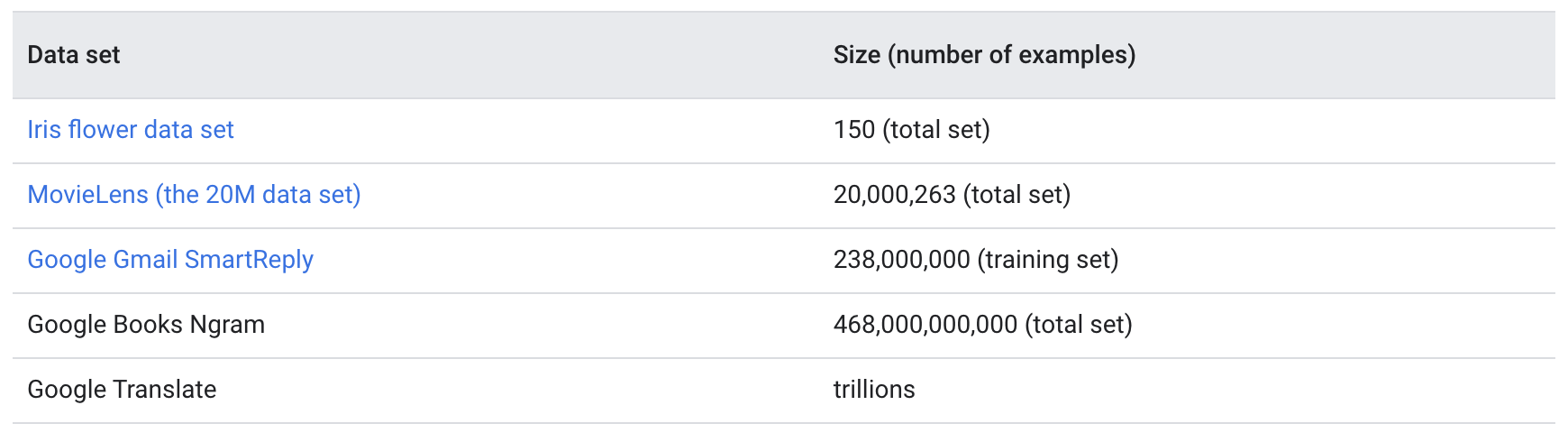
1. Collecting Data1.1. The Size and Quality of a Dataset, "Garbage in, garbage out"• Your model is only as good as your data• But how do you measure your data set's quality and improve it?• And how much data do you need to get useful results? – The answers depend on the type of problem you’re solving.1.1.1. The Size of a Dataset• As a rough rule of thumb, your model should train on at least an order of magnitude more examples than trainable parameters. • Simple models on large data sets generally beat fancy models on small data sets. • Google has had great success training simple linear regression models on large data sets.• What counts as "a lot" of data? It depends on the project. Consider the relative size of these data sets:
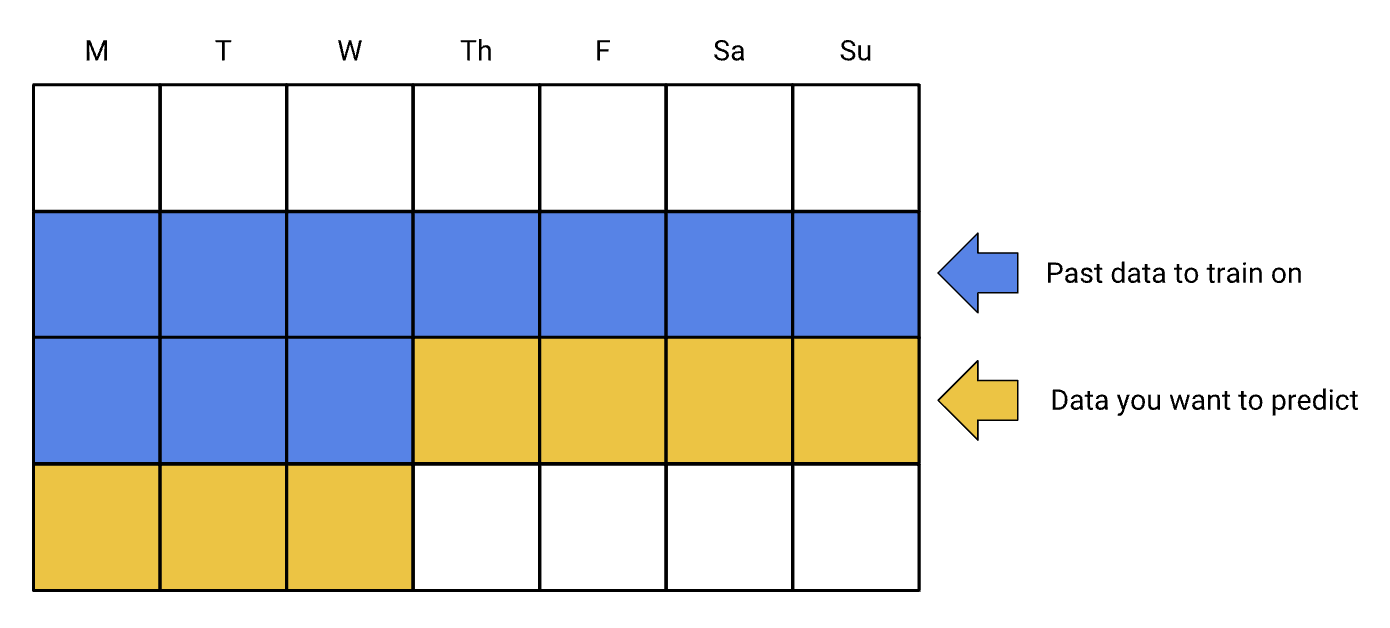
1.1.2. The Quality of a Dataset• It’s no use having a lot of data if it’s bad data; quality matters, too. • But what counts as "quality"?– A quality data set is one that lets you succeed with the business problem you care about. – In other words, the data is good if it accomplishes its intended task.• However, while collecting data, it's helpful to have a more concrete definition of quality. • Certain aspects of quality tend to correspond to better-performing models:– Reliability– Feature representation– Minimizing skew• Reliability– Reliability refers to the degree to which you can trust your data. – In measuring reliability, you must determine:* How common are label errors? For example, if your data is labeled by humans, sometimes humans make mistakes.* Are your features noisy? For example, GPS measurements fluctuate. Some noise is okay. You’ll never purge your data set of all noise. You can collect more examples too.* Is the data properly filtered for your problem? For example, should your data set include search queries from bots? If you're building a spam-detection system, then likely the answer is yes, but if you're trying to improve search results for humans, then no.– What makes data unreliable?* Omitted values. For instance, a person forgot to enter a value for a house's age.* Duplicate examples. For example, a server mistakenly uploaded the same logs twice.* Bad labels. For instance, a person mislabeled a picture of an oak tree as a maple.* Bad feature values. For example, someone typed an extra digit, or a thermometer was left out in the sun.– – Google Translate focused on reliability to pick the "best subset" of its data; that is, some data had higher quality labels than other parts.• Feature Representation– Representation is the mapping of data to useful features. – You'll want to consider the following questions:* How is data shown to the model?* Should you normalize numeric values?* How should you handle outliers?• Training vs. Prediction– Let's say you get great results offline. Then in your live experiment, those results don't hold up. What could be happening?* This problem suggests training/serving skew—that is, different results are computed for your metrics at training time vs. serving time. * Causes of skew can be subtle but have deadly effects on your results. * Always consider what data is available to your model at prediction time. * During training, use only the features that you'll have available in serving, and make sure your training set is representative of your serving traffic.• The Golden Rule: Do unto training as you would do unto prediction. That is, the more closely your training task matches your prediction task, the better your ML system will perform.1.2. Joining Data Logs• When assembling a training set, you must sometimes join multiple sources of data.1.2.1. Types of Logs• You might work with any of the following kinds of input data:– transactional logs– attribute data– aggregate statistics• Transactional logs record a specific event. – For example, a transactional log might record an IP address making a query and the date and time at which the query was made. – Transactional events correspond to a specific event.• Attribute data contains snapshots of information. For example:– user demographics– search history at the time of query• Attribute dataisn't specific to an event or a moment in time, but can still be useful for making predictions. – For prediction tasks not tied to a specific event (for example, predicting user churn, which involves a range of time rather than an individual moment), attribute data might be the only type of data.• Attribute data and transactional logs are related. – For example, you can create a type of attribute data by aggregating several transactional logs, creating aggregate statistics. – In this case, you can look at many transactional logs to create a single attribute for a user.• Aggregate statistics create an attribute from multiple transactional logs. For example:– frequency of user queries– average click rate on a certain ad1.2.2. Joining Log Sources• When collecting data for your machine learning model, you must join together different sources to create your data set. • Some examples:– Leverage the user's ID and timestamp in transactional logs to look up user attributes at time of event.– Use the transaction timestamp to select search history at time of query.• • It is critical to use event timestamps when looking up attribute data. If you grab the latest user attributes, your training data will contain the values at the time of data collection, which causes training/serving skew. If you forget to do this for search history, you could leak the true outcome into your training data!1.2.3. Prediction Data Sources - Online vs. Offline• The choice influences how your system collects data as follows:– online → Latency is a concern, so your system must generate input quickly.– offline → You likely have no compute restrictions, so can do similarly complex operations as training data generation.• For example:– Attribute data frequently needs to be looked up from some other system, which could introduce latency concerns. – Similarly, aggregated statistics can be expensive to compute on the fly. If latency is a blocker, one possibility is to precompute these statistics.1.3. Identifying Labels and Sources1.3.1. Direct vs. Derived Sources• The best label is a direct label of what you want to predict. • For example, – if you want to predict whether a user is a Taylor Swift fan, a direct label would be "User is a Taylor Swift fan."– A simpler test of fanhood might be whether the user has watched a Taylor Swift video on YouTube. – The label "user has watched a Taylor Swift video on YouTube" is a derived label because it does not directly measure what you want to predict. – Is this derived label a reliable indicator that the user likes Taylor Swift?* Your model will only be as good as the connection between your derived label and your desired prediction.1.3.2. Label Sources• The output of your model could be either an Event or an Attribute. • This results in the following two types of labels:– Direct label for Events, such as “Did the user click the top search result?”– Direct label for Attributes, such as “Will the advertiser spend more than $X in the next week?”1.3.3. Direct Label for Events• For events, direct labels are typically straightforward, because you can log the user behavior during the event for use as the label. • When labeling events, ask yourself the following questions:– How are your logs structured?– What is considered an “event” in your logs?• For example, – does the system log a user clicking on a search result or when a user makes a search? – If you have click logs, realize that you'll never see an impression without a click. – You would need logs where the events are impressions, so you cover all cases in which a user sees a top search result.1.3.4. Direct Labels for Attributes• Let's say your label is, “The advertiser will spend more than $X in the next week.” • Typically, you'd use the previous days of data to predict what will happen in the subsequent days. • For example, the following illustration shows the ten days of training data that predict the subsequent seven days:
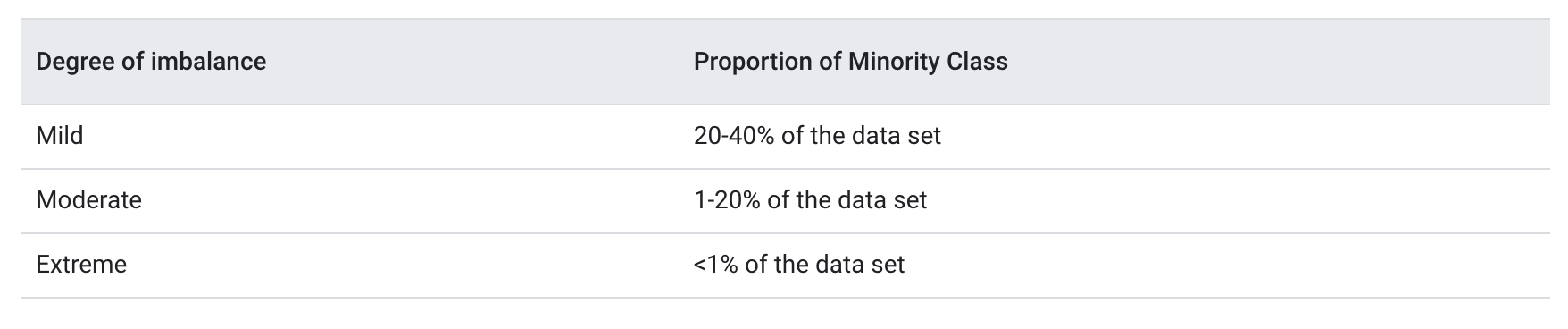
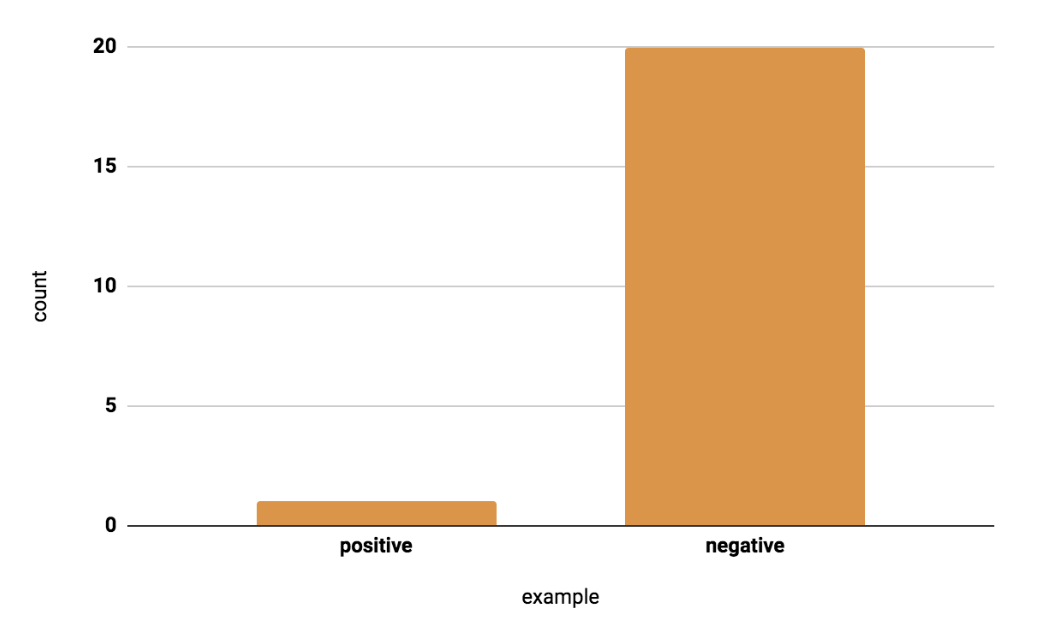
• Remember to consider seasonality or cyclical effects; • For example, – advertisers might spend more on weekends. For that reason, you may prefer to use a 14-day window instead, or to use the date as a feature so the model can learn yearly effects.• Choose event data carefully to avoid cyclical or seasonal effects or to take those effects into account.1.3.5. Direct Labels Need Logs of Past Behavior• In the preceding cases, notice that we needed data about the true result. • Machine learning makes predictions based on what has happened in the past, so if you don't have logs for the past, you need to get them.1.3.6. What if You Don’t Have Data to Log?• Perhaps your product doesn’t exist yet, so you don't have any data to log. • In that case, you could take one or more of the following actions:– Use a heuristic for a first launch, then train a system based on logged data.– Use logs from a similar problem to bootstrap your system.– Use human raters to generate data by completing tasks.1.3.7. Why Use Human Labeled Data?• There are advantages and disadvantages to using human-labeled data.• Pros– Human raters can perform a wide range of tasks.– The data forces you to have a clear problem definition.• Cons– The data is expensive for certain domains.– Good data typically requires multiple iterations.1.3.8. Improving Quality• Always check the work of your human raters. • For example, – label 1000 examples yourself, and see how your results match the raters'. (Labeling data yourself is also a great exercise to get to know your data.) – If discrepancies surface, don't assume your ratings are the correct ones, especially if a value judgment is involved. – If human raters have introduced errors, consider adding instructions to help them and try again.• Looking at your data by hand is a good exercise regardless of how you obtained your data. Andrej Karpathy did this on ImageNet and wrote about the experience.Back To Top2. Sampling and Splitting Data2.1. Introduction to Sampling• It's often a struggle to gather enough data for a machine learning project. • Sometimes, however, there is too much data, and you must select a subset of examples for training.• • How do you select that subset?– As an example, consider Google Search. – At what granularity would you sample its massive amounts of data? – Would you use random queries? – Random sessions? – Random users?• • Ultimately, the answer depends on the problem: what do we want to predict, and what features do we want?– To use the feature previous query, you need to sample at the session level, because sessions contain a sequence of queries.– To use the feature user behavior from previous days, you need to sample at the user level.2.2. Filtering for PII (Personally Identifiable Information)• If your data includes PII (personally identifiable information), you may need to filter it from your data. • A policy may require you to remove infrequent features, for example.• This filtering will skew your distribution. • You’ll lose information in the tail (the part of the distribution with very low values, far from the mean).• This filtering is helpful because very infrequent features are hard to learn. • But it’s important to realize that your dataset will be biased toward the head queries. • At serving time, you can expect to do worse on serving examples from the tail, since these were the examples that got filtered out of your training data. • Although this skew can’t be avoided, be aware of it during your analysis.• If you filter PII from your dataset, and in the process you remove the tail, the dataset will be biased toward the head queries. Consider the implications for your project.2.3. Imbalanced Data• A classification data set with skewed class proportions is called imbalanced. • What counts as imbalanced? The answer could range from mild to extreme, as the table below shows.
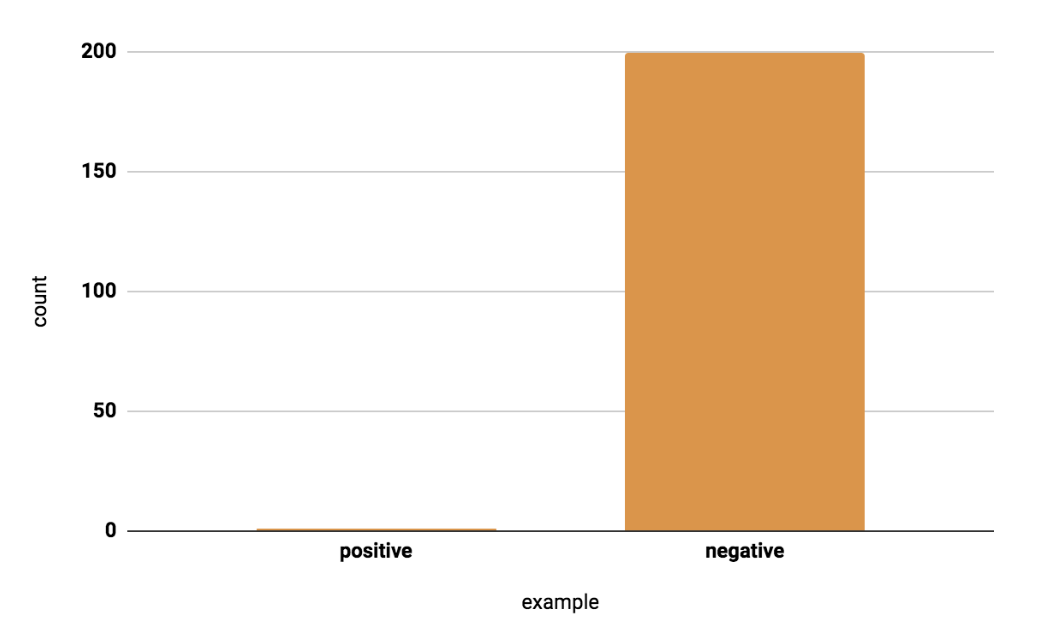
• Why look out for imbalanced data?You may need to apply a particular sampling technique if you have a classification task with an imbalanced data set.• Consider the following example of a model that detects fraud. Instances of fraud happen once per 200 transactions in this data set, so in the true distribution, about 0.5% of the data is positive.
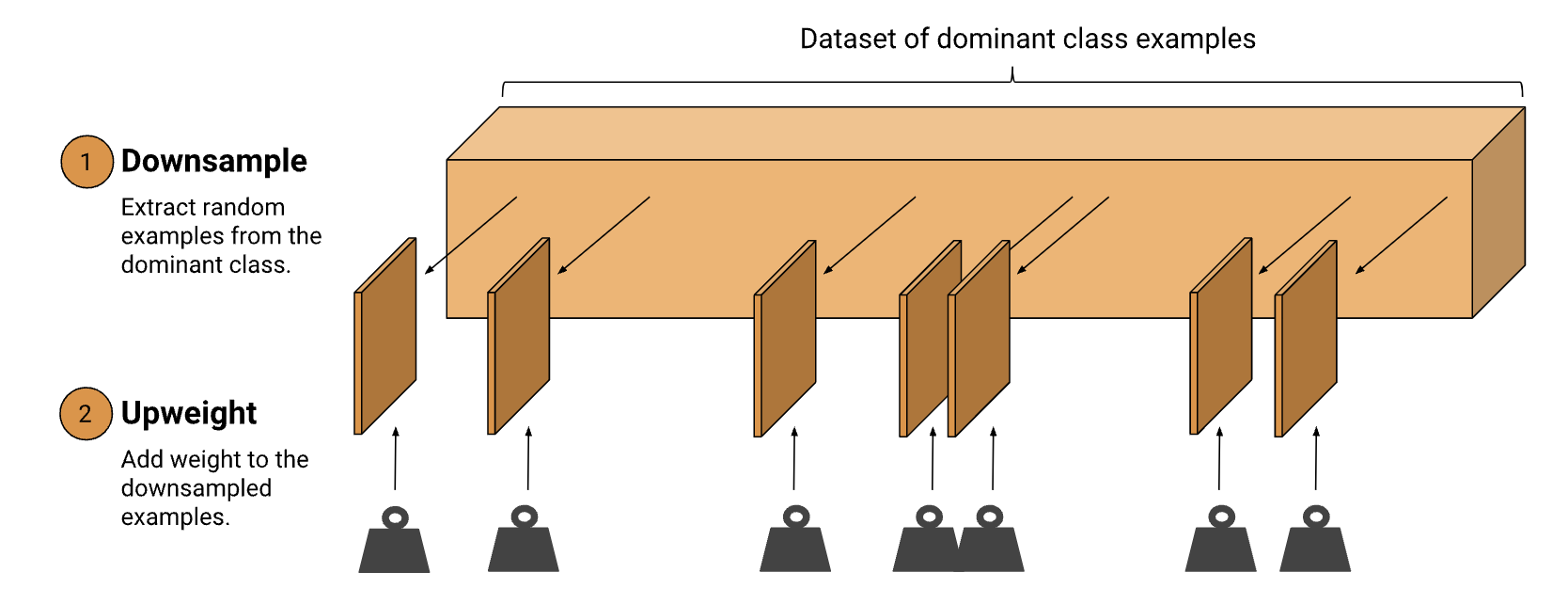
• Why would this be problematic?– With so few positives relative to negatives, the training model will spend most of its time on negative examples and not learn enough from positive ones. – For example, if your batch size is 128, many batches will have no positive examples, so the gradients will be less informative.• • If you have an imbalanced data set, first try training on the true distribution. If the model works well and generalizes, you're done! If not, try the following downsampling and upweighting technique.2.4. Downsampling and Upweighting• An effective way to handle imbalanced data is to downsample and upweight the majority class. • Let's start by defining those two new terms:– Downsampling (in this context) means training on a disproportionately low subset of the majority class examples.– Upweighting means adding an example weight to the downsampled class equal to the factor by which you downsampled.• Step 1: Downsample the majority class. – Consider again our example of the fraud data set, with 1 positive to 200 negatives. – Downsampling by a factor of 20 improves the balance to 1 positive to 10 negatives (10%). – Although the resulting training set is still moderately imbalanced, the proportion of positives to negatives is much better than the original extremely imbalanced proportion (0.5%).
• Step 2: Upweight the downsampled class:– The last step is to add example weights to the downsampled class. – Since we downsampled by a factor of 20, the example weight should be 20.
• Note: You may be used to hearing the term weight when it refers to model parameters, like connections in a neural network. Here we're talking about example weights, which means counting an individual example more importantly during training. An example weight of 10 means the model treats the example as 10 times as important (when computing loss) as it would an example of weight 1.• • The weight should be equal to the factor you used to downsample:• {example weight}={original example weight}×{downsampling factor}2.4.1. Why Downsample and Upweight?• It may seem odd to add example weights after downsampling. • We were trying to make our model improve on the minority class -- why would we upweight the majority? These are the resulting changes:– Faster convergence: During training, we see the minority class more often, which will help the model converge faster.– Disk space: By consolidating the majority class into fewer examples with larger weights, we spend less disk space storing them. This savings allows more disk space for the minority class, so we can collect a greater number and a wider range of examples from that class.– Calibration: Upweighting ensures our model is still calibrated; the outputs can still be interpreted as probabilities.2.5. Splitting Your Data• The example in Section 2.5.1. shows a pure random split is not always the right approach.• • A frequent technique for online systems is to split the data by time, such that you would:– Collect 30 days of data.– Train on data from Days 1-29.– Evaluate on data from Day 30.• For online systems: – The training data is older than the serving data, so this technique ensures your validation set mirrors the lag between training and serving. – However, time-based splits work best with very large datasets, such as those with tens of millions of examples. – In projects with less data, the distributions end up quite different between training, validation, and testing.• • Recall also the data split flaw from the machine learning literature project described in the Machine Learning Crash Course. – The data was literature penned by one of three authors, so data fell into three main groups. – Because the team applied a random split, data from each group was present in the training, evaluation, and testing sets, so the model learned from information it wouldn't necessarily have at prediction time. – This problem can happen anytime your data is grouped, whether as time series data, or clustered by other criteria. – Domain knowledge can inform how you split your data.• • To design a split that is representative of your data, consider what the data represents. The golden rule applies to data splits as well: the testing task should match the production task as closely as possible.• • For additional review, see these modules in the Machine Learning Crash Course:– Splitting Data– Real-world example of a data splitting flaw in an ML literature project2.5.1. When Random Splitting isn't the Best Approach• While random splitting is the best approach for many ML problems, it isn't always the right solution. • For example, consider data sets in which the examples are naturally clustered into similar examples.• Suppose you want your model to classify the topic from the text of a news article. Why would a random split be problematic?
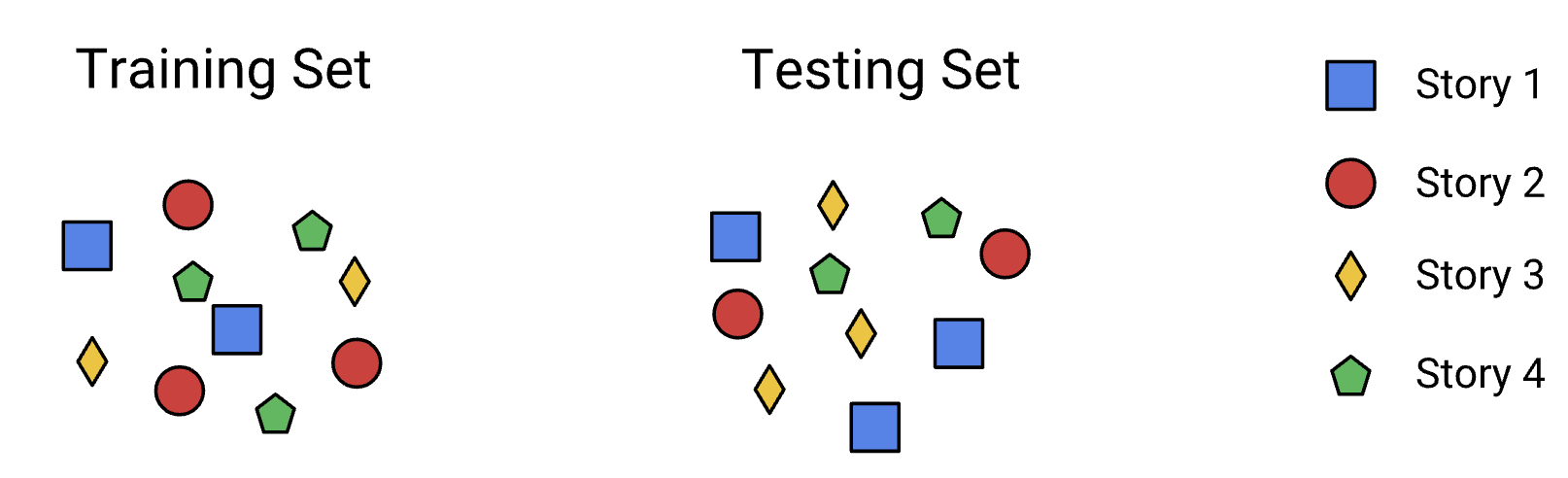
Figure 1:News Stories are Clustered.
• News stories appear in clusters: – multiple stories about the same topic are published around the same time. – If we split the data randomly, therefore, the test set and the training set will likely contain the same stories. – In reality, it wouldn't work this way because all the stories will come in at the same time, so doing the split like this would cause skew.•
Figure 2:A random split will split a cluster across sets, causing skew.
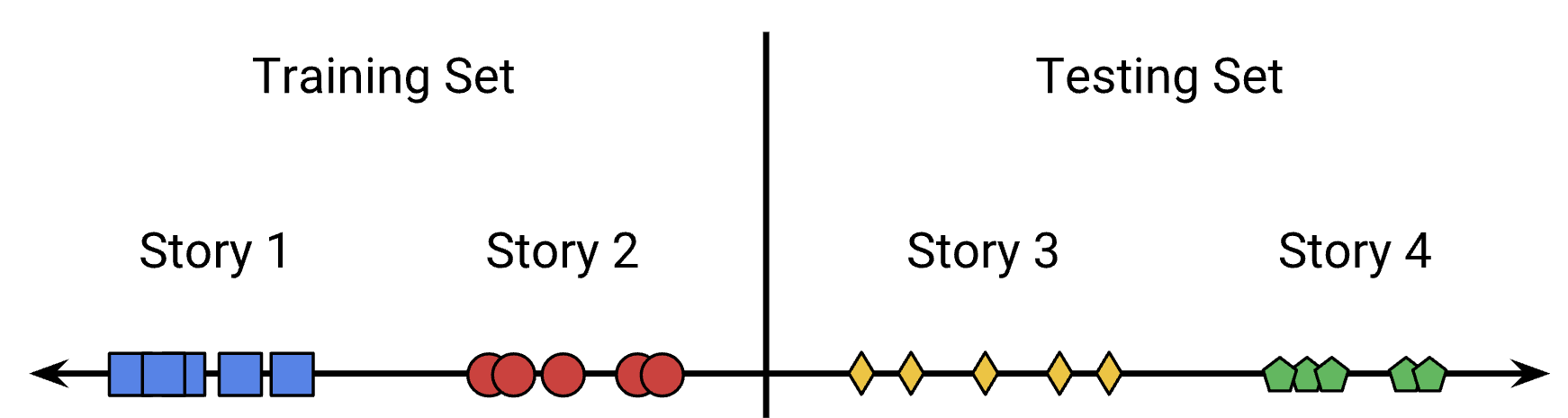
• A simple approach to fixing this problem would be to split our data based on when the story was published, perhaps by day the story was published. This results in stories from the same day being placed in the same split.
Figure 3:Splitting on time allows the clusters to mostly end up in the same set.
• With tens of thousands or more news stories, a percentage may get divided across the days. • That's okay, though; in reality these stories were split across two days of the news cycle. • Alternatively, you could throw out data within a certain distance of your cutoff to ensure you don't have any overlap. • For example, – you could train on stories for the month of April, and then use the second week of May as the test set, with the week gap preventing overlap.2.6. Randomization2.6.1. Practical Considerations• Make your data generation pipeline reproducible. • Say you want to add a feature to see how it affects model quality. – For a fair experiment, your datasets should be identical except for this new feature. If your data generation runs are not reproducible, you can't make these datasets.– • In that spirit, make sure any randomization in data generation can be made deterministic:– Seed your random number generators (RNGs).* Seeding ensures that the RNG outputs the same values in the same order each time you run it, recreating your dataset.– Use invariant hash keys.* Hashing is a common way to split or sample data. * You can hash each example, and use the resulting integer to decide in which split to place the example. * The inputs to your hash function shouldn't change each time you run the data generation program. * Don't use the current time or a random number in your hash, for example, if you want to recreate your hashes on demand.• • The preceding approaches apply both to sampling and splitting your data.2.6.2. Considerations for Hashing• Imagine again you were collecting Search queries and using hashing to include or exclude queries. • If the hash key only used the query, then across multiple days of data, you’ll either always include that query or always exclude it. • • Always including or always excluding a query is bad because:– Your training set will see a less diverse set of queries.– Your evaluation sets will be artificially hard, because they won't overlap with your training data. In reality, at serving time, you'll have seen some of the live traffic in your training data, so your evaluation should reflect that.– • Instead you can hash on query + date, which would result in a different hashing each day.•
• Note: Make your hashing unique to ensure your system doesn't collide with other systems.Back To Top