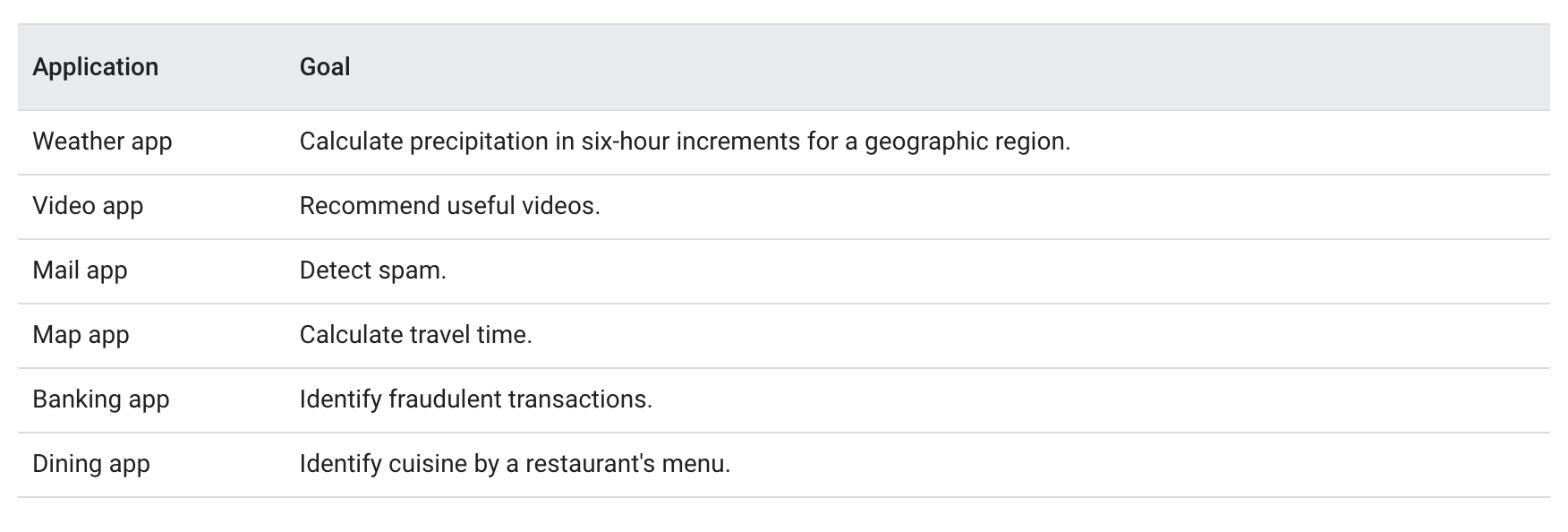
Source1. Problem Framing• Problem framing is the process of analyzing a problem to isolate the individual elements that need to be addressed to solve it. • Problem framing helps determine your project's technical feasibility and provides a clear set of goals and success criteria. When considering an ML solution, effective problem framing can determine whether or not your product ultimately succeeds.• Formal problem framing is the critical beginning for solving an ML problem, as it forces us to better understand both the problem and the data in order to design and build a bridge between them. - TensorFlow engineer• At a high level, ML problem framing consists of two distinct steps:– Determining whether ML is the right approach for solving a problem.– Framing the problem in ML terms.1.1. Understanding the problem• To understand the problem, perform the following tasks:– State the goal for the product you are developing or refactoring.– Determine whether the goal is best solved using ML.– Verify you have the data required to train a model.1.1.1. State the goal• Begin by stating your goal in non-ML terms. The goal is the answer to the question, "What am I trying to accomplish?"• The following table clearly states goals for hypothetical apps:
1.1.2. Clear use case for ML• ML is a specialized tool suitable only for particular problems. You don't want to implement a complex ML solution when a simpler non-ML solution will work.• To confirm that ML is the right approach, first verify that your current non-ML solution is optimized.• If you don't have a non-ML solution implemented, try solving the problem manually using a heuristic.• The non-ML solution is the benchmark you'll use to determine whether ML is a good use case for your problem.• • Consider the following questions when comparing a non-ML approach to an ML one:– Quality:How much better do you think an ML solution can be? If you think an ML solution might be only a small improvement, that might indicate the current solution is the best one.– Cost and maintenance: How expensive is the ML solution in both the short- and long-term? In some cases, it costs significantly more in terms of compute resources and time to implement ML. Consider the following questions:* Can the ML solution justify the increase in cost? Note that small improvements in large systems can easily justify the cost and maintenance of implementing an ML solution.* How much maintenance will the solution require? In many cases, ML implementations need dedicated long-term maintenance.1.1.3. Data• Your data should have the following characteristics:– Abundant. The more relevant and useful examples in your dataset, the better your model will be.– Consistent and reliable. Having data that's consistently and reliably collected will produce a better model. For example, an ML-based weather model will benefit from data gathered over many years from the same reliable instruments.– Trusted. Understand where your data will come from. Will the data be from trusted sources you control, like logs from your product, or will it be from sources you don't have much insight into, like the output from another ML system?– Available. Make sure all inputs are available at prediction time in the correct format. If it will be difficult to obtain certain feature values at prediction time, omit those features from your datasets.– Correct. In large datasets, it's inevitable that some labels will have incorrect values, but if more than a small percentage of labels are incorrect, the model will produce poor predictions.– Representative. The datasets should be as representative of the real world as possible.• Predictive Power– For a model to make good predictions, the features in your dataset should have predictive power. The more correlated a feature is with a label, the more likely it is to predict it.– Some features will have more predictive power than others. For example, in a weather dataset, features such as cloud_coverage, temperature, and dew_point would be better predictors of rain than moon_phase or day_of_week. For the video app example, you could hypothesize that features such as video_description, length and views might be good predictors for which videos a user would want to watch.– Be aware that a feature's predictive power can change because the context or domain changes. For example, in the video app, a feature like upload_date might—in general—be weakly correlated with the label. However, in the sub-domain of gaming videos, upload_date might be strongly correlated with the label.– Determining which features have predictive power can be a time consuming process. You can manually explore a feature's predictive power by removing and adding it while training a model. You can automate finding a feature's predictive power by using algorithms such as Pearson correlation, Adjusted mutual information (AMI), and Shapley value, which provide a numerical assessment for analyzing the predictive power of a feature.1.1.4. Predictions vs. actions• There's no value in predicting something if you can't turn the prediction into an action that helps users. That is, your product should take action from the model's output.– For example, a model that predicts whether a user will find a video useful should feed into an app that recommends useful videos. A model that predicts whether it will rain should feed into a weather app.– 1.2. Framing an ML Problem• You frame a problem in ML terms by completing the following tasks:– Define the ideal outcome and the model's goal.– Identify the model's output.– Define success metrics.1.2.1. Define the ideal outcome and the model's goal• Independent of the ML model, what's the ideal outcome? In other words, what is the exact task you want your product or feature to perform? This is the same statement you previously defined in the State the goal section.• Connect the model's goal to the ideal outcome by explicitly defining what you want the model to do.• The following table states the ideal outcomes and the model's goal for hypothetical apps:
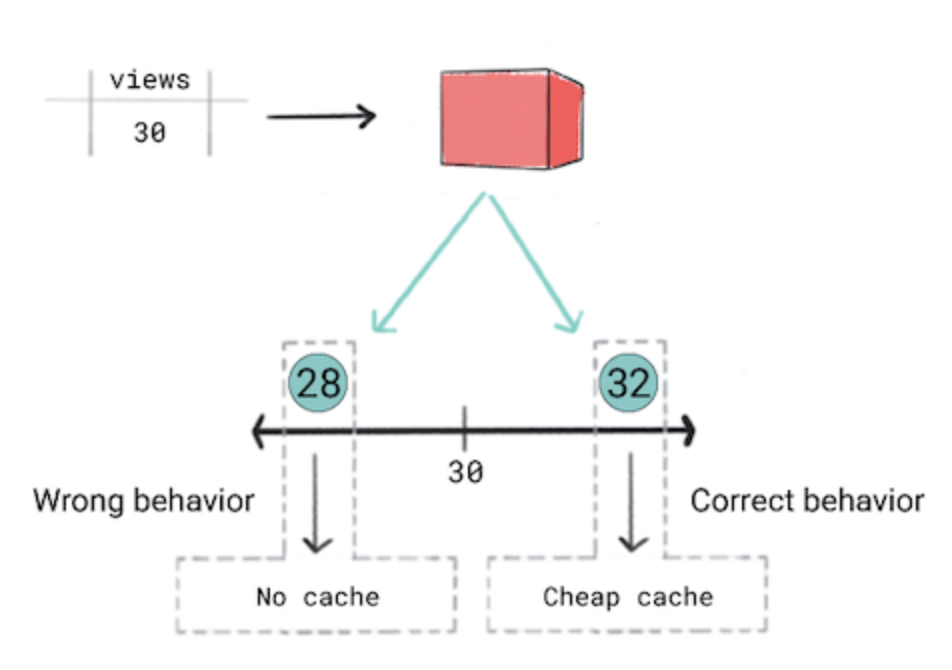
1.2.2. Choose the right kind of model• Your choice of model type depends upon the specific context and constraints of your problem.• A classification model predicts what category the input data belongs to, for example, whether an input should be classified as A, B, or C.• A regression model predicts where to place the input data on a number line.• Consider the following scenario:– You want to cache videos based on their predicted popularity. In other words, if your model predicts that a video will be popular, you want to quickly serve it to users. To do so, you'll use the more effective and expensive cache. For other videos, you'll use a different cache. Your caching criteria is the following:* If a video is predicted to get 50 or more views, you'll use the expensive cache.* If a video is predicted to get between 30 and 50 views, you'll use the cheap cache.* If the video is predicted to get less than 30 views, you won't cache the video.– You think a regression model is the right approach because you'll be predicting a numeric value—the number of views. However, when training the regression model, you realize that it produces the same loss for a prediction of 28 and 32 for videos that have 30 views. In other words, although your app will have very different behavior if the prediction is 28 versus 32, the model considers both predictions equally good.– Regression models are unaware of product-defined thresholds. Therefore, if your app's behavior changes significantly because of small differences in a regression model's predictions, you should consider implementing a classification model instead.– In this scenario, a classification model would produce the correct behavior because a classification model would produce a higher loss for a prediction of 28 than 32. In a sense, classification models produce thresholdsby default.
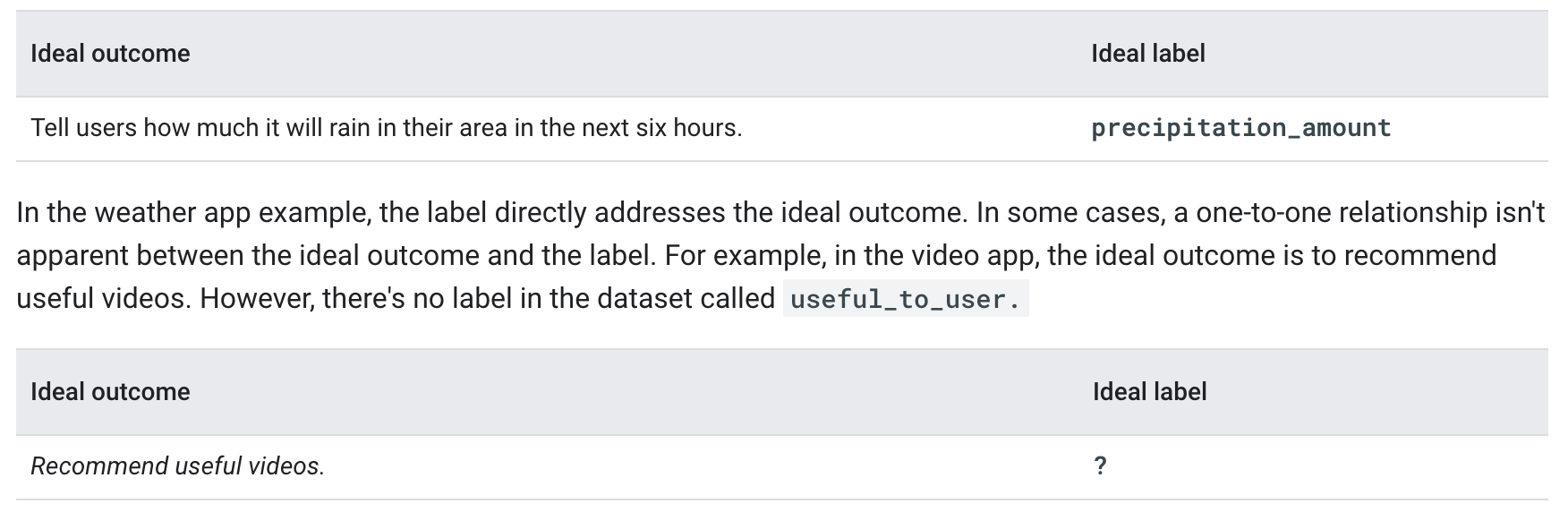
• This scenario highlights two important points:– Predict the decision.When possible, predict the decision your app will take. In the video example, a classification model would predict the decision if the categories it classified videos into were "no cache," "cheap cache," and "expensive cache." Hiding your app's behavior from the model can cause your app to produce the wrong behavior.– Understand the problem's constraints. If your app takes different actions based on different thresholds, determine if those thresholds are fixed or dynamic.* Dynamic thresholds: If thresholds are dynamic, use a regression model and set the thresholds limits in your app's code. This lets you easily update the thresholds while still having the model make reasonable predictions.* Fixed thresholds: If thresholds are fixed, use a classification model and label your datasets based on the threshold limits.– In general, most cache provisioning is dynamic and the thresholds change over time. Therefore, because this is specifically a caching problem, a regression model is the best choice. However, for many problems, the thresholds will be fixed, making a classification model the best solution.1.2.3. Identify the model's output• The model's output should accomplish the task defined in the ideal outcome. If you're using a regression model, the numeric prediction should provide the data needed to accomplish the ideal outcome; if you're using a classification model, the categorical prediction should provide the data needed to accomplish the ideal outcome.• In the weather app, the ideal outcome is to tell users how much it will rain in the next six hours. We could use a regression model that predicts the label precipitation_amount.
• Therefore, we'll need to find a proxy label.• Proxy Label– Proxy labels substitute for labels that aren't in the dataset. – Proxy labels are necessary when you can't directly measure what you want to predict. – In the video app, we can't directly measure whether or not a user will find a video useful. It would be great if the dataset had a useful feature, and users marked all the videos that they found useful, but because the dataset doesn't, we'll need a proxy label that substitutes for usefulness.* A proxy label for usefulness might be whether or not the user will share or like the video.– Note: No proxy label can be a perfect substitute for your ideal outcome.– Be cautious with proxy labels because they don't directly measure what you want to predict. For example, the following table outlines issues with potential proxy labels for Recommend useful videos:
1.2.4. Define the success metrics• Success metrics define what you care about, like engagement or helping users take appropriate action, such as watching videos that they'll find useful. • Success metrics differ from the model's evaluation metrics, like accuracy, precision, recall, or AUC.• For example, the weather app's success and failure metrics might be defined as the following:
• We recommend defining ambitious success metrics. – High ambitions can cause gaps between success and failure though. – For example, users spending on average 10 percent more time on the site than before is neither success nor failure. The undefined gap is not what's important.• What's important is your model's capacity to move closer—or exceed—the definition of success.– For instance, when analyzing the model's performance, consider the following question: Would improving the model get you closer to your defined success criteria?* For example,a model might have great evaluation metrics, but not move you closer to your success criteria, indicating that even with a perfect model, you would not meet the success criteria you defined. * On the other hand, a model might have poor evaluation metrics, but get you closer to your success criteria, indicating that improving the model would get you closer to success.• The following are dimensions to consider when determining if the model is worth improving:– Not good enough, but continue. The model shouldn't be used in a production environment, but over time it might be significantly improved.– Good enough, and continue. The model could be used in a production environment, and it might be further improved.– Good enough, but can't be made better. The model is in a production environment, but it is probably as good as it can be.– Not good enough, and never will be. The model should not be used in a production environment and no amount of training will probably get it there.• Note: When deciding to improve the model, re-evaluate if the increase in resources, like engineering time and compute costs, justify the predicted improvement of the model.• Note: After defining the success and failure metrics, you need to determine how often you'll measure them.• Note: When analyzing failure metrics, try to determine why the system failed. – For example, the model might be predicting which videos users will click, but the model might start recommending clickbait titles that cause user engagement to drop off. – In the weather app example, the model might accurately predict when it will rain but for too large of a geographic region.1.3. Implementing a model• When implementing a model, start simple. • Most of the work in ML is on the data side, so getting a full pipeline running for a complex model is harder than iterating on the model itself. • After setting up your data pipeline and implementing a simple model that uses a few features, you can iterate on creating a better model.• Simple models provide a good baseline, even if you don't end up launching them. • In fact, using a model is probably better than you think. • Starting simple helps you determine whether or not a complex model is even justified.1.3.1. Train your own model versus using a pre-trained model• Pre-trained models only really work when the label and features match your dataset exactly. – For example, if a pre-trained model uses 25 features and your dataset only includes 24 of them, the pre-trained model will most likely make bad predictions.• Commonly, ML practitioners use matching subsections of inputs from a pre-trained model for fine-tuning or transfer learning. If a pre-trained models doesn't exist for your particular use case, consider using subsections from a pre-trained model when training your own.• For information on pre-trained models, see pre-trained models from TensorFlow Hub.1.3.2. Monitoring• During problem framing, consider the monitoring and alerting infrastructure your ML solution needs.• Model deployment– In some cases, a newly trained model might be worse than the model currently in production. If it is, you'll want to prevent it from being released into production and get an alert that your automated deployment has failed.• Training-serving skew– If any of the incoming features used for inference have values that fall outside the distribution range of the data used in training, you'll want to be alerted because it's likely the model will make poor predictions. * For example, if your model was trained to predict temperatures for equatorial cities at sea level, then your serving system should alert you of incoming data with latitudes and longitudes, and/or altitudes outside the range the model was trained on. Conversely, the serving system should alert you if the model is making predictions that are outside the distribution range that was seen during training.• Inference server– If you're providing inferences through an RPC system, you'll want to monitor the RPC server itself and get an alert if it stops providing inferences.