1. Introduction• Here’s a high-level overview of the workflow used to solve machine learning problems:– Step 1: Gather Data– Step 2: Explore Your Data– Step 2.5: Choose a Model** “Choose a model” is not a formal step of the traditional machine learning workflow; however, selecting an appropriate model for your problem is a critical task that clarifies and simplifies the work in the steps that follow.– Step 3: Prepare Your Data– Step 4: Build, Train, and Evaluate Your Model– Step 5: Tune Hyperparameters– Step 6: Deploy Your Model
2. Step 1: Gather Data• Your text classifier can only be as good as the dataset it is built from.• If you don’t have a specific problem you want to solve and are just interested in exploring text classification in general, there are plenty of open source datasets available. You can find links to some of them in our GitHub repo. • On the other hand, if you are tackling a specific problem, you will need to collect the necessary data. • Many organizations provide public APIs for accessing their data—for example, the Twitter API or the NY Times API. You may be able to leverage these for the problem you are trying to solve.• Throughout this guide, we will use the Internet Movie Database (IMDb) movie reviews dataset to illustrate the workflow.• • Here are some important things to remember when collecting data:– If you are using a public API, understand the limitations of the API before using them. For example, some APIs set a limit on the rate at which you can make queries.– The more training examples (referred to as samples in the rest of this guide) you have, the better. This will help your model generalize better.– Make sure the number of samples for every class or topic is not overly imbalanced. That is, you should have comparable number of samples in each class.– Make sure that your samples adequately cover the space of possible inputs, not only the common cases.Back To Top3. Explore Your Data• Building and training a model is only one part of the workflow. • Understanding the characteristics of your data beforehand will enable you to build a better model. • This could simply mean obtaining a higher accuracy. It could also mean requiring less data for training, or fewer computational resources.• First up, let’s load the dataset into Python.• •
defload_imdb_sentiment_analysis_dataset(data_path, seed=123):"""Loads the IMDb movie reviews sentiment analysis dataset. # Arguments data_path: string, path to the data directory. seed: int, seed for randomizer. # Returns A tuple of training and validation data. Number of training samples: 25000 Number of test samples: 25000 Number of categories: 2 (0 - negative, 1 - positive) # References Mass et al., http://www.aclweb.org/anthology/P11-1015 Download and uncompress archive from: http://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz """ imdb_data_path = os.path.join(data_path,'aclImdb')# Load the training data train_texts =[] train_labels =[]for category in['pos','neg']: train_path = os.path.join(imdb_data_path,'train', category)for fname insorted(os.listdir(train_path)):if fname.endswith('.txt'):withopen(os.path.join(train_path, fname))as f: train_texts.append(f.read()) train_labels.append(0if category =='neg'else1)# Load the validation data. test_texts =[] test_labels =[]for category in['pos','neg']: test_path = os.path.join(imdb_data_path,'test', category)for fname insorted(os.listdir(test_path)):if fname.endswith('.txt'):withopen(os.path.join(test_path, fname))as f: test_texts.append(f.read()) test_labels.append(0if category =='neg'else1)# Shuffle the training data and labels. random.seed(seed) random.shuffle(train_texts) random.seed(seed) random.shuffle(train_labels)return((train_texts, np.array(train_labels)),(test_texts, np.array(test_labels)))
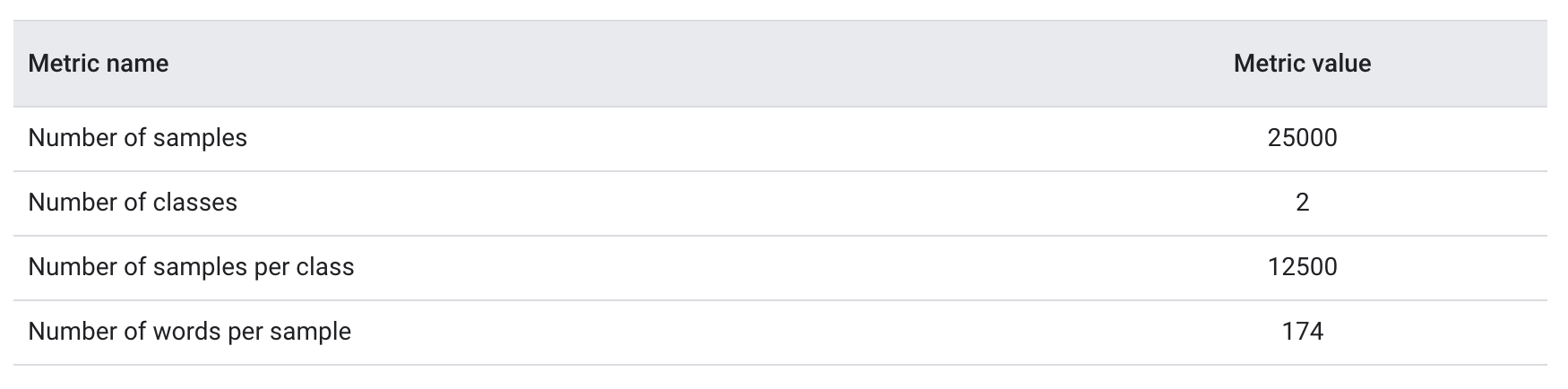
3.1. Checking the Data• After loading the data, it’s good practice to run some checks on it: – Pick a few samples and manually check if they are consistent with your expectations. * For example, print a few random samples to see if the sentiment label corresponds to the sentiment of the review. * Here is a review we picked at random from the IMDb dataset: “Ten minutes worth of story stretched out into the better part of two hours. When nothing of any significance had happened at the halfway point I should have left.” The expected sentiment (negative) matches the sample’s label.3.2. Collect Key Metrics• Once you’ve verified the data, collect the following important metrics that can help characterize your text classification problem:1. Number of samples: Total number of examples you have in the data.2. Number of classes: Total number of topics or categories in the data.3. Number of samples per class: Number of samples per class (topic/category). In a balanced dataset, all classes will have a similar number of samples; in an imbalanced dataset, the number of samples in each class will vary widely.4. Number of words per sample: Median number of words in one sample.5. Frequency distribution of words: Distribution showing the frequency (number of occurrences) of each word in the dataset.6. Distribution of sample length: Distribution showing the number of words per sample in the dataset.• Let’s see what the values for these metrics are for the IMDb reviews dataset:
Table 1:IMDb reviews dataset metrics
• explore_data.py contains functions to calculate and analyze these metrics. Here are a couple of examples:
import numpy as npimport matplotlib.pyplot as pltdefget_num_words_per_sample(sample_texts):"""Returns the median number of words per sample given corpus. # Arguments sample_texts: list, sample texts. # Returns int, median number of words per sample. """ num_words =[len(s.split())for s in sample_texts]return np.median(num_words)defplot_sample_length_distribution(sample_texts):"""Plots the sample length distribution. # Arguments samples_texts: list, sample texts. """ plt.hist([len(s)for s in sample_texts],50) plt.xlabel('Length of a sample') plt.ylabel('Number of samples') plt.title('Sample length distribution') plt.show()
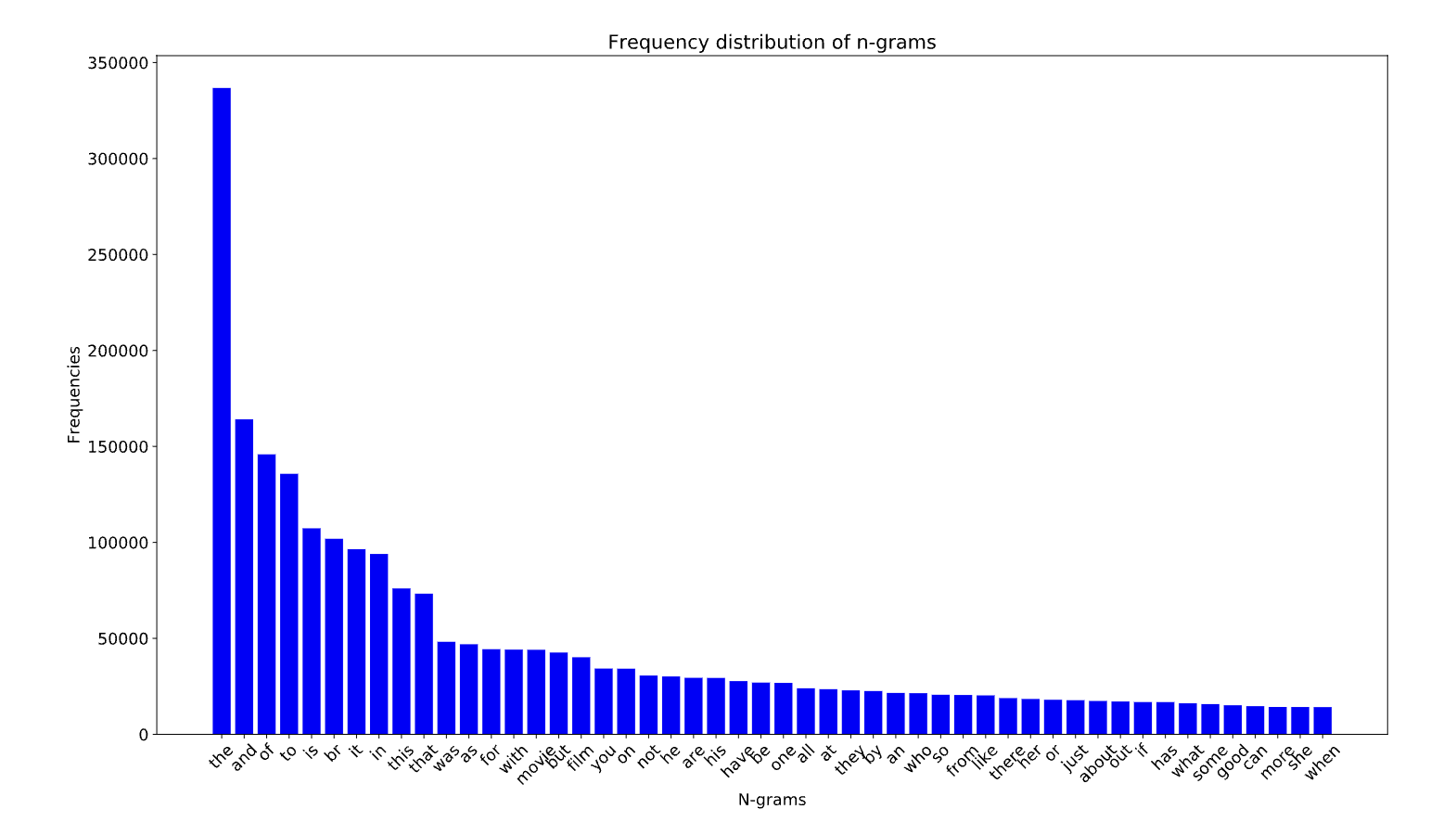
Figure 2:Frequency distribution of words for IMDb
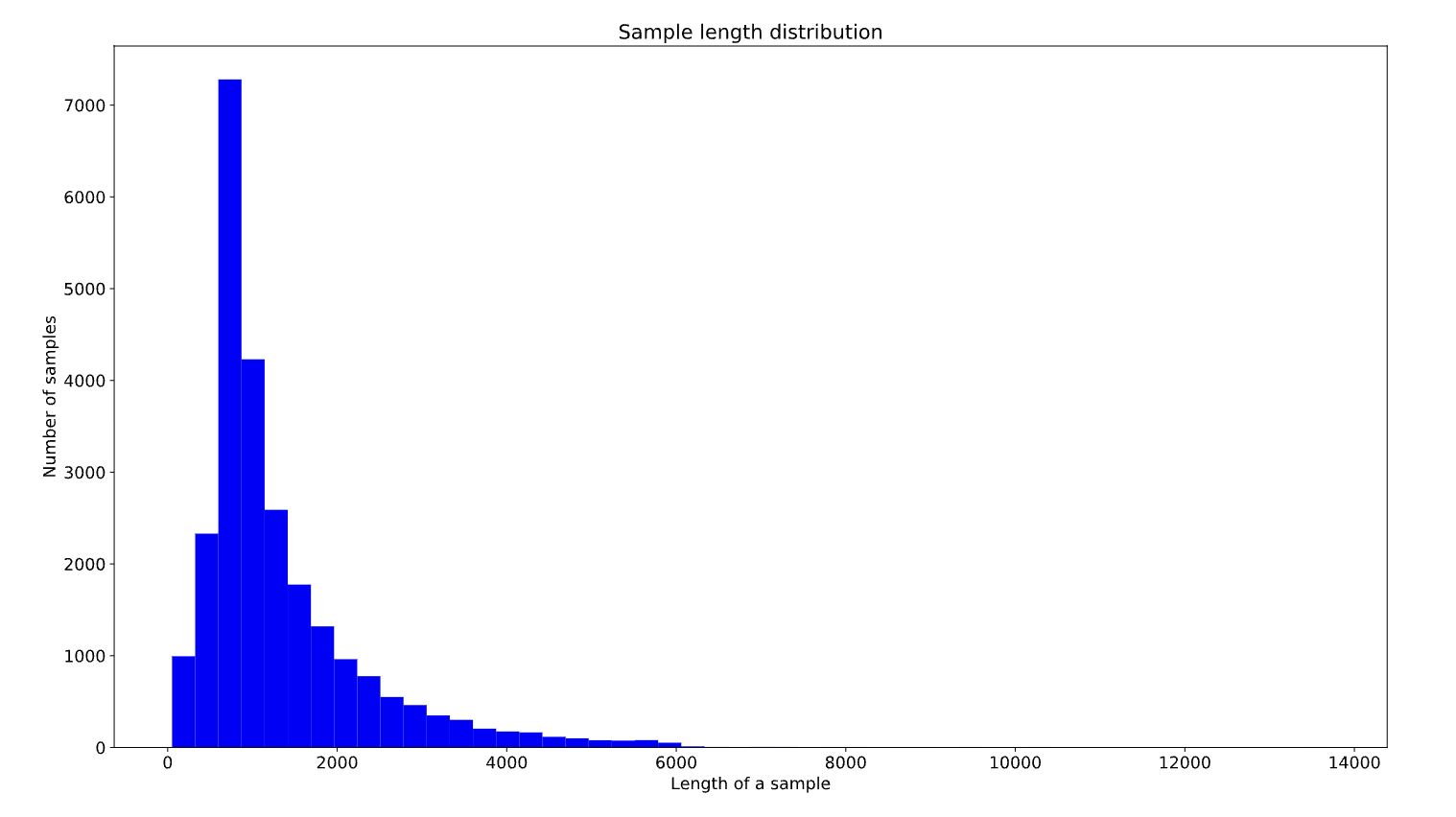
Figure 3:Distribution of sample length for IMDb
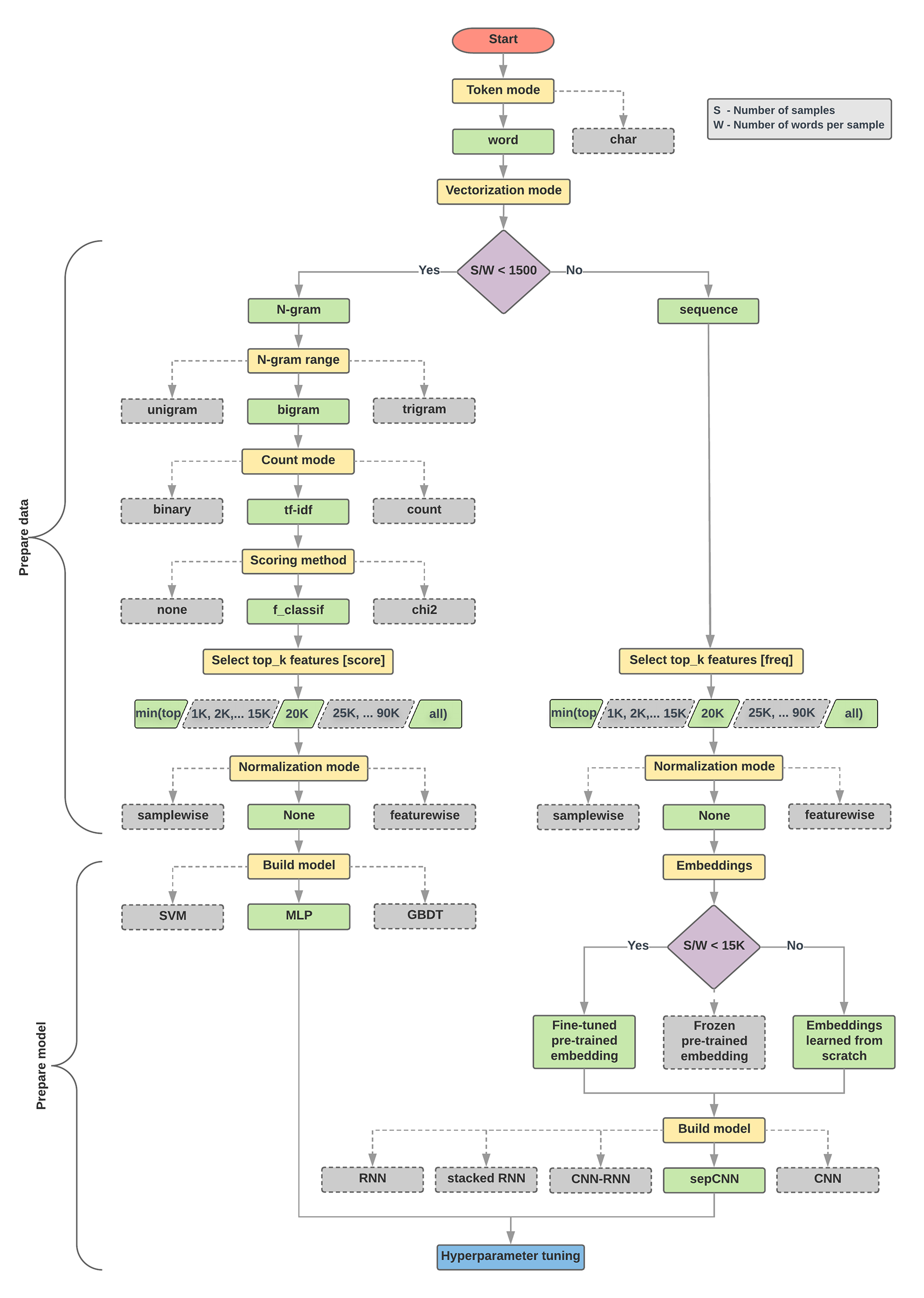
Back To Top4. Choose a Model• Next, based on the metrics we gathered in Step 2, we should think about which classification model we should use. • This means asking questions such as:– “How do we present the text data to an algorithm that expects numeric input?” (this is called data preprocessing and vectorization) – "What type of model should we use?”– “What configuration parameters should we use for our model?”– etc.• In this guide, we attempt to significantly simplify the process of selecting a text classification model. – For a given dataset, our goal is to find the algorithm that achieves close to maximum accuracy while minimizing computation time required for training. – We ran a large number (~450K) of experiments across problems of different types (especially sentiment analysis and topic classification problems), using 12 datasets, alternating for each dataset between different data preprocessing techniques and different model architectures. – This helped us identify dataset parameters that influence optimal choices.• The model selection algorithm and flowchart below are a summary of our experimentation.4.1. Algorithm for Data Preparation and Model Building
1. Calculate the number of samples/number of words per sample ratio.2. If this ratio is less than 1500, tokenize the text as n-grams and use asimple multi-layer perceptron (MLP) model to classify them (left branch in theflowchart below): a. Split the samples into word n-grams; convert the n-grams into vectors. b. Score the importance of the vectors and then select the top 20K using the scores. c. Build an MLP model.3. If the ratio is greater than 1500, tokenize the text as sequences and use asepCNN model to classify them (right branch in the flowchart below): a. Split the samples into words; select the top 20K words based on their frequency. b. Convert the samples into word sequence vectors. c. If the original number of samples/number of words per sample ratio is less than 15K, using a fine-tuned pre-trained embedding with the sepCNN model will likely provide the best results.4. Measure the model performance with different hyperparameter values to find the best model configuration for the dataset.
• In the flowchart below:– Yellow boxes → data and model preparation processes. – Grey boxes → choices we considered for each process. – Green boxes → our recommended choice for each process.• You can use this flowchart as a starting point to construct your first experiment, as it will give you good accuracy at low computation costs. You can then continue to improve on your initial model over the subsequent iterations.
Figure 4:Text classification flowchart
• This flowchart answers two key questions:– Which learning algorithm or model should we use?– How should we prepare the data to efficiently learn the relationship between text and label?• • The answer to the second question depends on the answer to the first question.– The way we preprocess data to be fed into a model will depend on what model we choose. – • Models can be broadly classified into two categories: – Those that use word ordering information (sequence models), – Those that just see text as “bags” (sets) of words (n-gram models). – • Types of sequence models include:– Convolutional neural networks (CNNs)– Recurrent neural networks (RNNs)– And their variations. – • Types of n-gram models include:– Logistic regression– Simple multi-layer perceptrons (MLPs, or fully-connected neural networks)– gradient boosted trees – support vector machines• • From our experiments, we have observed that the ratio of “number of samples” (S) to “number of words per sample” (W)correlates with which model performs well.• • When the value for this ratio is small (<1500):– Small multi-layer perceptrons that take n-grams as input (which we'll call Option A) perform better or at least as well as sequence models. – MLPs are simple to define and understand, and they take much less compute time than sequence models. • When the value for this ratio is large (≥1500):– Use a sequence model (Option B). – In the steps that follow, you can skip to the relevant subsections (labeled A or B) for the model type you chose based on the samples/words-per-sample ratio.• • In the case of our IMDb review dataset, the samples/words-per-sample ratio is ~144. This means that we will create a MLP model.• Note: When using the above flowchart, keep in mind that it may not necessarily lead you to the most optimal results for your problem, for several reasons:– Your goal may be different. We optimized for the best accuracy that could be achieved in the shortest possible compute time. An alternate flow may produce a better result, say, when optimizing for area under the curve (AUC).– We picked typical and common algorithm choices. As the field continues to evolve, new cutting-edge algorithms and enhancements may be relevant to your data and may perform better.– While we used several datasets to derive and validate the flowchart, there may be specific characteristics to your dataset that favor using an alternate flow.
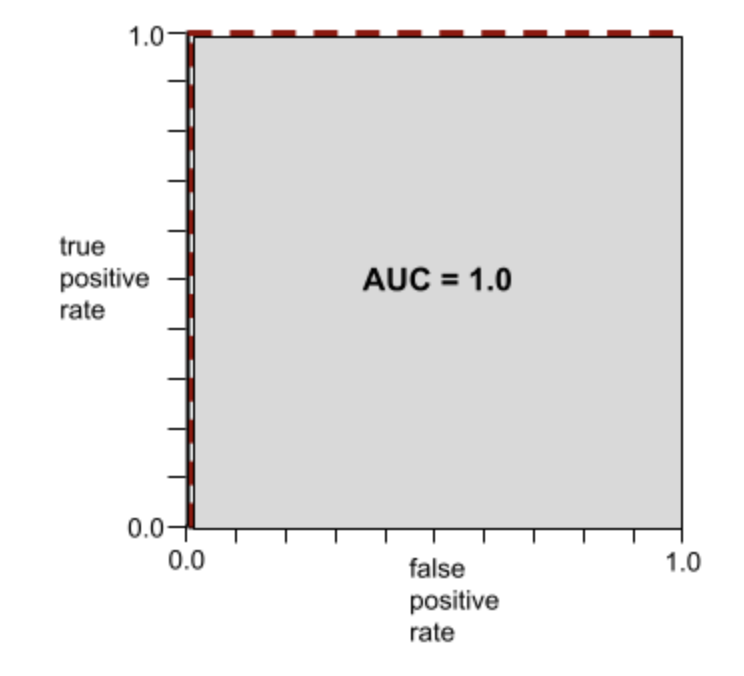
ROC (receiver operating characteristic) CurveA graph of true positive rate vs. false positive rate for different classification thresholds in binary classification.The shape of an ROC curve suggests a binary classification model's ability to separate positive classes from negative classes. Suppose, for example, that a binary classification model perfectly separates all the negative classes from all the positive classes:
The ROC curve for the preceding model looks as follows:
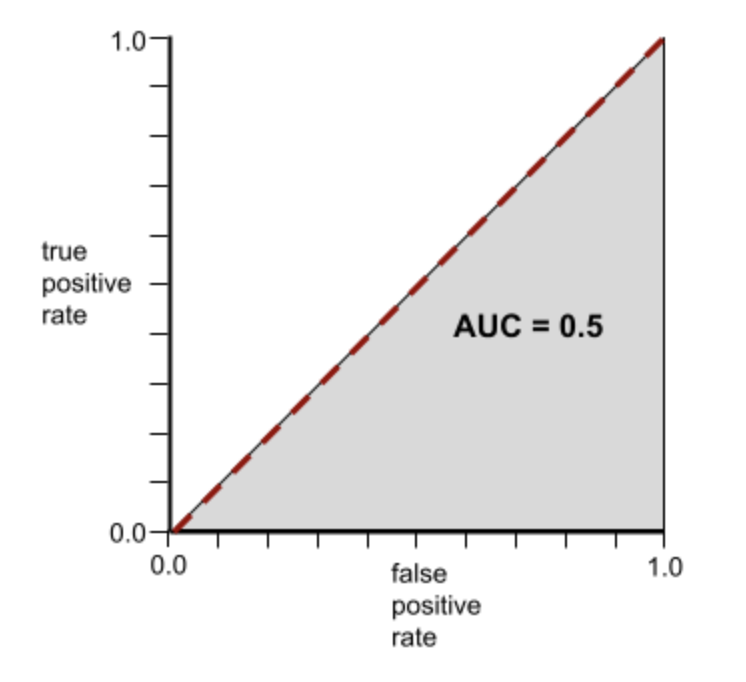
In contrast, the following illustration graphs the raw logistic regression values for a terrible model that can't separate negative classes from positive classes at all:
The ROC curve for this model looks as follows:
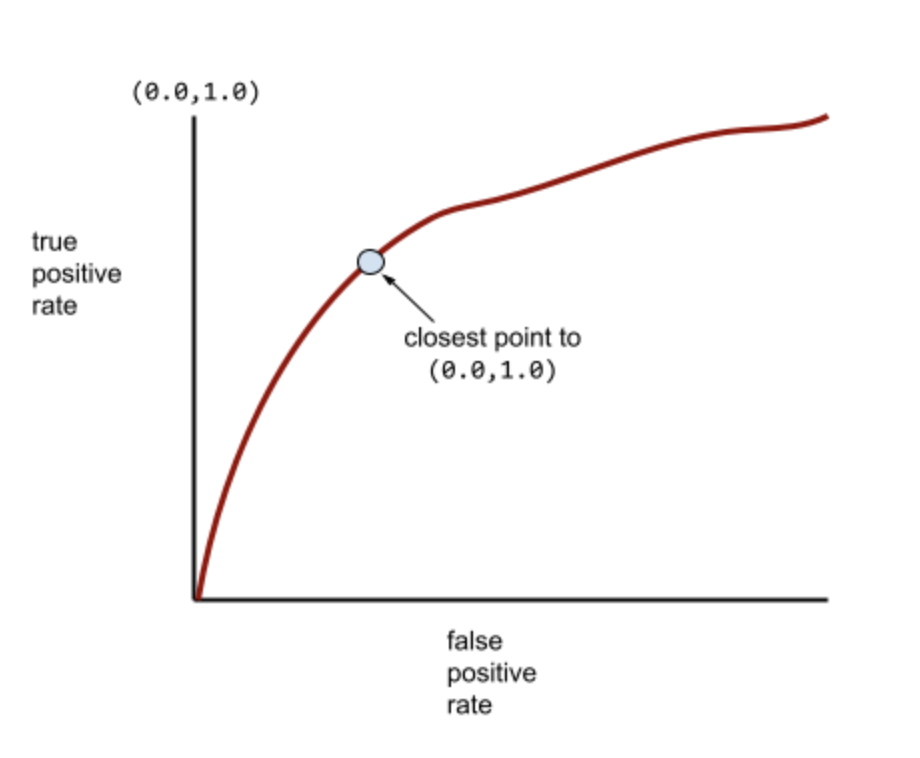
Meanwhile, back in the real world, most binary classification models separate positive and negative classes to some degree, but usually not perfectly. So, a typical ROC curve falls somewhere between the two extremes:
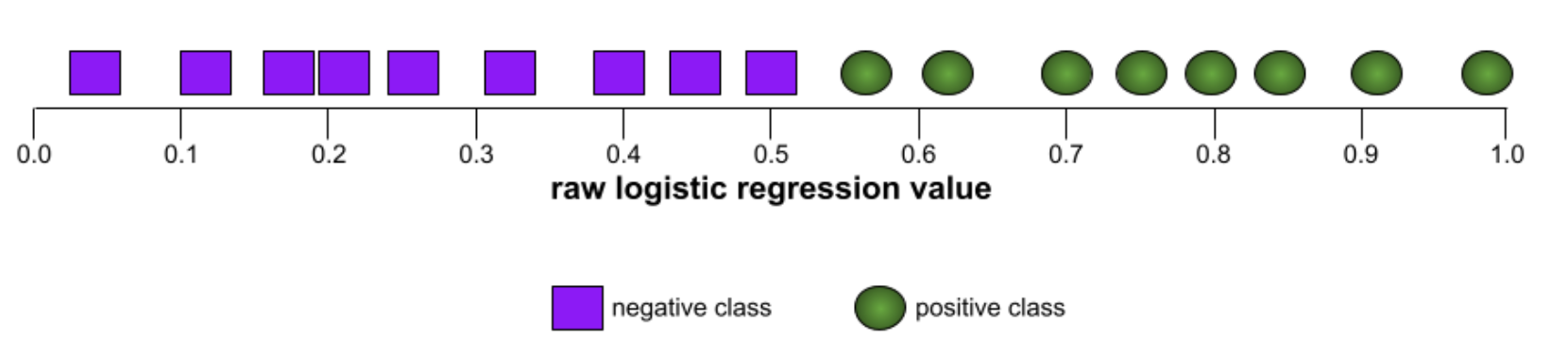
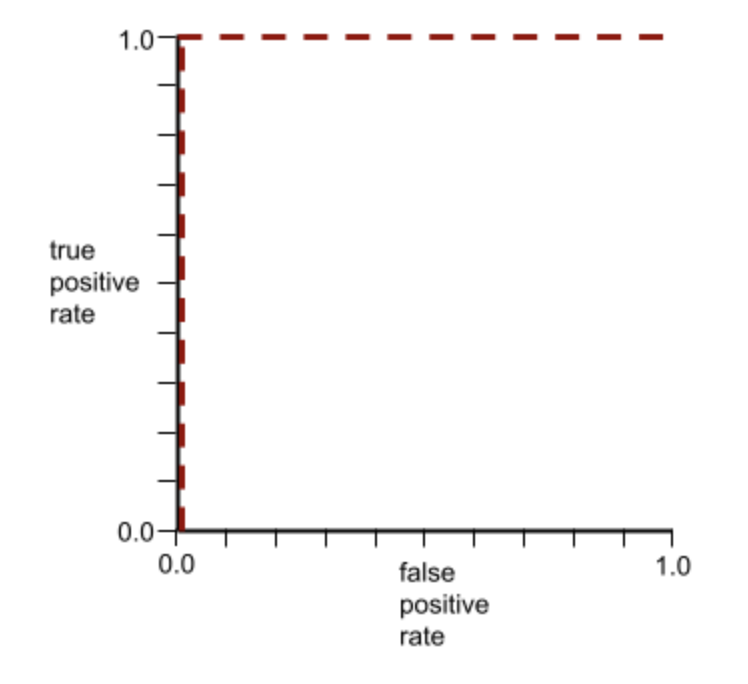
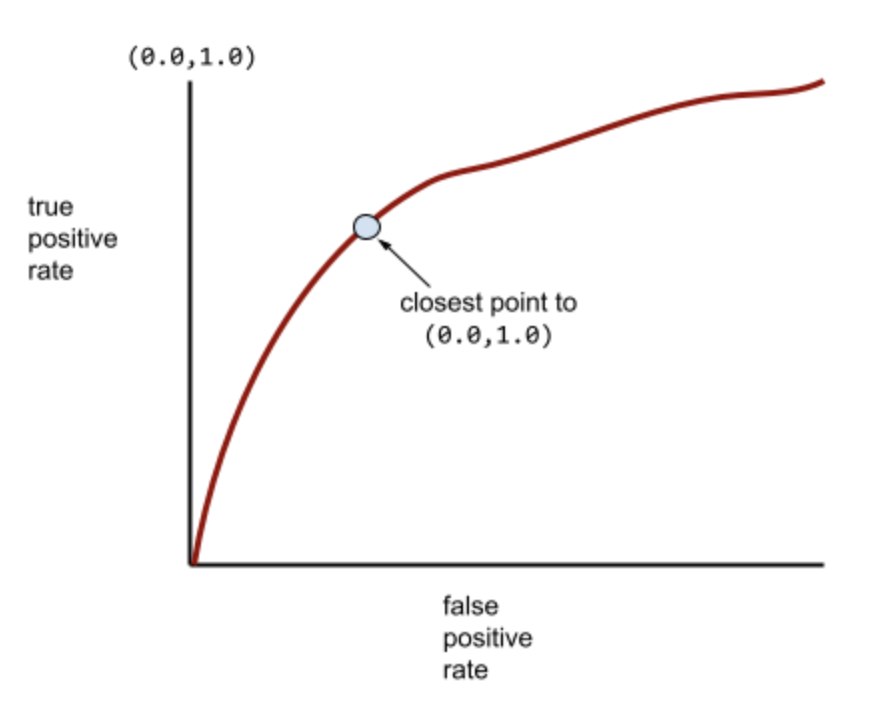
The point on an ROC curve closest to (0.0,1.0) theoretically identifies the ideal classification threshold. However, several other real-world issues influence the selection of the ideal classification threshold. For example, perhaps false negatives cause far more pain than false positives.A numerical metric called AUC summarizes the ROC curve into a single floating-point value.AUC (Area Under the ROC Curve)A number between 0.0 and 1.0 representing a binary classification model's ability to separate positive classes from negative classes. The closer the AUC is to 1.0, the better the model's ability to separate classes from each other.For example, the following illustration shows a classifier model that separates positive classes (green ovals) from negative classes (purple rectangles) perfectly. This unrealistically perfect model has an AUC of 1.0:
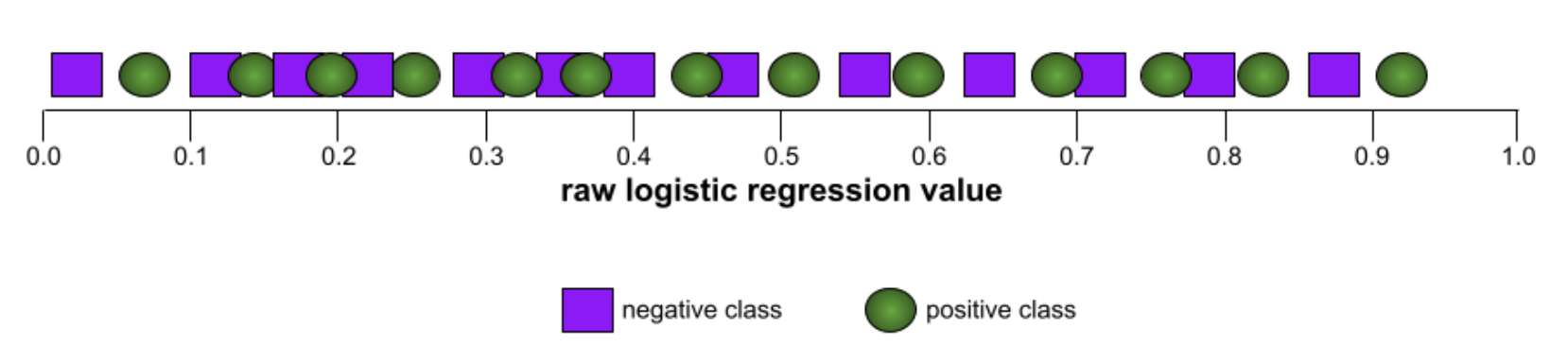
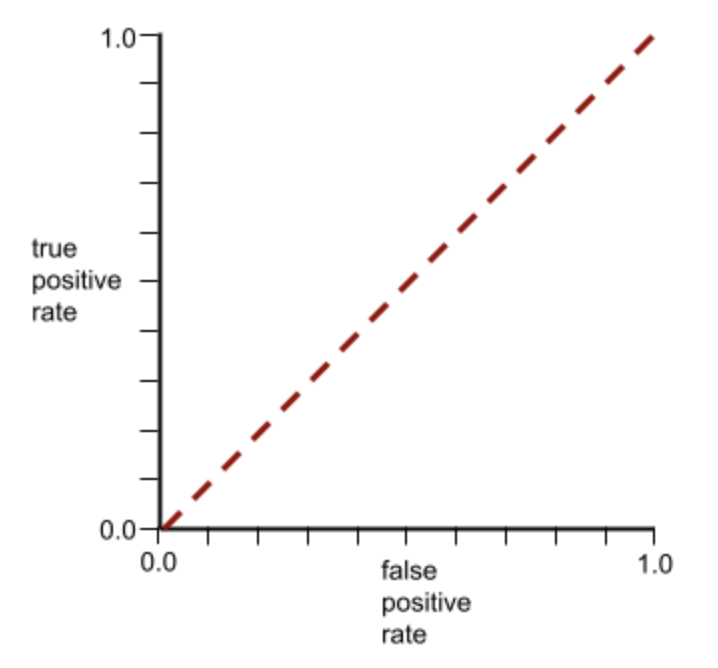
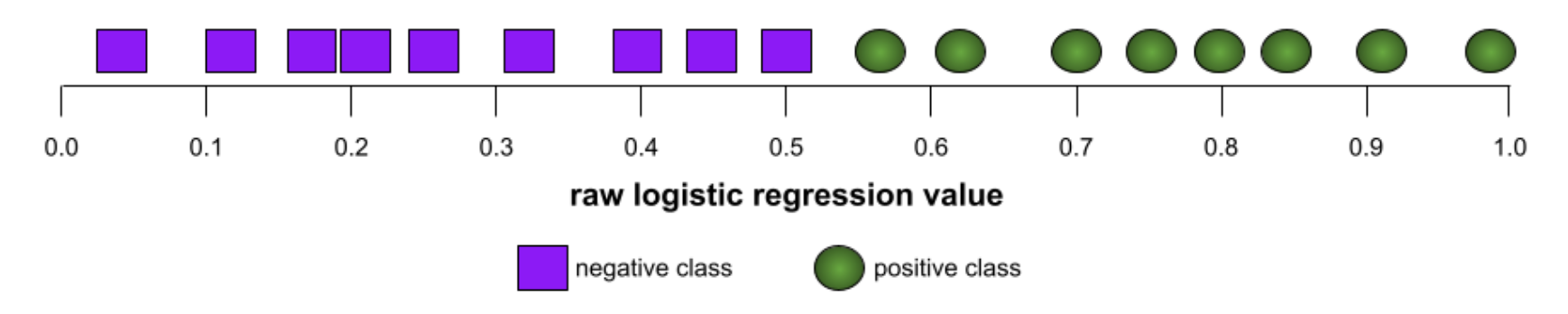
Conversely, the following illustration shows the results for a classifier model that generated random results. This model has an AUC of 0.5:
Yes, the preceding model has an AUC of 0.5, not 0.0.Most models are somewhere between the two extremes. For instance, the following model separates positives from negatives somewhat, and therefore has an AUC somewhere between 0.5 and 1.0:
AUC ignores any value you set for classification threshold. Instead, AUC considers all possible classification thresholds.Relationship Between ROC and AUCAUC represents the area under an ROC curve. For example, the ROC curve for a model that perfectly separates positives from negatives looks as follows:
AUC is the area of the gray region in the preceding illustration. In this unusual case, the area is simply the length of the gray region (1.0) multiplied by the width of the gray region (1.0). So, the product of 1.0 and 1.0 yields an AUC of exactly 1.0, which is the highest possible AUC score.Conversely, the ROC curve for a classifier that can't separate classes at all is as follows. The area of this gray region is 0.5.
A more typical ROC curve looks approximately like the following:
It would be painstaking to calculate the area under this curve manually, which is why a program typically calculates most AUC values.Formal Definition of AUCAUC is the probability that a classifier will be more confident that a randomly chosen positive example is actually positive than that a randomly chosen negative example is positive.
Back To Top5. Prepare Your Data• Before our data can be fed to a model, it needs to be transformed to a format the model can understand.• First, the data samples that we have gathered may be in a specific order. – We do not want any information associated with the ordering of samples to influence the relationship between texts and labels. – For example, if a dataset is sorted by class and is then split into training/validation sets, these sets will not be representative of the overall distribution of data.– A simple best practice to ensure the model is not affected by data order is to always shuffle the data before doing anything else. – If your data is already split into training and validation sets, make sure to transform your validation data the same way you transform your training data. – If you don’t already have separate training and validation sets, you can split the samples after shuffling; it’s typical to use 80% of the samples for training and 20% for validation.• • Second, machine learning algorithms take numbers as inputs. This means that we will need to convert the texts into numerical vectors. There are two steps to this process:– Tokenization: Divide the texts into words or smaller sub-texts, which will enable good generalization of relationship between the texts and the labels. * This determines the “vocabulary” of the dataset (set of unique tokens present in the data).– Vectorization: Define a good numerical measure to characterize these texts.• • Let’s see how to perform these two steps for both n-gramvectors and sequence vectors, as well as how to optimize the vector representations using feature selection and normalization techniques.5.1. N-gram vectors [Option A]• In an n-gram vector, text is represented as a collection of unique n-grams: – Groups of n adjacent tokens (typically, words). – Consider the text "The mouse ran up the clock". * Here, the word unigrams (n = 1) are ['the', 'mouse', 'ran', 'up', 'clock'], the word bigrams (n = 2) are ['the mouse', 'mouse ran', 'ran up', 'up the', 'the clock'], and so on.5.1.1. Tokenization• We have found that tokenizing into word unigrams + bigrams provides good accuracy while taking less compute time.5.1.2. Vectorization• Once we have split our text samples into n-grams, we need to turn these n-grams into numerical vectors that our machine learning models can process. • The example below shows the indexes assigned to the unigrams and bigrams generated for two texts.
Texts:'The mouse ran up the clock' and 'The mouse ran down'Index assigned for every token:{'the':7,'mouse':2,'ran':4,'up':10,'clock':0,'the mouse':9,'mouse ran':3,'ran up':6,'up the':11, 'theclock': 8, 'down': 1, 'ran down':5}
• Once indexes are assigned to the n-grams, we typically vectorize using one of the following options.• One-hot encoding: Every sample text is represented as a vector indicating the presence or absence of a token in the text.
'The mouse ran up the clock'=[1,0,1,1,1,0,1,1,1,1,1,1]
• Count encoding: Every sample text is represented as a vector indicating the count of a token in the text. – Note that the element corresponding to the unigram 'the' (bolded below) now is represented as 2 because the word “the” appears twice in the text.
'The mouse ran up the clock'=[1,0,1,1,1,0,1,2,1,1,1,1]
• Tf-idf encoding: The problem with the above two approaches is that common words that occur in similar frequencies in all documents (i.e., words that are not particularly unique to the text samples in the dataset) are not penalized. – For example, words like “a” will occur very frequently in all texts. So a higher token count for “the” than for other more meaningful words is not very useful.
'The mouse ran up the clock'=[0.33,0,0.23,0.23,0.23,0,0.33,0.47,0.33,0.23,0.33,0.33](See Scikit-learn TfidfTransformer)
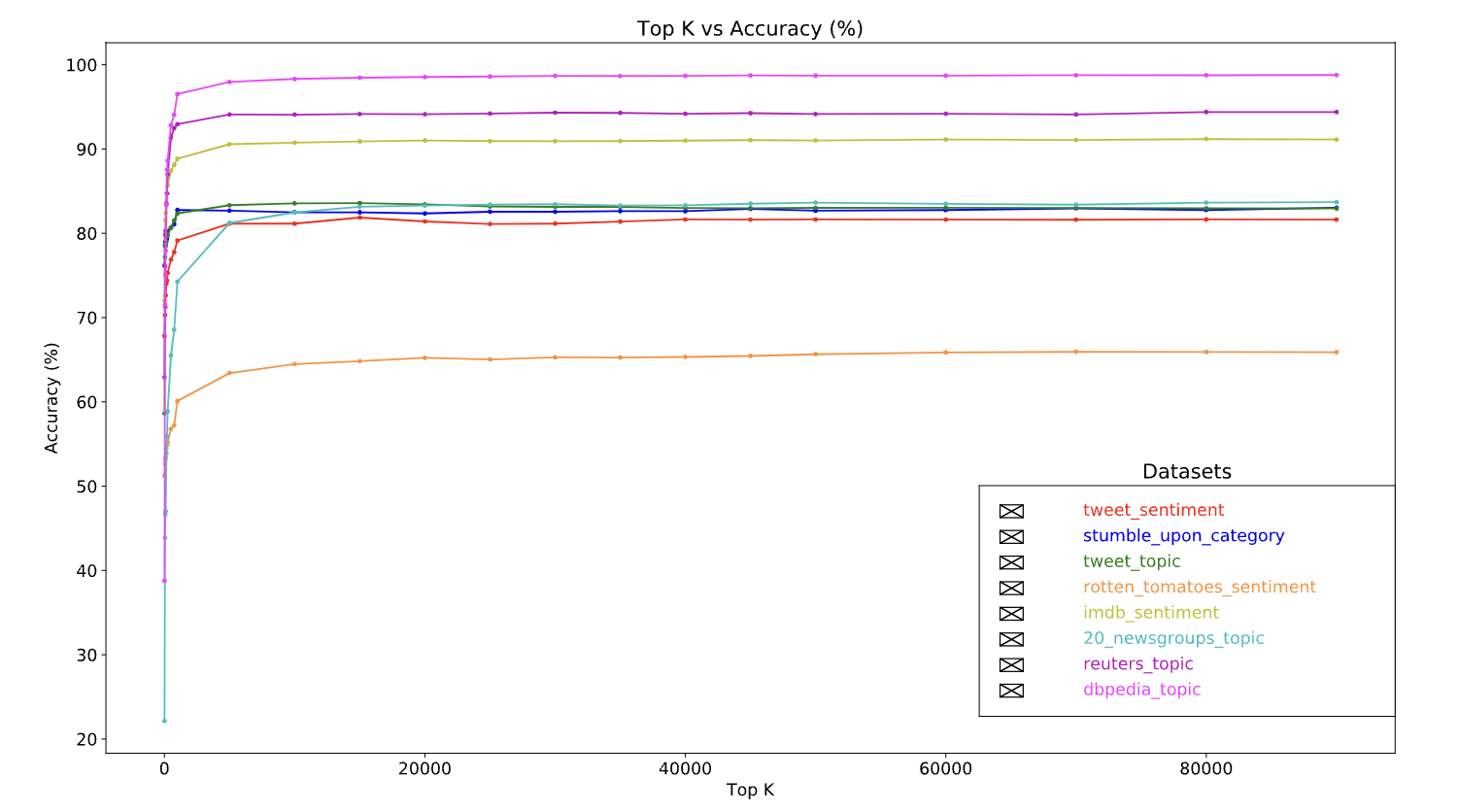
• There are many other vector representations, but the above three are the most commonly used.• Note: We observed that tf-idf encoding is marginally better than the other two in terms of accuracy (on average: 0.25-15% higher), and recommend using this method for vectorizing n-grams. However, keep in mind that it occupies more memory (as it uses floating-point representation) and takes more time to compute, especially for large datasets (can take twice as long in some cases).5.1.3. Feature Selection• When we convert all of the texts in a dataset into word uni+bigram tokens, we may end up with tens of thousands of tokens. – Not all of these tokens/features contribute to label prediction. – So we can drop certain tokens, for instance those that occur extremely rarely across the dataset. – We can also measure feature importance (how much each token contributes to label predictions), and only include the most informative tokens.• There are many statistical functions that take features and the corresponding labels and output the feature importance score. • • Two commonly used functions are:– f_classif– chi2• Our experiments show that both of these functions perform equally well.• More importantly, we saw that accuracy peaks at around 20,000 features for many datasets (See Figure 5). – Adding more features over this threshold contributes very little and sometimes even leads to overfitting and degrades performance.–
Figure 5:Top K features versus Accuracy. Across datasets, accuracy plateaus at around top 20K features.
5.1.4. Normalization• Normalization converts all feature/sample values to small and similar values. – This simplifies gradient descent convergence in learning algorithms. – From what we have seen, normalization during data preprocessing does not seem to add much value in text classification problems; we recommend skipping this step.• The following code puts together all of the above steps:– Tokenize text samples into word uni+bigrams,– Vectorize using tf-idf encoding,– Select only the top 20,000 features from the vector of tokens by discarding tokens that appear fewer than 2 times and using f_classif to calculate feature importance.
from sklearn.feature_extraction.text import TfidfVectorizerfrom sklearn.feature_selection import SelectKBestfrom sklearn.feature_selection import f_classif# Vectorization parameters# Range (inclusive) of n-gram sizes for tokenizing text.NGRAM_RANGE =(1,2)# Limit on the number of features. We use the top 20K features.TOP_K =20000# Whether text should be split into word or character n-grams.# One of 'word', 'char'.TOKEN_MODE ='word'# Minimum document/corpus frequency below which a token will be discarded.MIN_DOCUMENT_FREQUENCY =2defngram_vectorize(train_texts, train_labels, val_texts):"""Vectorizes texts as n-gram vectors. 1 text = 1 tf-idf vector the length of vocabulary of unigrams + bigrams. # Arguments train_texts: list, training text strings. train_labels: np.ndarray, training labels. val_texts: list, validation text strings. # Returns x_train, x_val: vectorized training and validation texts """# Create keyword arguments to pass to the 'tf-idf' vectorizer. kwargs ={'ngram_range': NGRAM_RANGE,# Use 1-grams + 2-grams.'dtype':'int32','strip_accents':'unicode','decode_error':'replace','analyzer': TOKEN_MODE,# Split text into word tokens.'min_df': MIN_DOCUMENT_FREQUENCY,} vectorizer = TfidfVectorizer(**kwargs)# Learn vocabulary from training texts and vectorize training texts. x_train = vectorizer.fit_transform(train_texts)# Vectorize validation texts. x_val = vectorizer.transform(val_texts)# Select top 'k' of the vectorized features. selector = SelectKBest(f_classif, k=min(TOP_K, x_train.shape[1])) selector.fit(x_train, train_labels) x_train = selector.transform(x_train).astype('float32') x_val = selector.transform(x_val).astype('float32')return x_train, x_val
• With n-gram vector representation, we discard a lot of information about word order and grammar (at best, we can maintain some partial ordering information when n > 1). • • This is called a bag-of-words approach. – This representation is used in conjunction with models that don’t take ordering into account, such as logistic regression, multi-layer perceptrons, gradient boosting machines, support vector machines.5.2. Sequence Vectors [Option B]• For some text samples, word order is critical to the text’s meaning. – For example, the sentences, “I used to hate my commute. My new bike changed that completely” can be understood only when read in order. – Models such as CNNs/RNNs can infer meaning from the order of words in a sample. – For these models, we represent the text as a sequence of tokens, preserving order.5.2.1. Tokenization• Text can be represented as either a sequence of characters, or a sequence of words. • We have found that using word-level representation provides better performance than character tokens. – This is also the general norm that is followed by industry. Using character tokens makes sense only if texts have lots of typos, which isn’t normally the case.5.2.2. Vectorization• Once we have converted our text samples into sequences of words, we need to turn these sequences into numerical vectors. • The example below shows the indexes assigned to the unigrams generated for two texts, and then the sequence of token indexes to which the first text is converted.
Texts:'The mouse ran up the clock' and 'The mouse ran down'Index assigned for every token:{'clock':5,'ran':3,'up':4,'down':6,'the':1,'mouse':2}.NOTE:'the' occurs most frequently, so the index value of1 is assigned to it.Some libraries reserve index 0for unknown tokens,as is the case here.Sequence of token indexes:'The mouse ran up the clock'=[1,2,3,4,1,5]
• There are two options available to vectorize the token sequences:– One-hot encoding: Sequences are represented using word vectors in n-dimensional space where n = size of vocabulary. * This representation works great when we are tokenizing as characters, and the vocabulary is therefore small. * When we are tokenizing as words, the vocabulary will usually have tens of thousands of tokens, making the one-hot vectors very sparse and inefficient. * •
'The mouse ran up the clock'=[[0,1,0,0,0,0,0],[0,0,1,0,0,0,0],[0,0,0,1,0,0,0],[0,0,0,0,1,0,0],[0,1,0,0,0,0,0],[0,0,0,0,0,1,0]]
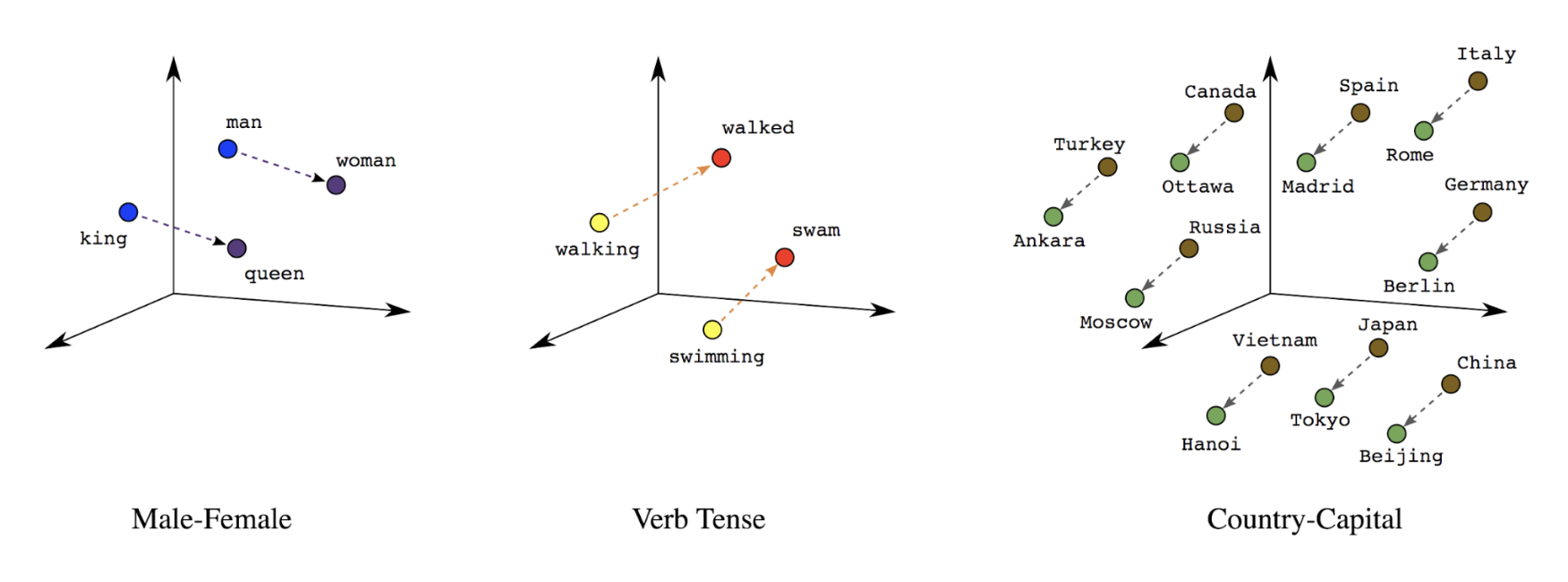
• – Word embeddings: Words have meaning(s) associated with them. * As a result, we can represent word tokens in a dense vector space (~ few hundred real numbers), where the location and distance between words indicates how similar they are semantically (See Figure 6). This representation is called word embeddings.
Figure 6:Word embeddings
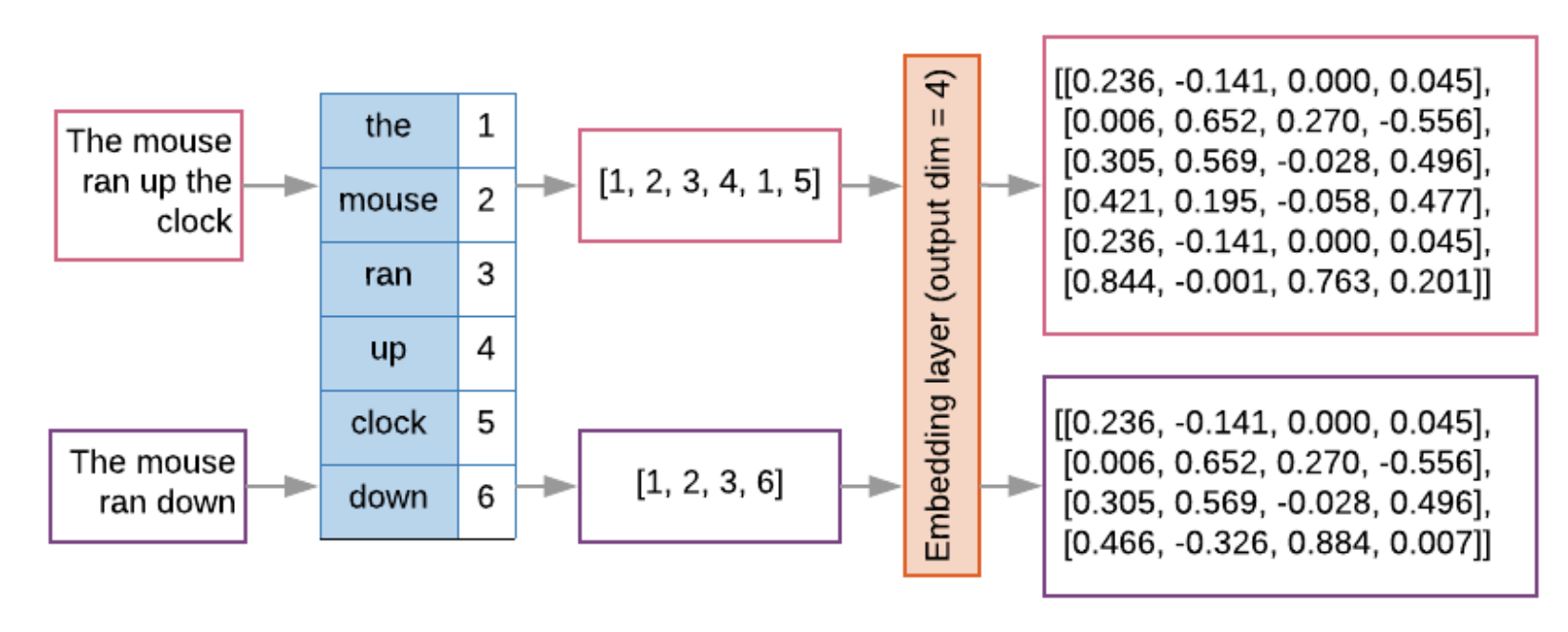
• Sequence models often have such an embedding layer as their first layer. • This layer learns to turn word index sequences into word embedding vectors during the training process, such that each word index gets mapped to a dense vector of real values representing that word’s location in semantic space (See Figure 7).
Figure 7:Embedding layer
5.2.3. Feature Selection• Let’s put all of the above steps in sequence vectorization together. The following code performs these tasks:– Tokenizes the texts into words– Creates a vocabulary using the top 20,000 tokens– Converts the tokens into sequence vectors– Pads the sequences to a fixed sequence length
from tensorflow.python.keras.preprocessing import sequencefrom tensorflow.python.keras.preprocessing import text# Vectorization parameters# Limit on the number of features. We use the top 20K features.TOP_K =20000# Limit on the length of text sequences. Sequences longer than this# will be truncated.MAX_SEQUENCE_LENGTH =500defsequence_vectorize(train_texts, val_texts):"""Vectorizes texts as sequence vectors. 1 text = 1 sequence vector with fixed length. # Arguments train_texts: list, training text strings. val_texts: list, validation text strings. # Returns x_train, x_val, word_index: vectorized training and validation texts and word index dictionary. """# Create vocabulary with training texts. tokenizer = text.Tokenizer(num_words=TOP_K) tokenizer.fit_on_texts(train_texts)# Vectorize training and validation texts. x_train = tokenizer.texts_to_sequences(train_texts) x_val = tokenizer.texts_to_sequences(val_texts)# Get max sequence length. max_length =len(max(x_train, key=len))if max_length > MAX_SEQUENCE_LENGTH: max_length = MAX_SEQUENCE_LENGTH# Fix sequence length to max value. Sequences shorter than the length are# padded in the beginning and sequences longer are truncated# at the beginning. x_train = sequence.pad_sequences(x_train, maxlen=max_length) x_val = sequence.pad_sequences(x_val, maxlen=max_length)return x_train, x_val, tokenizer.word_index
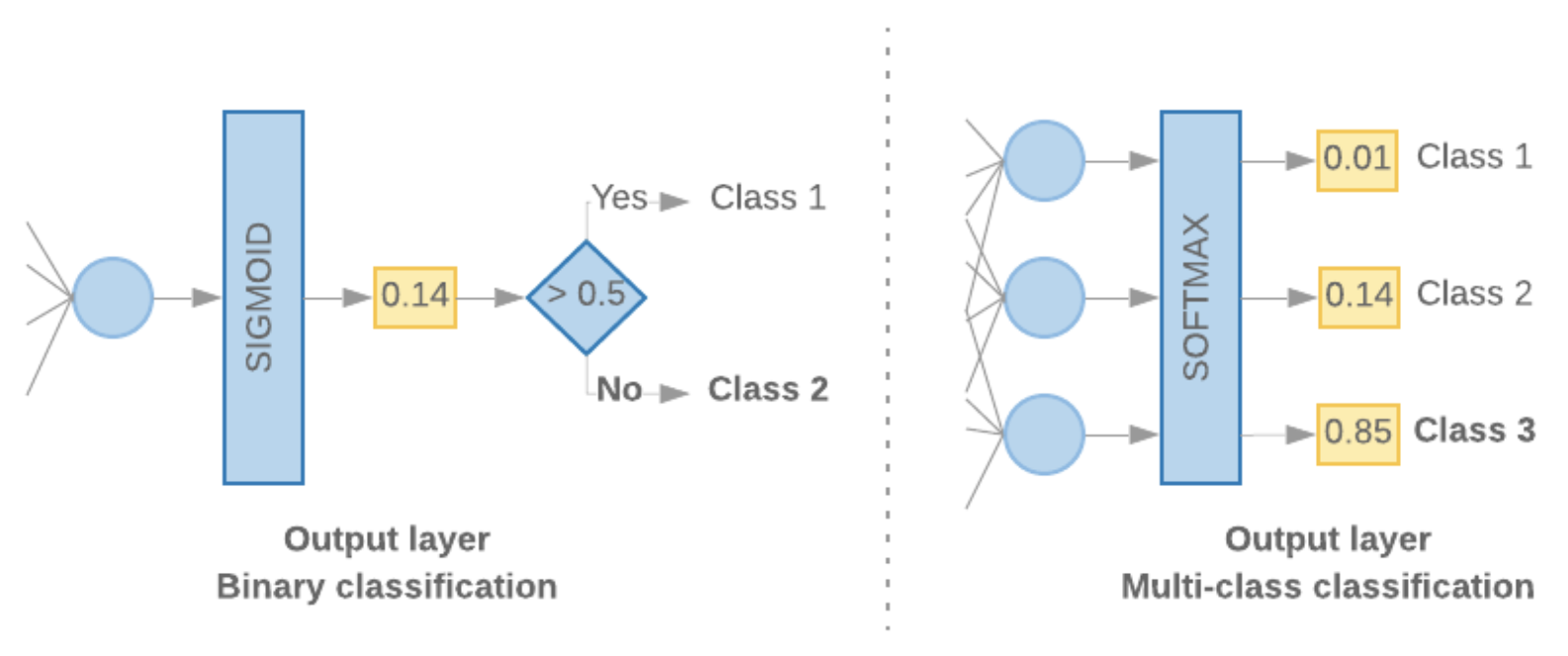
5.2.4. Label vectorization• We can simply convert labels into values in range [0, num_classes - 1]. – For example, if there are 3 classes we can just use values 0, 1 and 2 to represent them. – Internally, the network will use one-hot vectors to represent these values (to avoid inferring an incorrect relationship between labels). – This representation depends on the loss function and the last-layer activation function we use in our neural network. We will learn more about these in the next section.Back To Top6. Build, Train, and Evaluate Your Model• In Step 3, we chose to use either an n-gram model or sequence model, using our S/W ratio. • Now, it’s time to write our classification algorithm and train it. We will use TensorFlow with the tf.keras API for this.• Building machine learning models with Keras is all about assembling together layers, data-processing building blocks, much like we would assemble Lego bricks. • These layers allow us to specify the sequence of transformations we want to perform on our input. • As our learning algorithm takes in a single text input and outputs a single classification, we can create a linear stack of layers using the Sequential model API.• The input layer and the intermediate layers will be constructed differently, depending on whether we’re building an n-gram or a sequence model. But irrespective of model type, the last layer will be the same for a given problem.6.1. Constructing the Last Layer• To output such a probability score for binary classification, the activation function of the last layer should be a sigmoid function, and the loss function used to train the model should be binary cross-entropy (See Figure 8, left).• In case of multi-class classification, the activation function of the last layer should be softmax, and the loss function used to train the model should be categorical cross-entropy. (See Figure 8, right).
Figure 8:Last layer
• The following code defines a function that takes the number of classes as input, and outputs the appropriate number of layer units (1 unit for binary classification; otherwise 1 unit for each class) and the appropriate activation function:
def_get_last_layer_units_and_activation(num_classes):"""Gets the # units and activation function for the last network layer. # Arguments num_classes: int, number of classes. # Returns units, activation values. """if num_classes ==2: activation ='sigmoid' units =1else: activation ='softmax' units = num_classesreturn units, activation
• When the S/W ratio is small, we’ve found that n-gram models perform better than sequence models.– Sequence models are better when there are a large number of small, dense vectors.* This is because embedding relationships are learned in dense space, and this happens best over many samples.6.2. Build n-gram model [Option A]• We refer to models that process the tokens independently (not taking into account word order) as n-gram models. • Simple multi-layer perceptrons (including logistic regression), gradient boosting machines and support vector machines models all fall under this category; they cannot leverage any information about text ordering.• We compared the performance of some of the n-gram models mentioned above and observed that multi-layer perceptrons (MLPs) typically perform better than other options. – MLPs are simple to define and understand, provide good accuracy, and require relatively little computation.• The following code defines a two-layer MLP model in tf.keras, adding a couple of Dropout layers for regularization (to prevent overfitting to training samples).
• Dropout Regularization: A form of regularization useful in training neural networks. Dropout regularization removes a random selection of a fixed number of the units in a network layer for a single gradient step. The more units dropped out, the stronger the regularization. This is analogous to training the network to emulate an exponentially large ensemble of smaller networks.
from tensorflow.python.keras import modelsfrom tensorflow.python.keras.layers import Densefrom tensorflow.python.keras.layers import Dropoutdefmlp_model(layers, units, dropout_rate, input_shape, num_classes):"""Creates an instance of a multi-layer perceptron model. # Arguments layers: int, number of `Dense` layers in the model. units: int, output dimension of the layers. dropout_rate: float, percentage of input to drop at Dropout layers. input_shape: tuple, shape of input to the model. num_classes: int, number of output classes. # Returns An MLP model instance. """ op_units, op_activation = _get_last_layer_units_and_activation(num_classes) model = models.Sequential() model.add(Dropout(rate=dropout_rate, input_shape=input_shape))for _ inrange(layers-1): model.add(Dense(units=units, activation='relu')) model.add(Dropout(rate=dropout_rate)) model.add(Dense(units=op_units, activation=op_activation))return model
6.3. Build sequence model [Option B]• We refer to models that can learn from the adjacency of tokens as sequence models. – This includes CNN and RNN classes of models. Data is pre-processed as sequence vectors for these models.• Sequence models generally have a larger number of parameters to learn. – The first layer in these models is an embedding layer, which learns the relationship between the words in a dense vector space. – Learning word relationships works best over many samples.• Words in a given dataset are most likely not unique to that dataset. We can thus learn the relationship between the words in our dataset using other dataset(s). – To do so, we can transfer an embedding learned from another dataset into our embedding layer. These embeddings are referred to as pre-trained embeddings.• There are pre-trained embeddings available that have been trained using large corpora, such as GloVe. GloVe has been trained on multiple corpora (primarily Wikipedia). – We tested training our sequence models using a version of GloVe embeddings and observed that if we froze the weights of the pre-trained embeddings and trained just the rest of the network, the models did not perform well. – This could be because the context in which the embedding layer was trained might have been different from the context in which we were using it.• • GloVe embeddings trained on Wikipedia data may not align with the language patterns in our IMDb dataset. • The relationships inferred may need some updating—i.e., the embedding weights may need contextual tuning. We do this in two stages:1. In the first run, with the embedding layer weights frozen, we allow the rest of the network to learn. At the end of this run, the model weights reach a state that is much better than their uninitialized values. For the second run, we allow the embedding layer to also learn, making fine adjustments to all weights in the network. We refer to this process as using a fine-tuned embedding.2. Fine-tuned embeddings yield better accuracy. * However, this comes at the expense of increased compute power required to train the network. * Given a sufficient number of samples, we could do just as well learning an embedding from scratch. * We observed that for S/W > 15K, starting from scratch effectively yields about the same accuracy as using fine-tuned embedding.• We compared different sequence models such as CNN, sepCNN, RNN (LSTM & GRU), CNN-RNN, and stacked RNN, varying the model architectures. • We found that sepCNNs, a convolutional network variant that is often more data-efficient and compute-efficient, perform better than the other models.• Note: RNNs are relevant only to a small subset of use-cases. We did not try models like QRNN or RNNs with Attention, as their accuracy improvements would be offset by higher computational costs.• The following code constructs a four-layer sepCNN model:
from tensorflow.python.keras import modelsfrom tensorflow.python.keras import initializersfrom tensorflow.python.keras import regularizersfrom tensorflow.python.keras.layers import Densefrom tensorflow.python.keras.layers import Dropoutfrom tensorflow.python.keras.layers import Embeddingfrom tensorflow.python.keras.layers import SeparableConv1Dfrom tensorflow.python.keras.layers import MaxPooling1Dfrom tensorflow.python.keras.layers import GlobalAveragePooling1Ddefsepcnn_model(blocks, filters, kernel_size, embedding_dim, dropout_rate, pool_size, input_shape, num_classes, num_features, use_pretrained_embedding=False, is_embedding_trainable=False, embedding_matrix=None):"""Creates an instance of a separable CNN model. # Arguments blocks: int, number of pairs of sepCNN and pooling blocks in the model. filters: int, output dimension of the layers. kernel_size: int, length of the convolution window. embedding_dim: int, dimension of the embedding vectors. dropout_rate: float, percentage of input to drop at Dropout layers. pool_size: int, factor by which to downscale input at MaxPooling layer. input_shape: tuple, shape of input to the model. num_classes: int, number of output classes. num_features: int, number of words (embedding input dimension). use_pretrained_embedding: bool, true if pre-trained embedding is on. is_embedding_trainable: bool, true if embedding layer is trainable. embedding_matrix: dict, dictionary with embedding coefficients. # Returns A sepCNN model instance. """ op_units, op_activation = _get_last_layer_units_and_activation(num_classes) model = models.Sequential()# Add embedding layer. If pre-trained embedding is used add weights to the# embeddings layer and set trainable to input is_embedding_trainable flag.if use_pretrained_embedding: model.add(Embedding(input_dim=num_features, output_dim=embedding_dim, input_length=input_shape[0], weights=[embedding_matrix], trainable=is_embedding_trainable))else: model.add(Embedding(input_dim=num_features, output_dim=embedding_dim, input_length=input_shape[0]))for _ inrange(blocks-1): model.add(Dropout(rate=dropout_rate)) model.add(SeparableConv1D(filters=filters, kernel_size=kernel_size, activation='relu', bias_initializer='random_uniform', depthwise_initializer='random_uniform', padding='same')) model.add(SeparableConv1D(filters=filters, kernel_size=kernel_size, activation='relu', bias_initializer='random_uniform', depthwise_initializer='random_uniform', padding='same')) model.add(MaxPooling1D(pool_size=pool_size)) model.add(SeparableConv1D(filters=filters *2, kernel_size=kernel_size, activation='relu', bias_initializer='random_uniform', depthwise_initializer='random_uniform', padding='same')) model.add(SeparableConv1D(filters=filters *2, kernel_size=kernel_size, activation='relu', bias_initializer='random_uniform', depthwise_initializer='random_uniform', padding='same')) model.add(GlobalAveragePooling1D()) model.add(Dropout(rate=dropout_rate)) model.add(Dense(op_units, activation=op_activation))return model
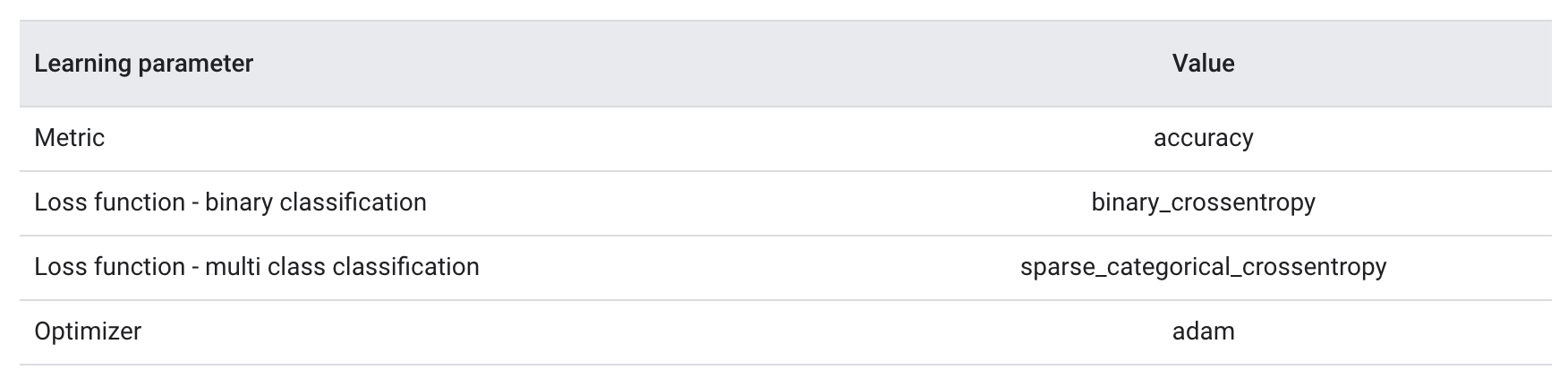
6.4. Train Your Model• There are three key parameters to be chosen for this process (See Table 2).– Metric: How to measure the performance of our model using a metric. We used accuracy as the metric in our experiments.– Loss function: A function that is used to calculate a loss value that the training process then attempts to minimize by tuning the network weights. For classification problems, cross-entropy loss works well.– Optimizer: A function that decides how the network weights will be updated based on the output of the loss function. We used the popular Adam optimizer in our experiments.• In Keras, we can pass these learning parameters to a model using the compile method.
Table 2:Learning parameters
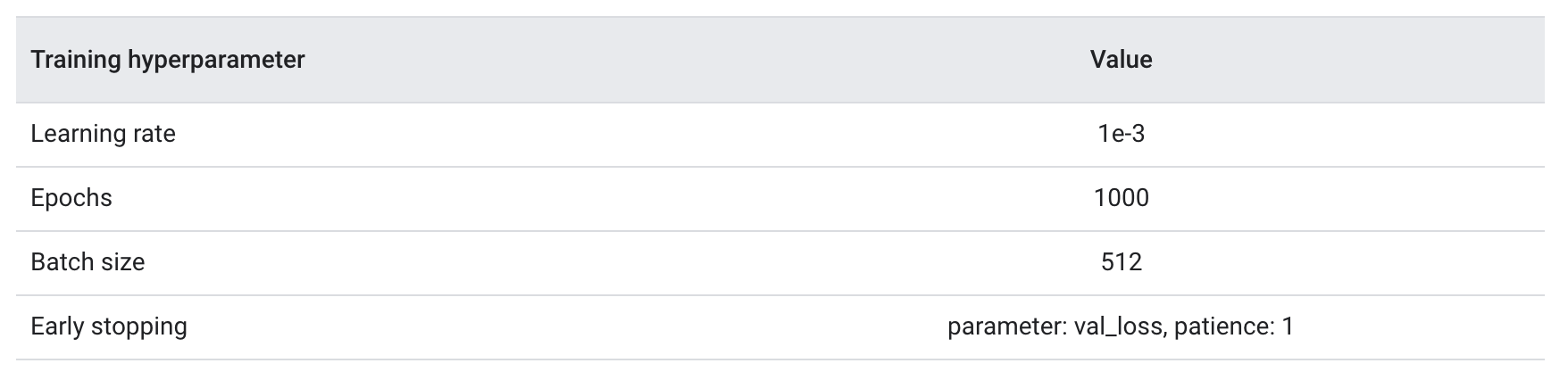
• The actual training happens using the fit method. Depending on the size of your dataset, this is the method in which most compute cycles will be spent. • In each training iteration, batch_size number of samples from your training data are used to compute the loss, and the weights are updated once, based on this value. • The training process completes an epoch once the model has seen the entire training dataset. • At the end of each epoch, we use the validation dataset to evaluate how well the model is learning. • We repeat training using the dataset for a predetermined number of epochs. • We may optimize this by stopping early, when the validation accuracy stabilizes between consecutive epochs, showing that the model is not training anymore.
Table 3:Training hyperparameters
• The following Keras code implements the training process using the parameters chosen in the Table 2 & Table 3 above. Please find code examples for training the sequence model here.
deftrain_ngram_model(data, learning_rate=1e-3, epochs=1000, batch_size=128, layers=2, units=64, dropout_rate=0.2):"""Trains n-gram model on the given dataset. # Arguments data: tuples of training and test texts and labels. learning_rate: float, learning rate for training model. epochs: int, number of epochs. batch_size: int, number of samples per batch. layers: int, number of `Dense` layers in the model. units: int, output dimension of Dense layers in the model. dropout_rate: float: percentage of input to drop at Dropout layers. # Raises ValueError: If validation data has label values which were not seen in the training data. """# Get the data.(train_texts, train_labels),(val_texts, val_labels)= data# Verify that validation labels are in the same range as training labels. num_classes = explore_data.get_num_classes(train_labels) unexpected_labels =[v for v in val_labels if v notinrange(num_classes)]iflen(unexpected_labels):raise ValueError('Unexpected label values found in the validation set:'' {unexpected_labels}. Please make sure that the ''labels in the validation set are in the same range ''as training labels.'.format( unexpected_labels=unexpected_labels))# Vectorize texts. x_train, x_val = vectorize_data.ngram_vectorize( train_texts, train_labels, val_texts)# Create model instance. model = build_model.mlp_model(layers=layers, units=units, dropout_rate=dropout_rate, input_shape=x_train.shape[1:], num_classes=num_classes)# Compile model with learning parameters.if num_classes ==2: loss ='binary_crossentropy'else: loss ='sparse_categorical_crossentropy' optimizer = tf.keras.optimizers.Adam(lr=learning_rate) model.compile(optimizer=optimizer, loss=loss, metrics=['acc'])# Create callback for early stopping on validation loss. If the loss does# not decrease in two consecutive tries, stop training. callbacks =[tf.keras.callbacks.EarlyStopping( monitor='val_loss', patience=2)]# Train and validate model. history = model.fit( x_train, train_labels, epochs=epochs, callbacks=callbacks, validation_data=(x_val, val_labels), verbose=2,# Logs once per epoch. batch_size=batch_size)# Print results. history = history.historyprint('Validation accuracy: {acc}, loss: {loss}'.format( acc=history['val_acc'][-1], loss=history['val_loss'][-1]))# Save model. model.save('IMDb_mlp_model.h5')return history['val_acc'][-1], history['val_loss'][-1]
Back To Top7. Tune Hyperparameters• We had to choose a number of hyperparameters for defining and training the model. • We relied on intuition, examples and best practice recommendations. • Our first choice of hyperparameter values, however, may not yield the best results. It only gives us a good starting point for training. • Every problem is different and tuning these hyperparameters will help refine our model to better represent the particularities of the problem at hand. • Let’s take a look at some of the hyperparameters we used and what it means to tune them:• – Number of layers in the model: The number of layers in a neural network is an indicator of its complexity. – We must be careful in choosing this value: * Too many layers will allow the model to learn too much information about the training data, causing overfitting. * Too few layers can limit the model’s learning ability, causing underfitting. * For text classification datasets, we experimented with one, two, and three-layer MLPs. Models with two layers performed well, and in some cases better than three-layer models. Similarly, we tried sepCNNs with four and six layers, and the four-layer models performed well.* – Number of units per layer: The units in a layer must hold the information for the transformation that a layer performs. * For the first layer, this is driven by the number of features. * In subsequent layers, the number of units depends on the choice of expanding or contracting the representation from the previous layer. * Try to minimize the information loss between layers. * We tried unit values in the range [8, 16, 32, 64], and 32/64 units worked well.– – Dropout rate: Dropout layers are used in the model for regularization. * They define the fraction of input to drop as a precaution for overfitting. Recommended range: 0.2–0.5.– – Learning rate: This is the rate at which the neural network weights change between iterations. * A large learning rate may cause large swings in the weights, and we may never find their optimal values. * A low learning rate is good, but the model will take more iterations to converge. * It is a good idea to start low, say at 1e-4. If the training is very slow, increase this value. If your model is not learning, try decreasing learning rate.• There are couple of additional hyperparameters we tuned that are specific to our sepCNN model:• – Kernel size: The size of the convolution window. Recommended values: 3 or 5.– – Embedding dimensions: The number of dimensions we want to use to represent word embeddings—i.e., the size of each word vector. * Recommended values: 50–300. * In our experiments, we used GloVe embeddings with 200 dimensions with a pre-trained embedding layer.Back To Top8. Deploy Your Model• You can train, tune and deploy machine learning models on Google Cloud. See the following resources for guidance on deploying your model to production:– Tutorial on how to export a Keras model with TensorFlow serving.– TensorFlow serving documentation.– Guide to training and deploying your model on Google Cloud.– • Please keep in mind the following key things when deploying your model:– Make sure your production data follows the same distribution as your training and evaluation data.– Regularly re-evaluate by collecting more training data.– If your data distribution changes, retrain your model.
Exporting a model with TensorFlow-servingTensorFlow Serving is a library for serving TensorFlow models in a production setting, developed by Google.Any Keras model can be exported with TensorFlow-serving (as long as it only has one input and one output, which is a limitation of TF-serving), whether or not it was training as part of a TensorFlow workflow. In fact you could even train your Keras model with Theano then switch to the TensorFlow Keras backend and export your model.Here's how it works.If your graph makes use of the Keras learning phase (different behavior at training time and test time), the very first thing to do before exporting your model is to hard-code the value of the learning phase (as 0, presumably, i.e. test mode) into your graph. This is done by 1) registering a constant learning phase with the Keras backend, and 2) re-building your model afterwards.Here are these two simple steps in action:
from keras import backend as KK.set_learning_phase(0)# all new operations will be in test mode from now on# serialize the model and get its weights, for quick re-buildingconfig = previous_model.get_config()weights = previous_model.get_weights()# re-build a model where the learning phase is now hard-coded to 0from keras.models import model_from_confignew_model = model_from_config(config)new_model.set_weights(weights)
We can now use TensorFlow-serving to export the model, following the instructions found in the official tutorial:
from tensorflow_serving.session_bundle import exporterexport_path =...# where to save the exported graphexport_version =...# version number (integer)saver = tf.train.Saver(sharded=True)model_exporter = exporter.Exporter(saver)signature = exporter.classification_signature(input_tensor=model.input, scores_tensor=model.output)model_exporter.init(sess.graph.as_graph_def(), default_graph_signature=signature)model_exporter.export(export_path, tf.constant(export_version), sess)
Batch TrainingVery large datasets may not fit in the memory allocated to your process. In the previous steps, we have set up a pipeline where we bring in the entire dataset in to the memory, prepare the data, and pass the working set to the training function. Instead, Keras provides an alternative training function (fit_generator) that pulls the data in batches. This allows us to apply the transformations in the data pipeline to only a small (a multiple of batch_size) part of the data. During our experiments, we used batching (code in GitHub) for datasets such as DBPedia, Amazon reviews, Ag news, and Yelp reviews.The following code illustrates how to generate data batches and feed them to fit_generator.
def_data_generator(x, y, num_features, batch_size):"""Generates batches of vectorized texts for training/validation. # Arguments x: np.matrix, feature matrix. y: np.ndarray, labels. num_features: int, number of features. batch_size: int, number of samples per batch. # Returns Yields feature and label data in batches. """ num_samples = x.shape[0] num_batches = num_samples // batch_sizeif num_samples % batch_size: num_batches +=1while1:for i inrange(num_batches): start_idx = i * batch_size end_idx =(i +1)* batch_sizeif end_idx > num_samples: end_idx = num_samples x_batch = x[start_idx:end_idx] y_batch = y[start_idx:end_idx]yield x_batch, y_batch# Create training and validation generators.training_generator = _data_generator( x_train, train_labels, num_features, batch_size)validation_generator = _data_generator( x_val, val_labels, num_features, batch_size)# Get number of training steps. This indicated the number of steps it takes# to cover all samples in one epoch.steps_per_epoch = x_train.shape[0]// batch_sizeif x_train.shape[0]% batch_size: steps_per_epoch +=1# Get number of validation steps.validation_steps = x_val.shape[0]// batch_sizeif x_val.shape[0]% batch_size: validation_steps +=1# Train and validate model.history = model.fit_generator( generator=training_generator, steps_per_epoch=steps_per_epoch, validation_data=validation_generator, validation_steps=validation_steps, callbacks=callbacks, epochs=epochs, verbose=2)# Logs once per epoch.