1. Model Hosting• In the last section, ?, we talked about how we will be using distributed cache for our recommendation service example.• We now talk about how we're going to host our recommendation models inside the recommendation service itself.• The recommendation service has to:– Fetch the features (often of both user and item) → we discussed this in ?– Alter the features (in most cases)* Append the user/item features* Append online features (these may not have been stored in the HDFS) like device, country, referrer, etc.– Perform inference– Map the inference to meaningful result* e.g. from an array of probabilities per item to recommended item.– Note: All of these are performed in the exploration (train/validation) step and for inference need to be repeated EXACTLY.• To ensure all the steps will repeat exactly the same we can use Spark Pipeline.2. Spark Pipeline• Spark Pipeline is a library which allows you to create a DAG of stages required to go from hosted features to usable predictions.• Let's look at an example. Let's say we have this data (split to train and test):
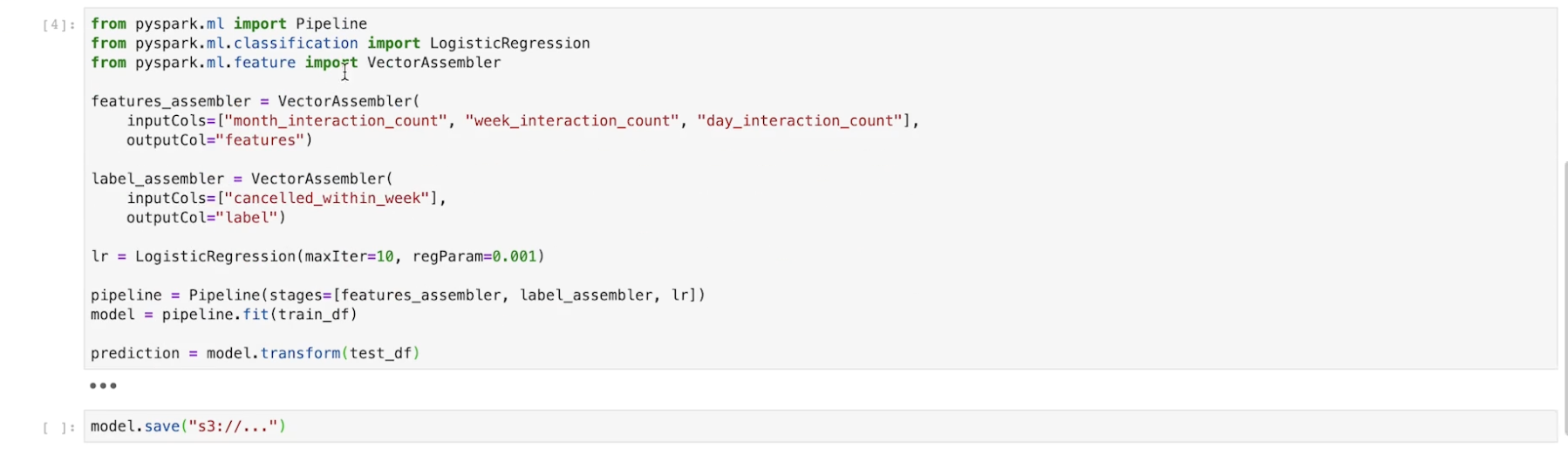
• Now, we can use Spark Pipeline to ensure same steps are done every time:
3. Latency Management• In terms of quality of our service, we have to consider its latency.• Amazon found that an extra 100 ms of latency created a 1% loss of revenue.• Google found that an extra 0.5 second load time causes a 20% traffic drop.• Now that getting an ML inference is on the critical path of rendering the home page, latency is a large concern. • Another problem is that we can't fetch the features from the distributed cache and run the model in parallel. – Since the model depends on the features, we have to do it in order.3.1. Local vs. Remote inference• Where do we want to perform the inference?– Local inference vs. remote inference– Local inference → low latency. * The problem is that the it's often the case that your recommendation service is written in a different language than you're model inference code (e.g. recommendation service in Go or Java and model inference code in Python).· In such cases, one solution is to use PMML (Predictive Model Markup Language) so that other languages could read Python.* Another problem is that the deployment of recommendation service and model inference are tied together.• Remote inference → Another option is to have a dedicated inference server to which all the recommendation services making a call. – This is great because it's language-agnostic.– Also, the deployments are no longer tied together.– Finally, the inference server could have its own specialized hardware requirements outside of what your typical web server hardware requirements would be → This configuration could accommodate that.3.2. Language optimization• In addition to local vs. remote inference, we can also look at language optimization to help manage our latency.• Python is pretty slower than some alternatives:– C/C++ is 10x-100x faster– Java is 10x-50x faster• We can use Just-In-Time (JIT) compiler tool called Numba.• Numba compiles the Python code down to machine code and it can approach latencies comparable to C and Fortran.3.3. Hardware• Generally, we want a CPU over a GPU in terms of real-time inferences. • CPU will be faster for these one-of predictions and GPUs are better for batches.3.4. Worst-case scenario• We also need to consider the worst-case scenarios. • We'd want low latency fallbacks and circuit breakers.• Fallback: If, say, some call from the client to the distributed cache takes too long (above some threshold), then we should be able to return to the user some low latency recommendation.– This could be recommending the most popular products, or it could be something a little bit more personalized → In general, it should be pretty fast.• Circuit breaker: If a service is down, after some number of re-tries the client should begin automatically falling back to the default experience.– This should only happen until the down service can come back online.4. Batch inference• Instead of having an inference server, what we could do is just store all the pre-calculated inferences on the distributed cache itself.• When would this be a good idea?– Generally, we want minimal or no online features.– We also want to make sure that the inference space is small enough.* Let's say we have 100M customers and we want to recommend only 30 titles (represented by integers) → This would require around 12 GB of space.* Now, let's say we have 100M customers but now we have 10M products to recommend from → This would be around 4 petabytes → It'd be hard to keep on the distributed cache → not a good fit for batch inference (also considering the computation required) → online inference would be better for this case.– The tradeoff would be increased latency for a decreased cost in storing large amounts of data.Back to Top