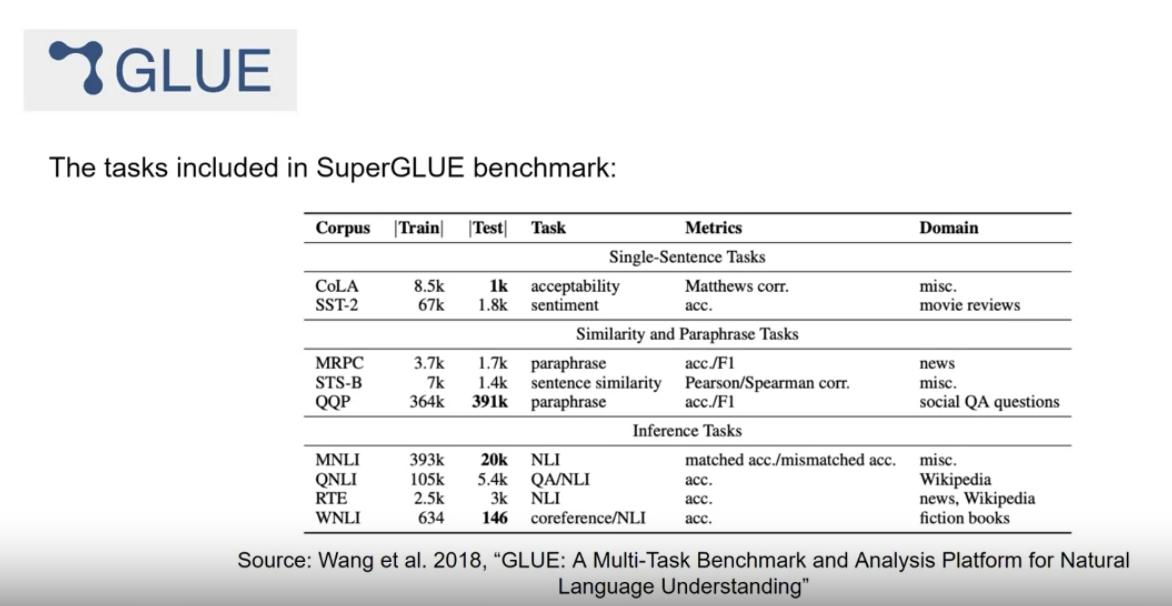
1.7.1. GLUE• GLUE (General Language Understanding Evaluation) → was introduced in 2018.• • GLUE is a collection of natural language tasks, such as sentiment analysis and question-answering. • • GLUE was created to encourage the development of models that can generalize across multiple tasks, and you can use the benchmark to measure and compare the model performance.
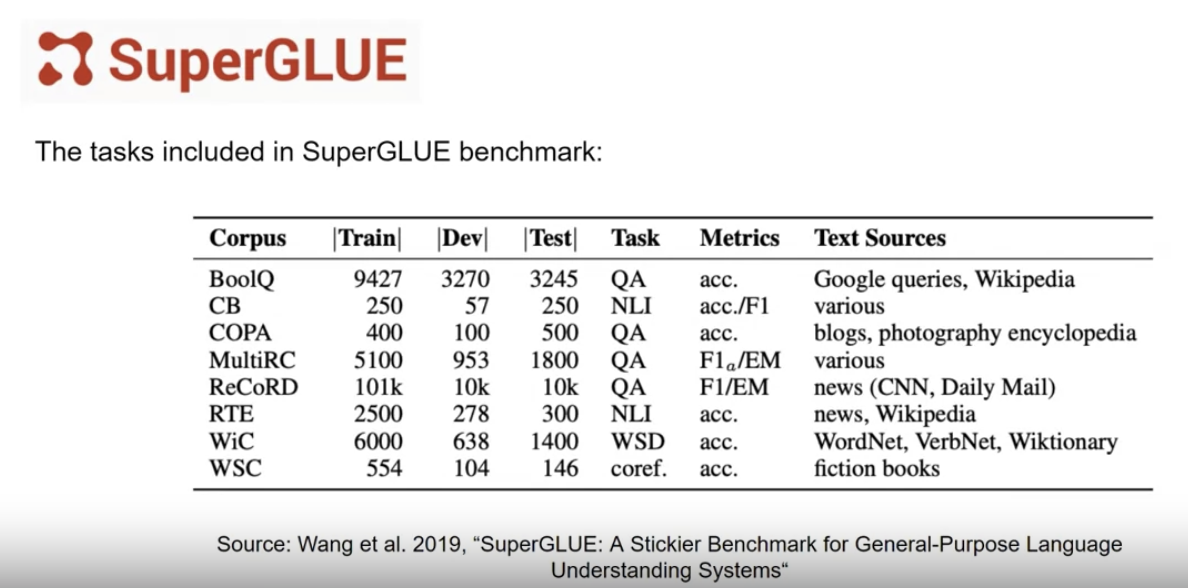
1.7.2. SuperGLUE• As a successor to GLUE, SuperGLUE was introduced in 2019, to address limitations in its predecessor. • • It consists of a series of tasks, some of which are not included in GLUE, and some of which are more challenging versions of the same tasks. • • SuperGLUE includes tasks such as multi-sentence reasoning, and reading comprehension.
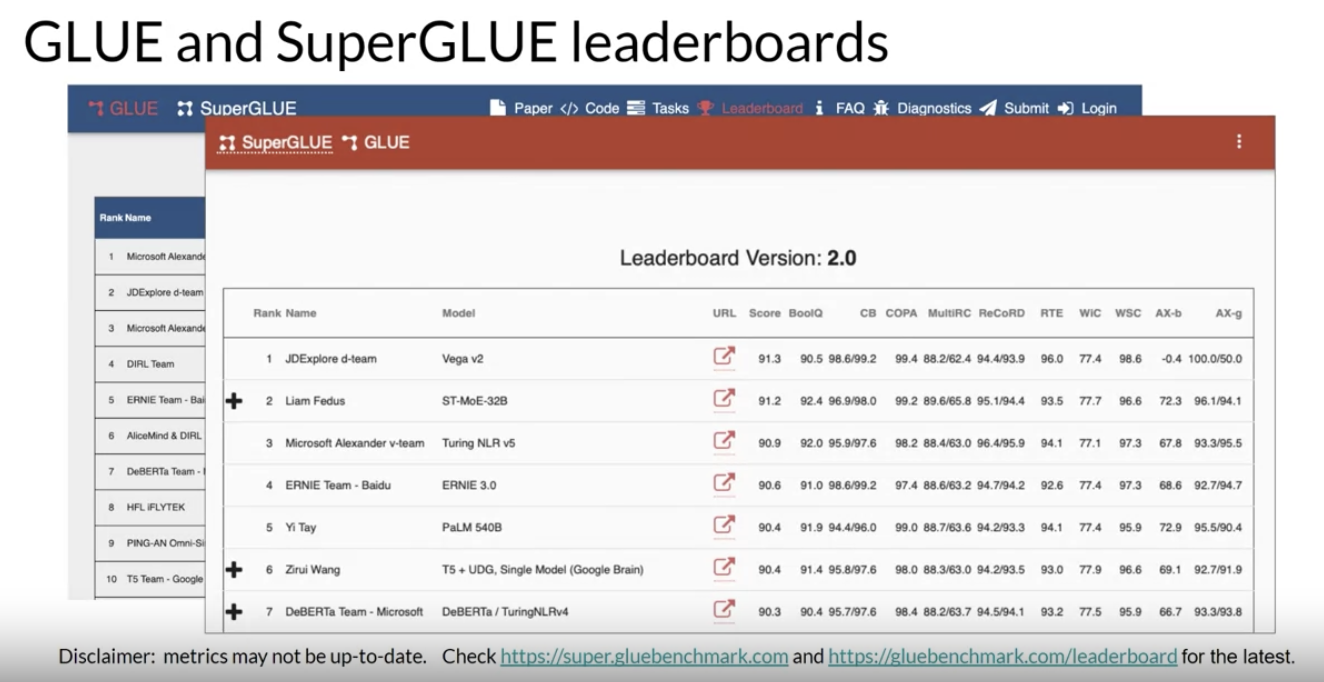
• • Both the GLUE and SuperGLUE benchmarks have leaderboards that can be used to compare and contrast evaluated models.
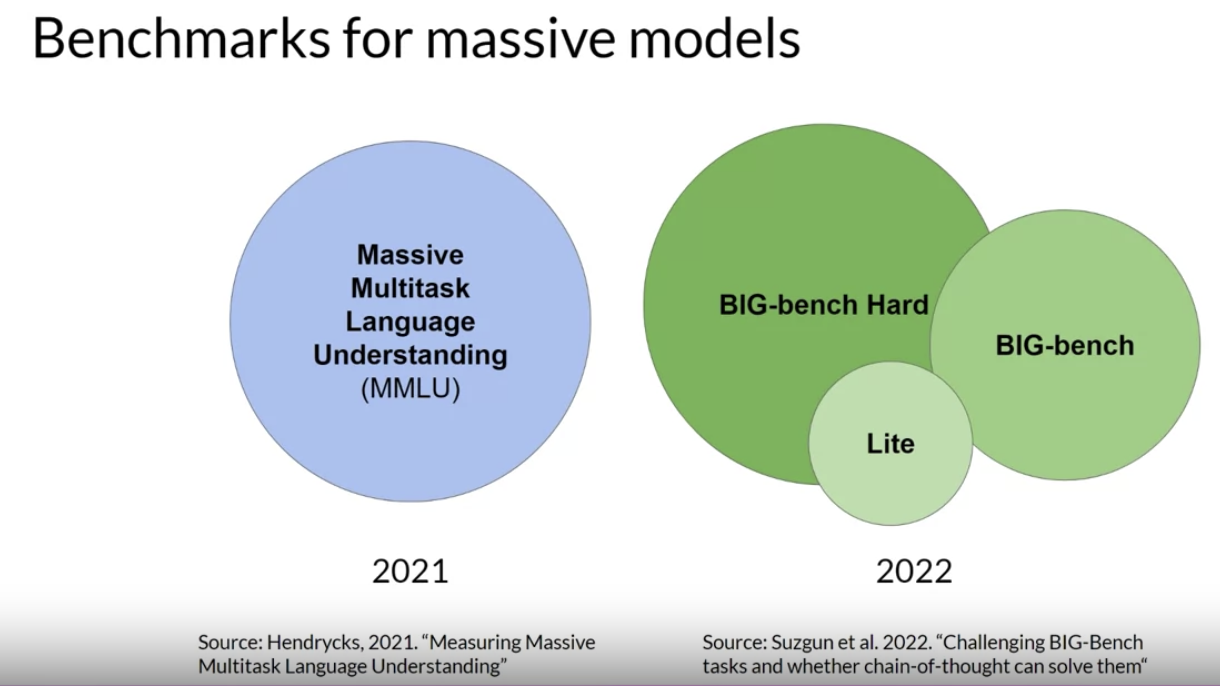
• • The results page is another great resource for tracking the progress of LLMs. 1.7.3. MMLU• • As models get larger, their performance against benchmarks such as SuperGLUE start to match human ability on specific tasks.• – That's to say that models are able to perform as well as humans on the benchmarks tests, but subjectively we can see that they're not performing at human level at tasks in general.– – There is essentially an arms race between the emergent properties of LLMs, and the benchmarks that aim to measure them. Here are a couple of recent benchmarks that are pushing LLMs further. – ❏ Massive Multitask Language Understanding (MMLU) → is designed specifically for modern LLMs. · To perform well models must possess extensive world knowledge and problem-solving ability.· Models are tested on elementary mathematics, US history, computer science, law, and more. → tasks that extend way beyond basic language understanding.1.7.4. BIG-Bench• BIG-bench currently consists of 204 tasks, ranging through linguistics, childhood development, math, common sense reasoning, biology, physics, social bias, software development and more. • BIG-bench comes in three different sizes, and part of the reason for this is to keep costs achievable, as running these large benchmarks can incur large inference costs. •
1.7.5. HELM• Holistic Evaluation of Language Models (HELM) → The HELM framework aims to improve the transparency of models, and to offer guidance on which models perform well for specific tasks. • HELM takes a multimetric approach, measuring seven metrics across 16 core scenarios, ensuring that trade-offs between models and metrics are clearly exposed.• NOTE → One important feature of HELM is that it assesses on metrics beyond basic accuracy measures, like precision of the F1 score.• The benchmark also includes metrics for fairness, bias, and toxicity, which are becoming increasingly important to assess as LLMs become more capable of human-like language generation, and in turn of exhibiting potentially harmful behavior.• HELM is a living benchmark that aims to continuously evolve with the addition of new scenarios, metrics, and models.•
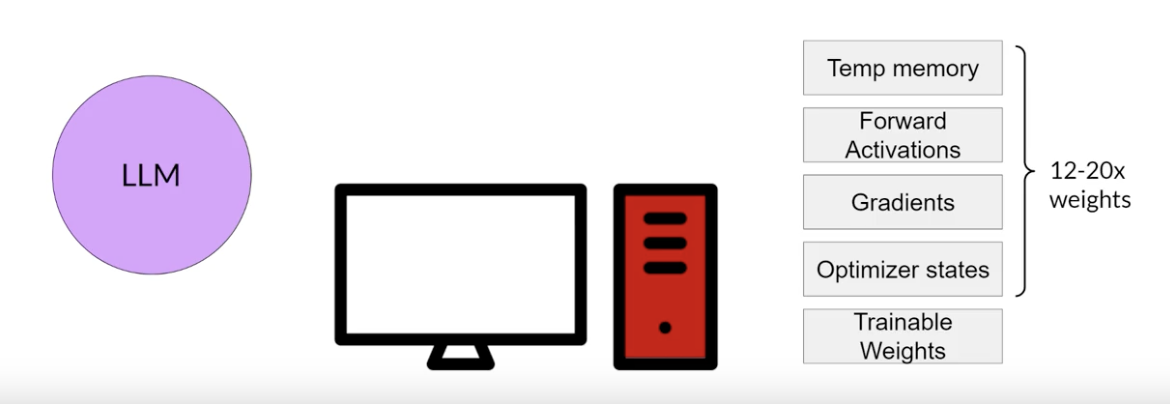
Back To Top2. Parameter Efficient Fine-Tuning (PEFT)2.1. Introduction• Training LLMs is computationally intensive. Full fine-tuning requires memory not just to store the model, but various other parameters that are required during the training process.
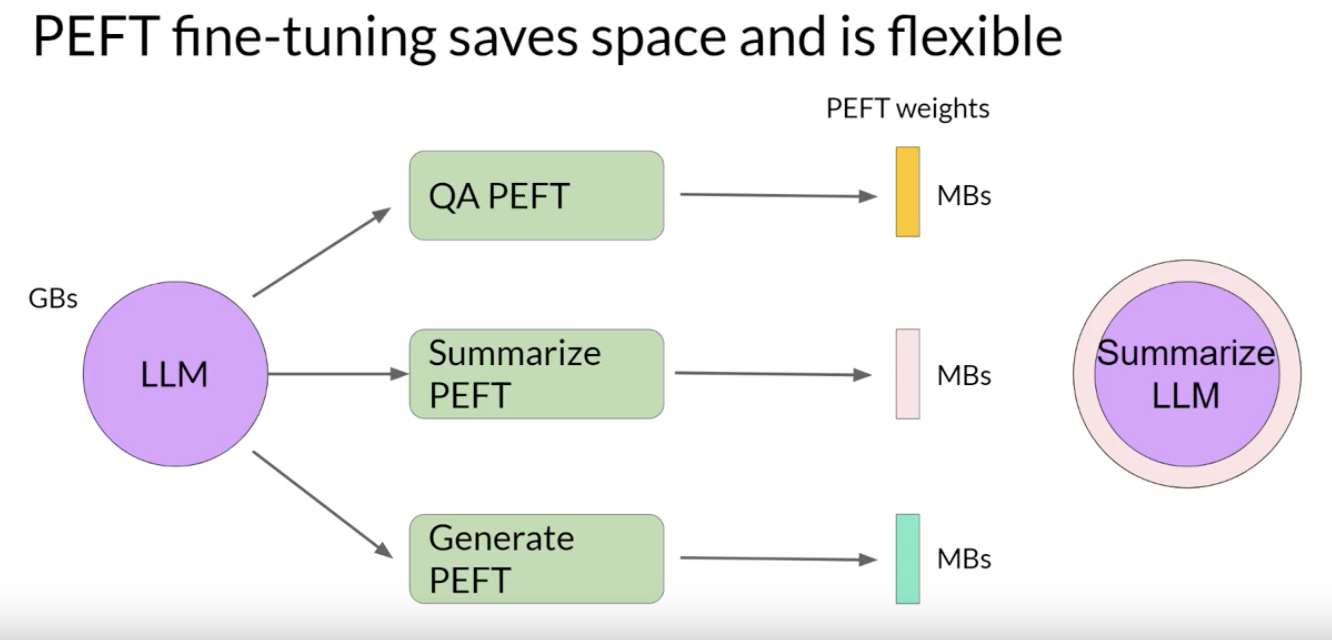
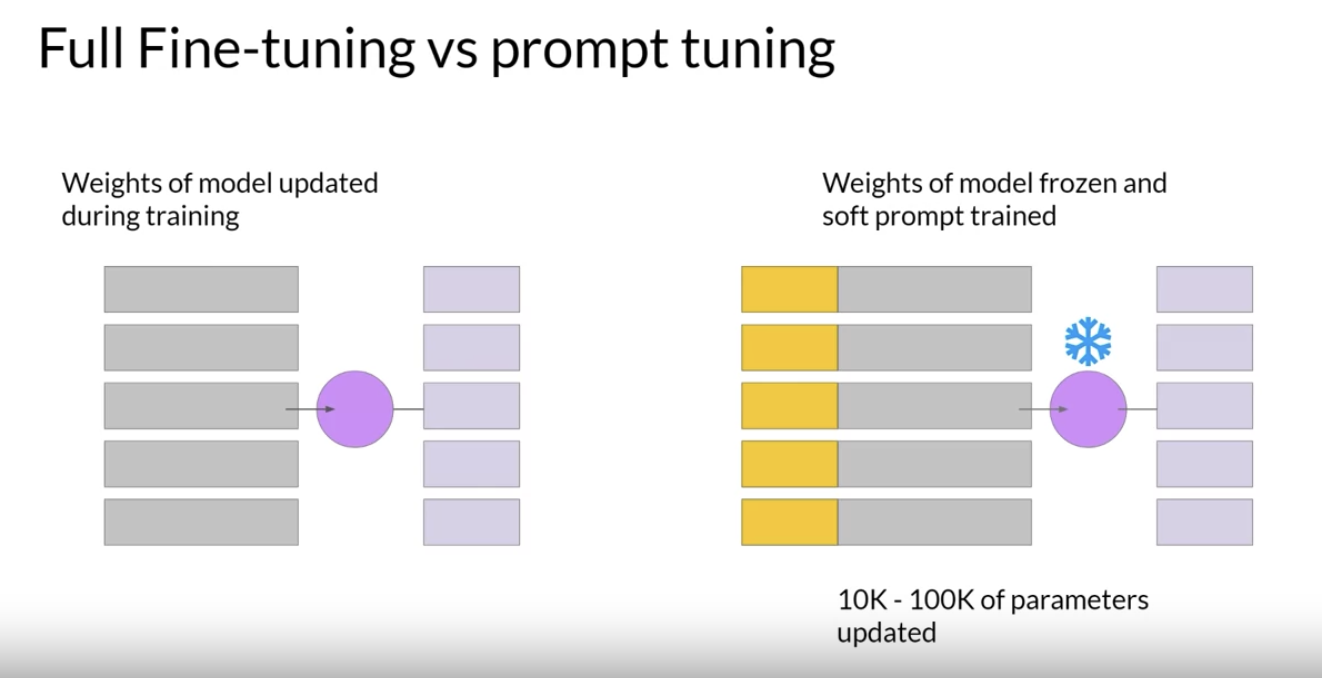
• In contrast to full fine-tuning where every model weight is updated during supervised learning, parameter efficient fine tuning methods only update a small subset of parameters.• – Some techniques freeze most of the model weights and focus on fine tuning a subset of existing model parameters, for example, particular layers or components.– Other techniques don't touch the original model weights at all, and instead add a small number of new parameters or layers and fine-tune only the new components.• With PEFT, most if not all of the LLM weights are kept frozen. As a result, the number of trained parameters is much smaller than the number of parameters in the original LLM. • – In some cases, just 15-20% of the original LLM weights. – PEFT can often be performed on a single GPU.– – Because the original LLM is only slightly modified or left unchanged, PEFT is less prone to the catastrophic forgetting problems of full fine-tuning.• Full fine-tuning results in a new version of the model for every task you train on. – Each of these is the same size as the original model, so it can create an expensive storage problem if you're fine-tuning for multiple tasks. – Let's see how you can use PEFT to improve the situation.Back To TopPEFT is Flexible• With parameter efficient fine-tuning, you train only a small number of weights, which results in a much smaller footprint overall, as small as megabytes depending on the task. • – The new parameters are combined with the original LLM weights for inference.– – The PEFT weights are trained for each task and can be easily swapped out for inference, allowing efficient adaptation of the original model to multiple tasks.
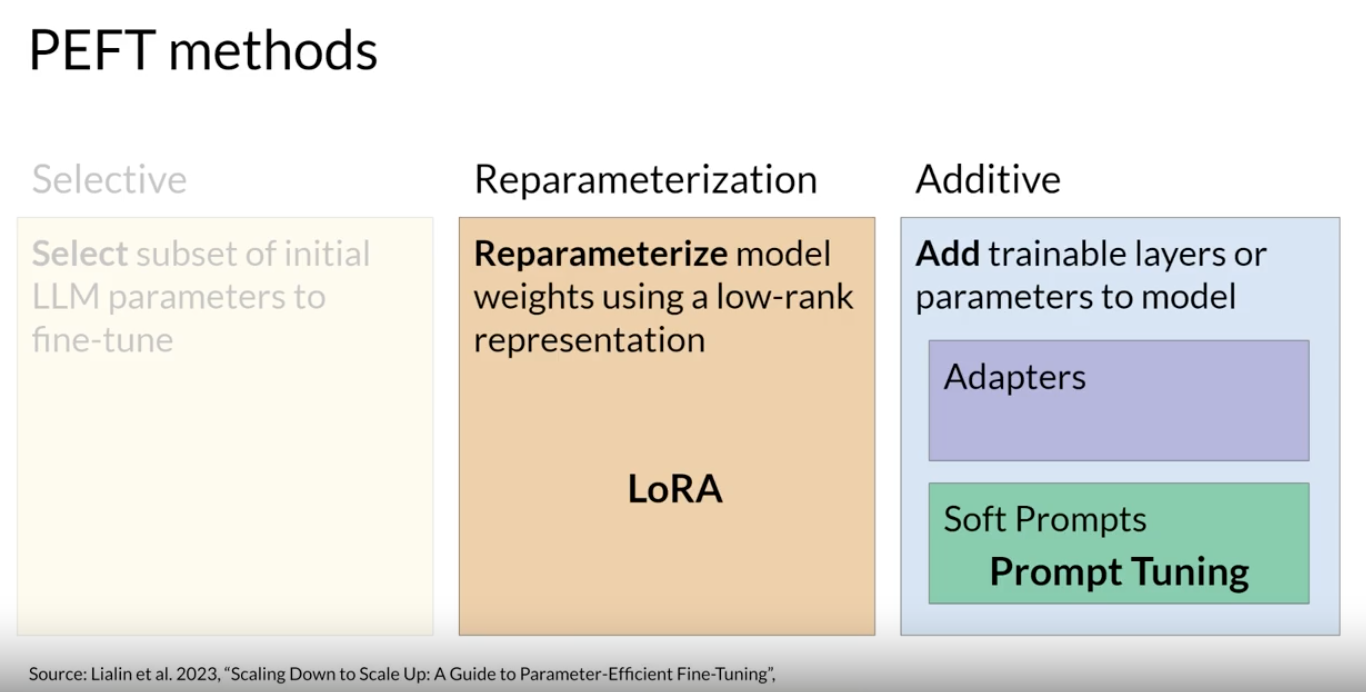
• There are several methods for PEFT, each with trade-offs on: ❏ parameter efficiency ❏ memory efficiency ❏ training speed❏ model quality ❏ inference costsBack To Top2.1.1. Three Classes of PEFT Methods• Selective methods are those that fine-tune only a subset of the original LLM parameters.• – There are several approaches that you can take to identify which parameters you want to update. – * You have the option to train only certain components of the model or specific layers, or even individual parameter types. * Researchers have found that the performance of these methods is mixed and there are significant trade-offs between parameter efficiency and compute efficiency. – • Reparameterization methods also work with the original LLM parameters, but reduce the number of parameters to train by creating new low rank transformations of the original network weights. A commonly used technique of this type is LoRA.• • Additive methods carry out fine-tuning by keeping all of the original LLM weights frozen and introducing new trainable components. • – Here there are two main approaches. – * Adapter methods add new trainable layers to the architecture of the model, typically inside the encoder or decoder components after the attention or feed-forward layers. * * Soft prompt methods, on the other hand, keep the model architecture fixed and frozen, and focus on manipulating the input to achieve better performance. · This can be done by adding trainable parameters to the prompt embeddings or keeping the input fixed and retraining the embedding weights. → In this course, we'll focus on a specific method called Prompt Tuning.
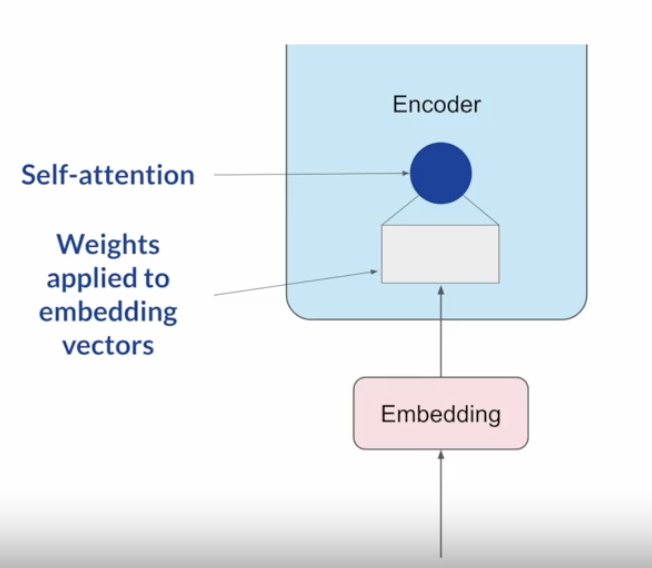
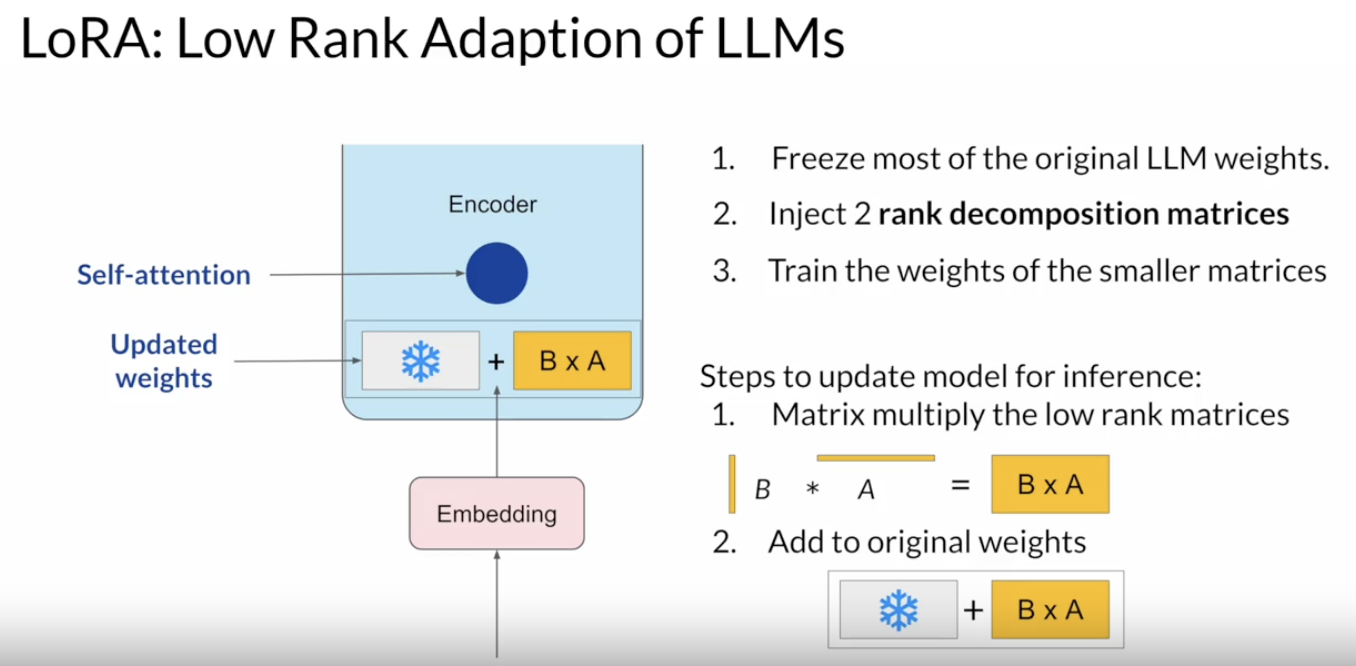
Back To Top2.2. PEFT Techniques 1: LoRA• Low-rank Adaptation (LoRA) → is a parameter-efficient fine-tuning technique that falls into the re-parameterization category.• Remember from the transformer architecture that embeddings have learned weights.
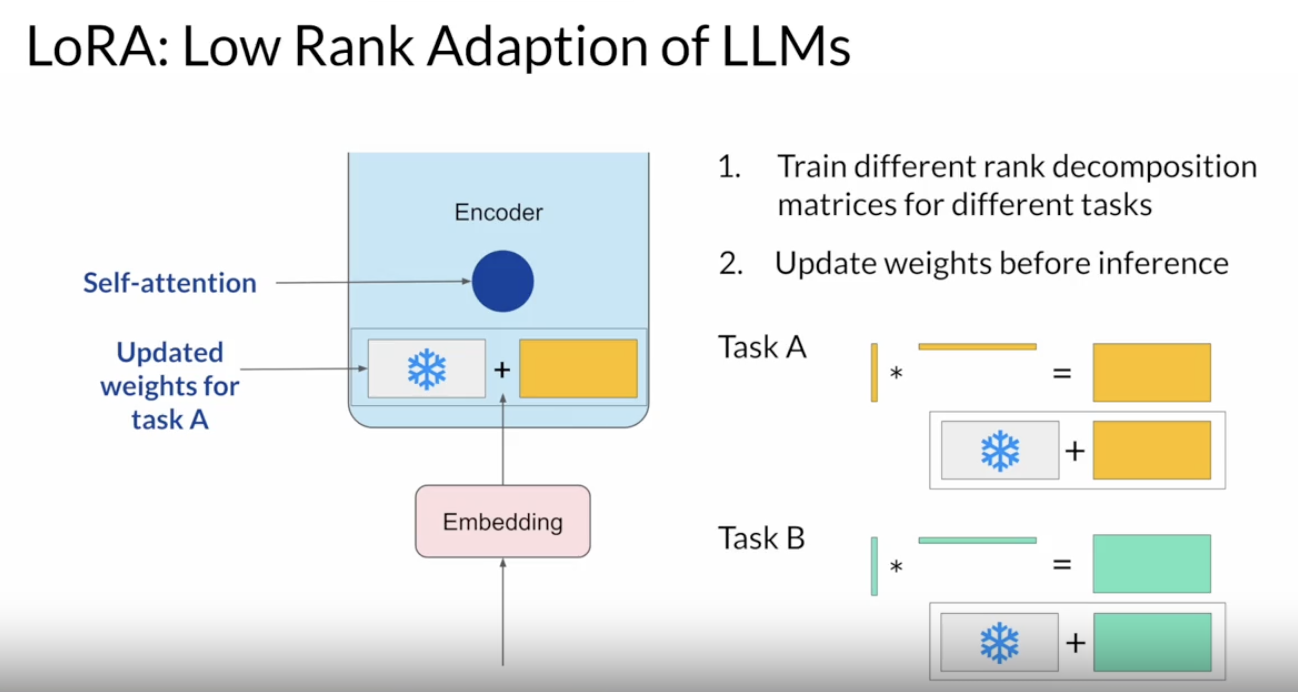
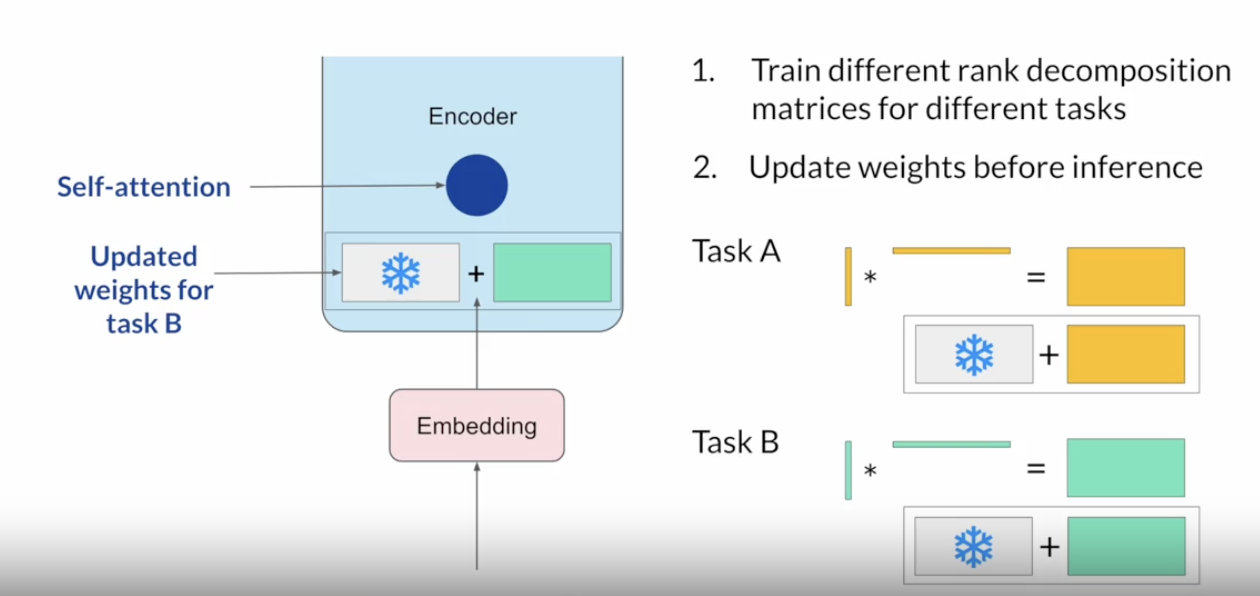
• The weights of these networks are learned during pre-training. After the embedding vectors are created, they're fed into the self-attention layers where a series of weights are applied to calculate the attention scores. – During full fine-tuning, every parameter in these layers is updated. • LoRA is a strategy that reduces the number of parameters to be trained during fine-tuning by freezing all of the original model parameters and then injecting a pair of rank decomposition matrices alongside the original weights. • – The dimensions of the smaller matrices are set so that their product is a matrix with the same dimensions as the weights they're modifying.– – You then keep the original weights of the LLM frozen and train the smaller matrices using the same supervised learning process you saw earlier.– – For inference, the two low-rank matrices are multiplied together to create a matrix with the same dimensions as the frozen weights. You then add this to the original weights and replace them in the model with these updated values.– – You now have a LoRA fine-tuned model that can carry out your specific task. – – Because this model has the same number of parameters as the original, there is little to no impact on inference latency.– – Researchers have found that applying LoRA to just the self-attention layers of the model is often enough to fine-tune for a task and achieve performance gains.– * → However, in principle, you can also use LoRA on other components like the feed-forward layers.· → But since most of the parameters of LLMs are in the attention layers, you get the biggest savings in trainable parameters by applying LoRA to these weights matrices.• –
Back To Top2.2.1. LoRA: Practical Example• The original transformer paper specifies that the transformer weights have dimensions of 512 x 64.• – This means that each weights matrix has 32,768 trainable parameters. – – If you use LoRA as a fine-tuning method with the rank equal to eight, you will instead train two small rank decomposition matrices whose small dimension is eight. – * This means that Matrix A will have dimensions of 8 x 64, resulting in 512 total parameters. * Matrix B will have dimensions of 512 x 8, or 4,096 trainable parameters.• By updating the weights of these new low-rank matrices instead of the original weights, you'll be training 4,608 parameters instead of 32,768 and 86% reduction.
• With LoRA you often can train on a single GPU and avoid the need for a distributed cluster of GPUs.• Since the rank-decomposition matrices are small, you can fine-tune a different set for each task and then switch them out at inference time by updating the weights.• – In principle, you can use LoRA to train for many tasks.– Switch out the weights when you need to use them, and avoid having to store multiple full-size versions of the LLM.
Figure 3:Swapping weights for Task A and Task B
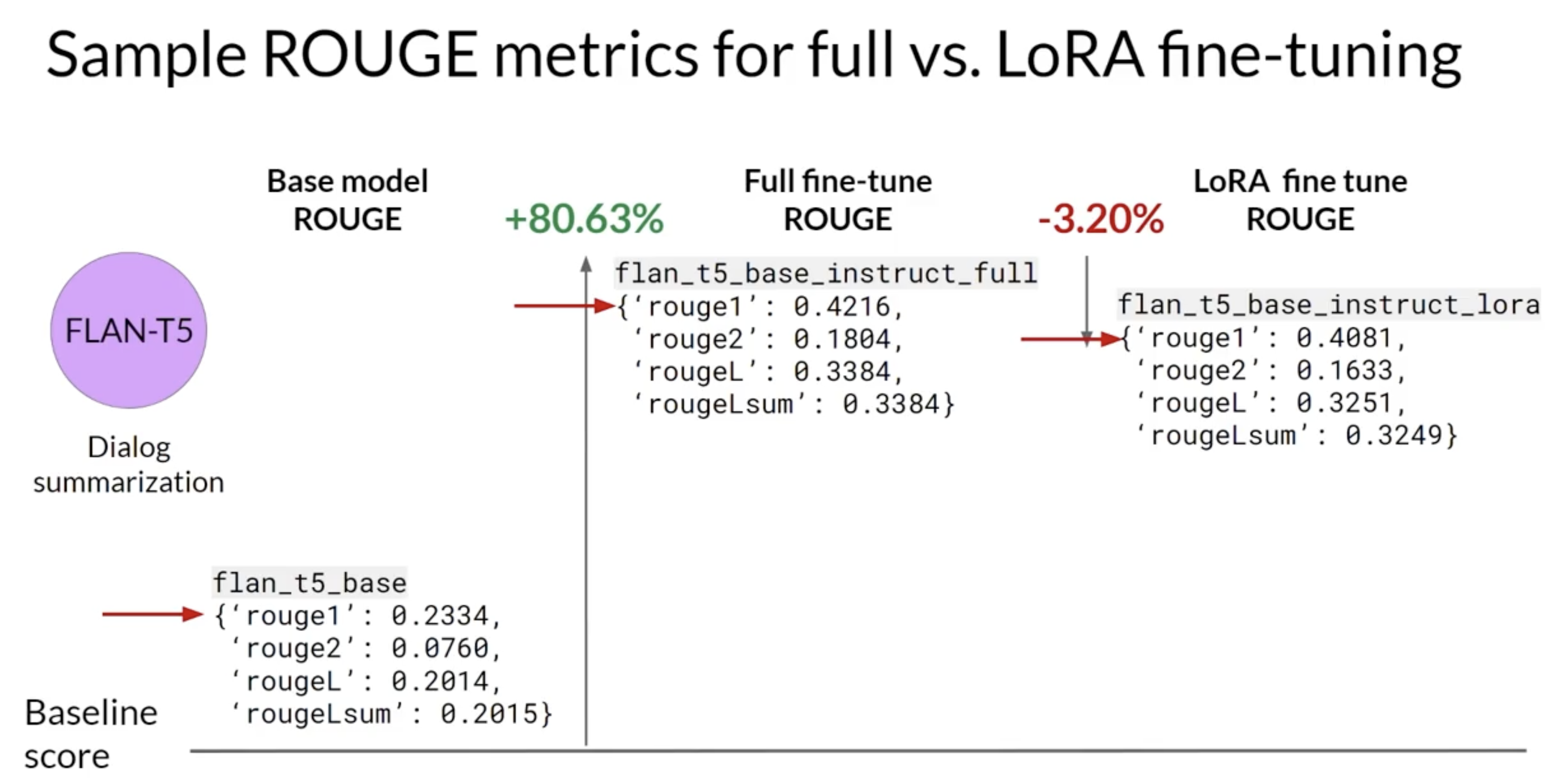
2.2.2. How Good are LoRA Fine-tuned Models?• Let's use ROUGE metric to compare the performance of a LoRA fine-tune model to both an original base model and a full fine-tuned version.– Higher number indicate better performance.– We focus on ROUGE-1 for this discussion.– Let's also use FLAN-T5 model.
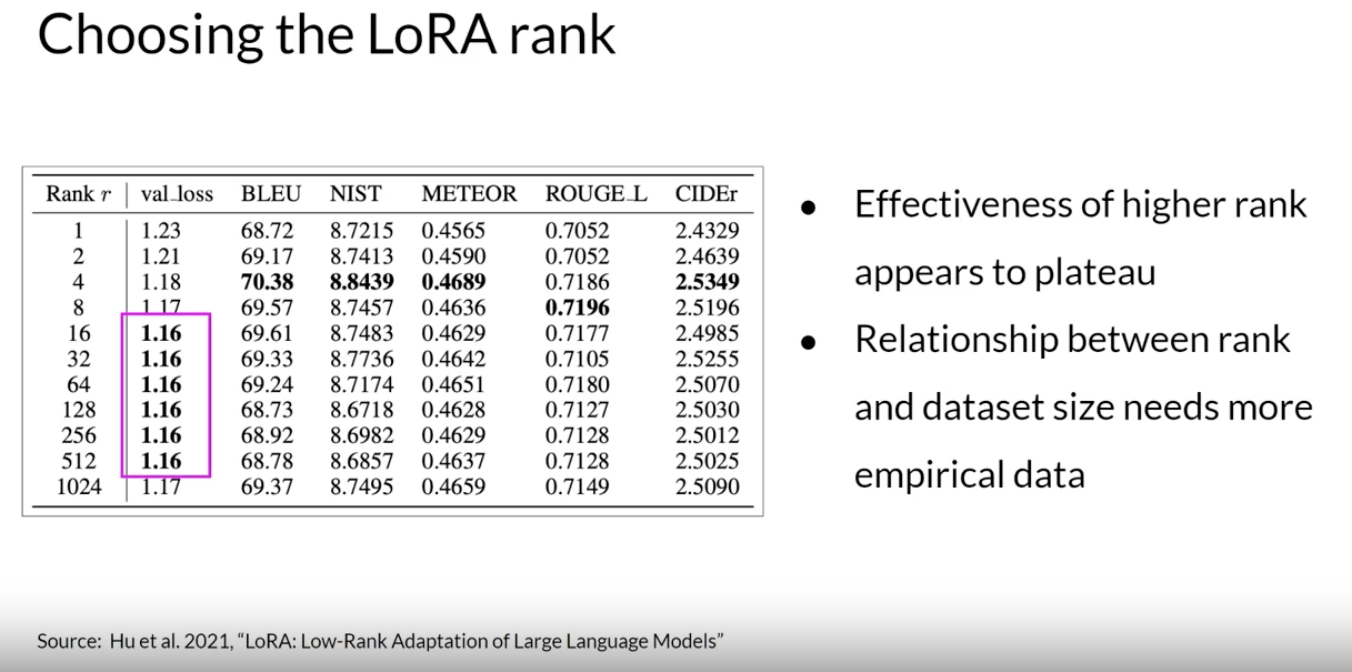
Back To Top2.2.3. How to choose the rank of the LoRA matrices?• This is an active area of research as of August 2023.• In principle, the smaller the rank, the smaller the number of trainable parameters, and the bigger the savings on compute.• – However, there are some issues related to model performance to consider. – * In the paper that first proposed LoRA, researchers at Microsoft explored how different choices of rank impacted the model performance on language generation tasks.* · You can see the summary of the results in the table below. · · The bold values indicate the best scores that were achieved for each metric. · · The authors found a plateau in the loss value for ranks greater than 16. In other words, using larger LoRA matrices didn't improve performance. · · The takeaway here is that ranks in the range of 4-32 can provide you with a good trade-off between reducing trainable parameters and preserving performance. · · Optimizing the choice of rank is an ongoing area of research and best practices may evolve as more practitioners like you make use of LoRA.
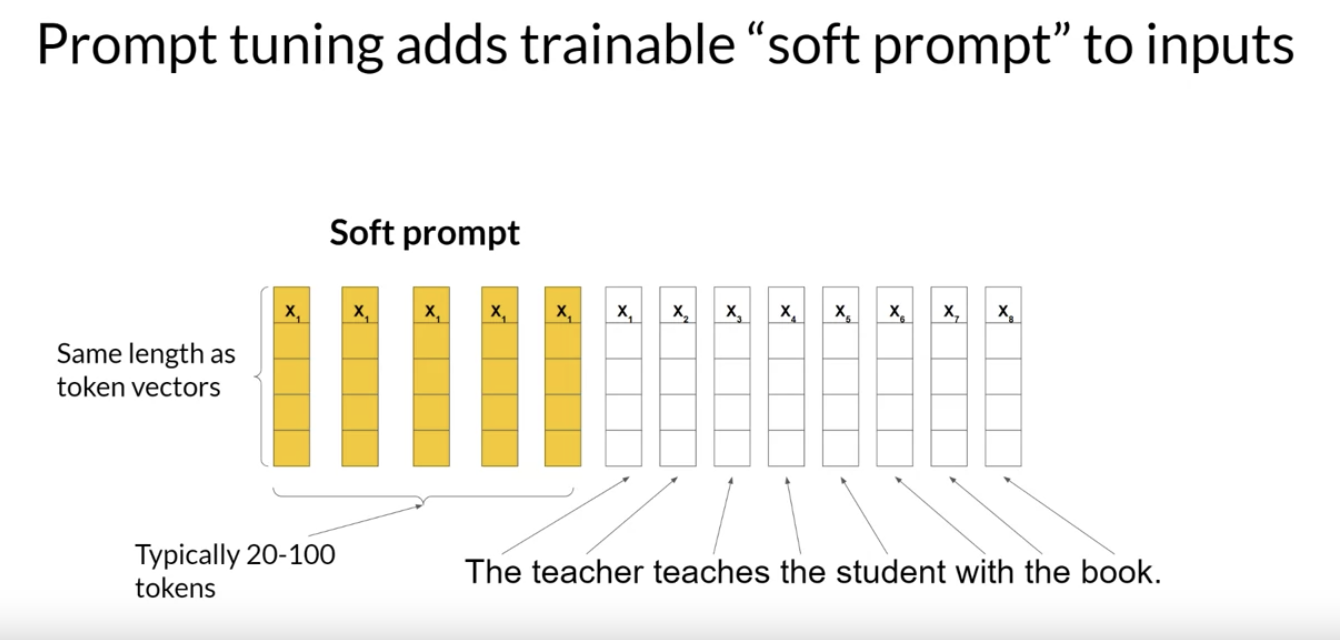
• LoRA is a powerful fine-tuning method that achieves great performance. The principles behind the method are useful not just for training LLMs, but for models in other domains.• LoRA is broadly used in practice because of the comparable performance to full fine tuning for many tasks and data sets.• QLoRA → LoRA + Quantization• Back To Top2.3. PEFT Techniques 2: Soft Prompts• Prompt tuning sounds a bit like prompt engineering, but they are quite different from each other. • – With prompt engineering, you work on the language of your prompt to get the completion you want. – * This could be as simple as trying different words or phrases or more complex, like including examples for one or Few-shot Inference. * * The goal is to help the model understand the nature of the task you're asking it to carry out and to generate a better completion. * * There are some limitations to prompt engineering, as it can require a lot of manual effort to write and try different prompts.* * You're also limited by the length of the context window, and at the end of the day, you may still not achieve the performance you need for your task.* – With prompt tuning, you add additional trainable tokens to your prompt and leave it up to the supervised learning process to determine their optimal values.– * The set of trainable tokens is called a soft prompt, and it gets prepended to embedding vectors that represent your input text. * The soft prompt vectors have the same length as the embedding vectors of the language tokens.* And including somewhere between 20 and 100 virtual tokens can be sufficient for good performance.*
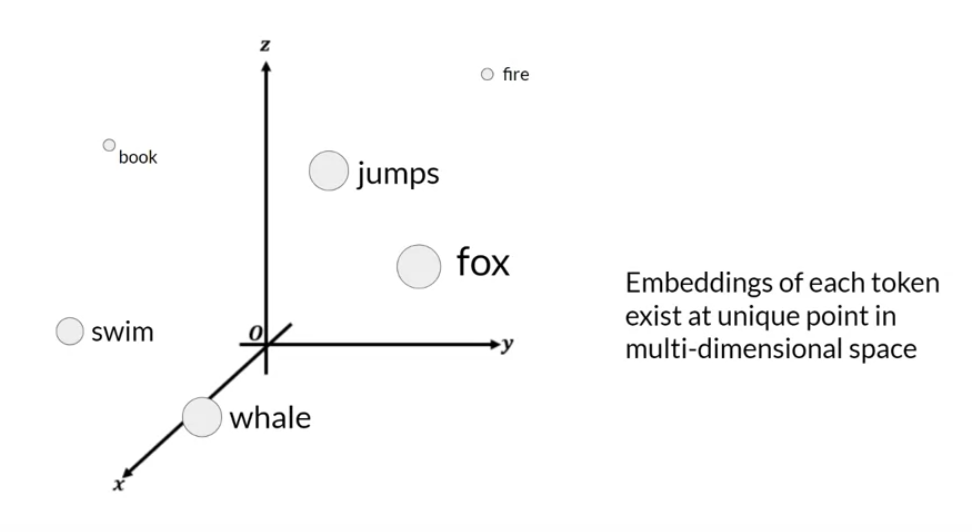
• – The tokens that represent natural language are hard in the sense that they each correspond to a fixed location in the embedding vector space.*
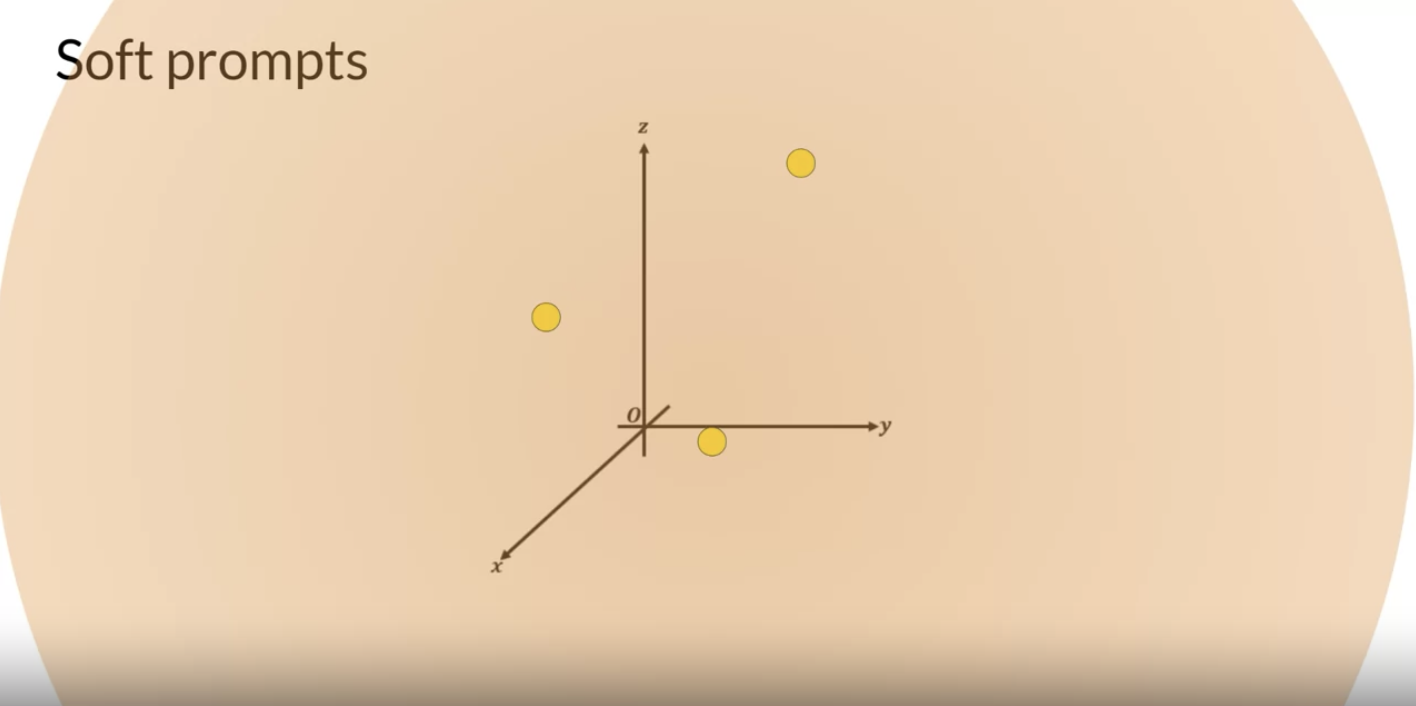
• – * However, the soft prompts are not fixed discrete words of natural language.· Instead, you can think of them as virtual tokens that can take on any value within the continuous multidimensional embedding space. · And through supervised learning, the model learns the values for these virtual tokens that maximize performance for a given task.
• In full fine tuning, the training data set consists of input prompts and output completions or labels.• In contrast with prompt tuning, the weights of the large language model are frozen and the underlying model does not get updated. – Instead, the embedding vectors of the soft prompt gets updated over time to optimize the model's completion of the prompt.
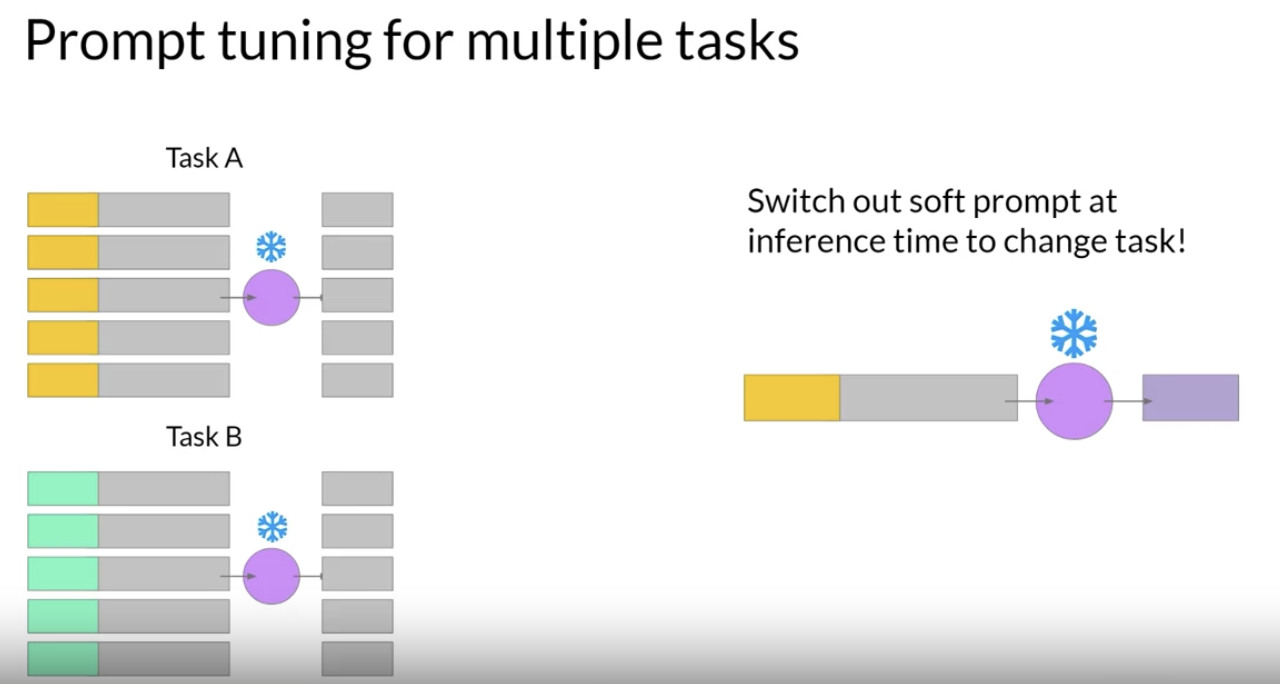
• Prompt tuning is a very parameter efficient strategy because only a few parameters are being trained.• Similar to LoRA, you can train a different set of soft prompts for each task and then easily swap them out at inference time.– To use them for inference, you prepend your input prompt with the learned tokens.– To switch to another task, you simply change the soft prompt.
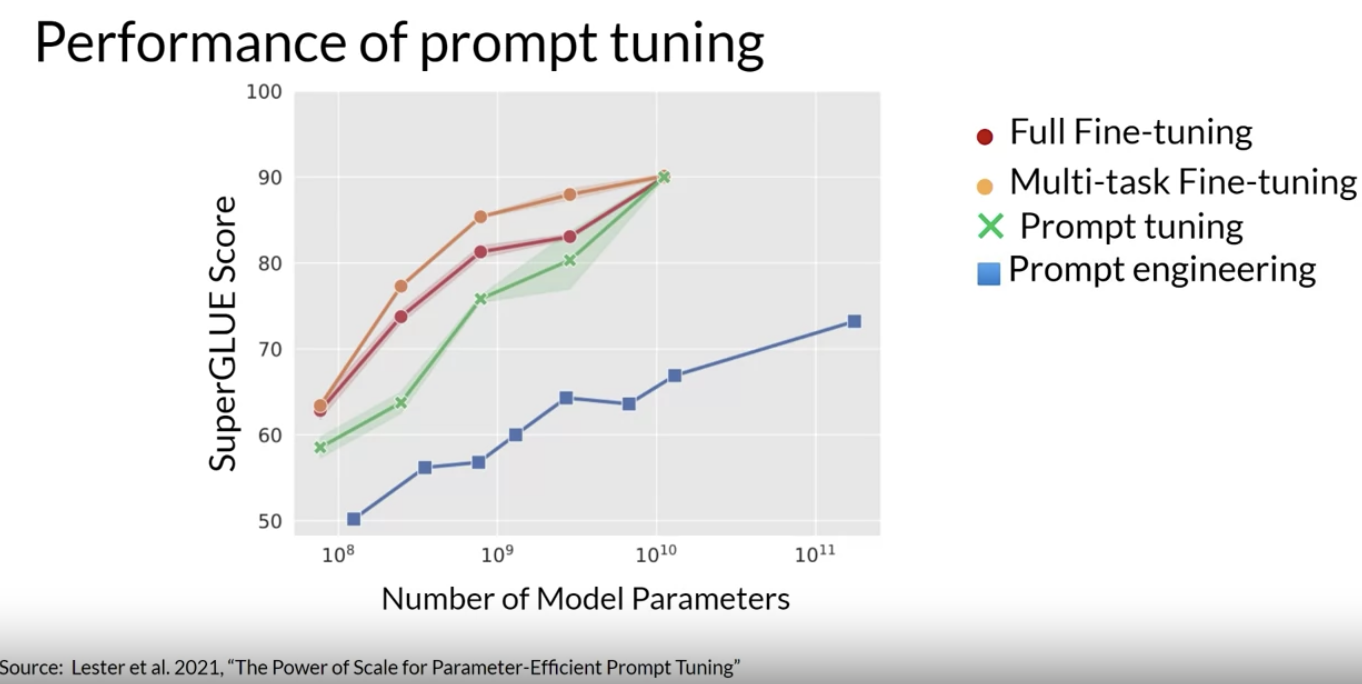
• Soft prompts are very small on disk, so this kind of fine tuning is extremely efficient and flexible. 2.3.1. How well does prompt tuning perform?• In the original paper, the authors compared prompt tuning to several other methods for a range of model sizes.
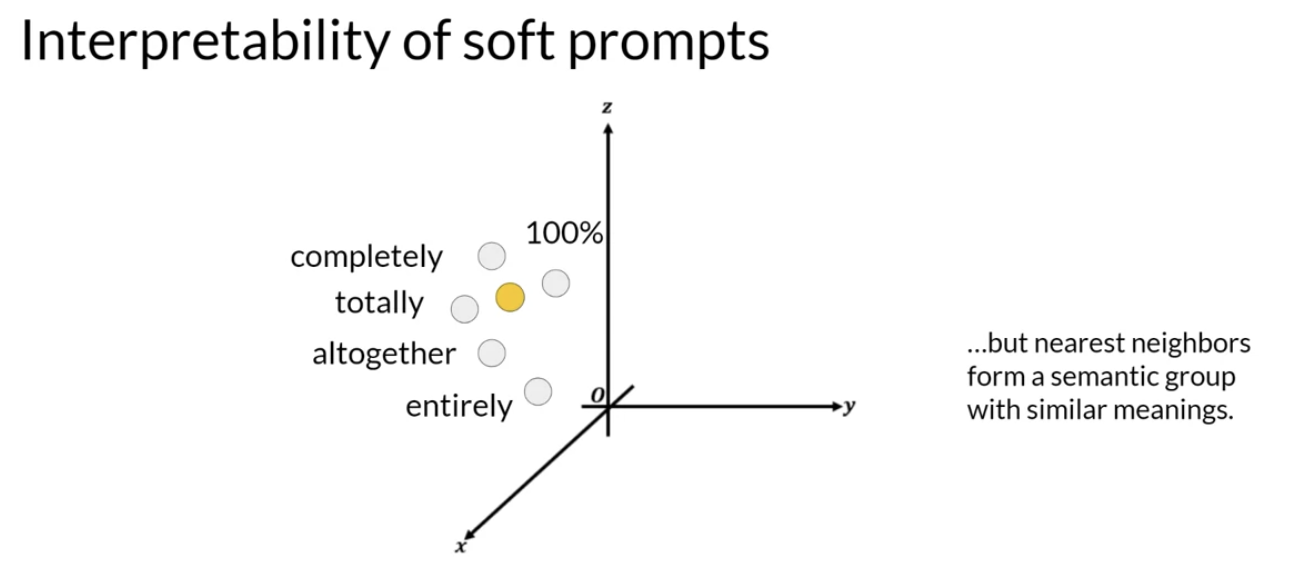
• Prompt tuning doesn't perform as well as full fine tuning for smaller LLMs.• As the model size increases, so does the performance of prompt tuning.– Once models have around 10 billion parameters, prompt tuning can be as effective as full fine tuning and offers a significant boost in performance over prompt engineering alone.2.3.2. Interpretability of Soft Prompts• One potential issue to consider is the interpretability of learned virtual tokens.• – Because the soft prompt tokens can take any value within the continuous embedding vector space, the trained tokens don't correspond to any known token, word, or phrase in the vocabulary of the LLM. – – However, an analysis of the nearest neighbor tokens to the soft prompt location shows that they form tight semantic clusters. → i.e., the words closest to the soft prompt tokens have similar meanings.
Back To Top3. Additional Reading3.1. Multi-task, instruction fine-tuning• Scaling Instruction-Finetuned Language Models: Scaling fine-tuning with a focus on task, model size and chain-of-thought data.• • Introducing FLAN: More generalizable Language Models with Instruction Fine-Tuning: This blog (and article) explores instruction fine-tuning, which aims to make language models better at performing NLP tasks with zero-shot inference.3.1.1. Model Evaluation Metrics• HELM - Holistic Evaluation of Language Models: HELM is a living benchmark to evaluate Language Models more transparently. • • General Language Understanding Evaluation (GLUE) benchmark: This paper introduces GLUE, a benchmark for evaluating models on diverse natural language understanding (NLU) tasks and emphasizing the importance of improved general NLU systems.• • SuperGLUE: This paper introduces SuperGLUE, a benchmark designed to evaluate the performance of various NLP models on a range of challenging language understanding tasks.• • ROUGE: A Package for Automatic Evaluation of Summaries: This paper introduces and evaluates four different measures (ROUGE-N, ROUGE-L, ROUGE-W, and ROUGE-S) in the ROUGE summarization evaluation package, which assess the quality of summaries by comparing them to ideal human-generated summaries.• • Measuring Massive Multitask Language Understanding (MMLU): This paper presents a new test to measure multitask accuracy in text models, highlighting the need for substantial improvements in achieving expert-level accuracy and addressing lopsided performance and low accuracy on socially important subjects.• • BigBench-Hard - Beyond the Imitation Game: Quantifying and Extrapolating the Capabilities of Language Models: The paper introduces BIG-bench, a benchmark for evaluating language models on challenging tasks, providing insights on scale, calibration, and social bias.3.1.2. Parameter- efficient fine tuning (PEFT)• Scaling Down to Scale Up: A Guide to Parameter-Efficient Fine-Tuning: This paper provides a systematic overview of Parameter-Efficient Fine-tuning (PEFT) Methods in all three categories discussed in the lecture videos.• • On the Effectiveness of Parameter-Efficient Fine-Tuning: The paper analyzes sparse fine-tuning methods for pre-trained models in NLP.3.1.3. LoRA• LoRA Low-Rank Adaptation of Large Language Models: This paper proposes a parameter-efficient fine-tuning method that makes use of low-rank decomposition matrices to reduce the number of trainable parameters needed for fine-tuning language models.• • QLoRA: Efficient Finetuning of Quantized LLMs: This paper introduces an efficient method for fine-tuning large language models on a single GPU, based on quantization, achieving impressive results on benchmark tests.3.1.4. Prompt tuning with soft prompts• The Power of Scale for Parameter-Efficient Prompt Tuning: The paper explores "prompt tuning," a method for conditioning language models with learned soft prompts, achieving competitive performance compared to full fine-tuning and enabling model reuse for many tasks.Back To Top