Table of Content
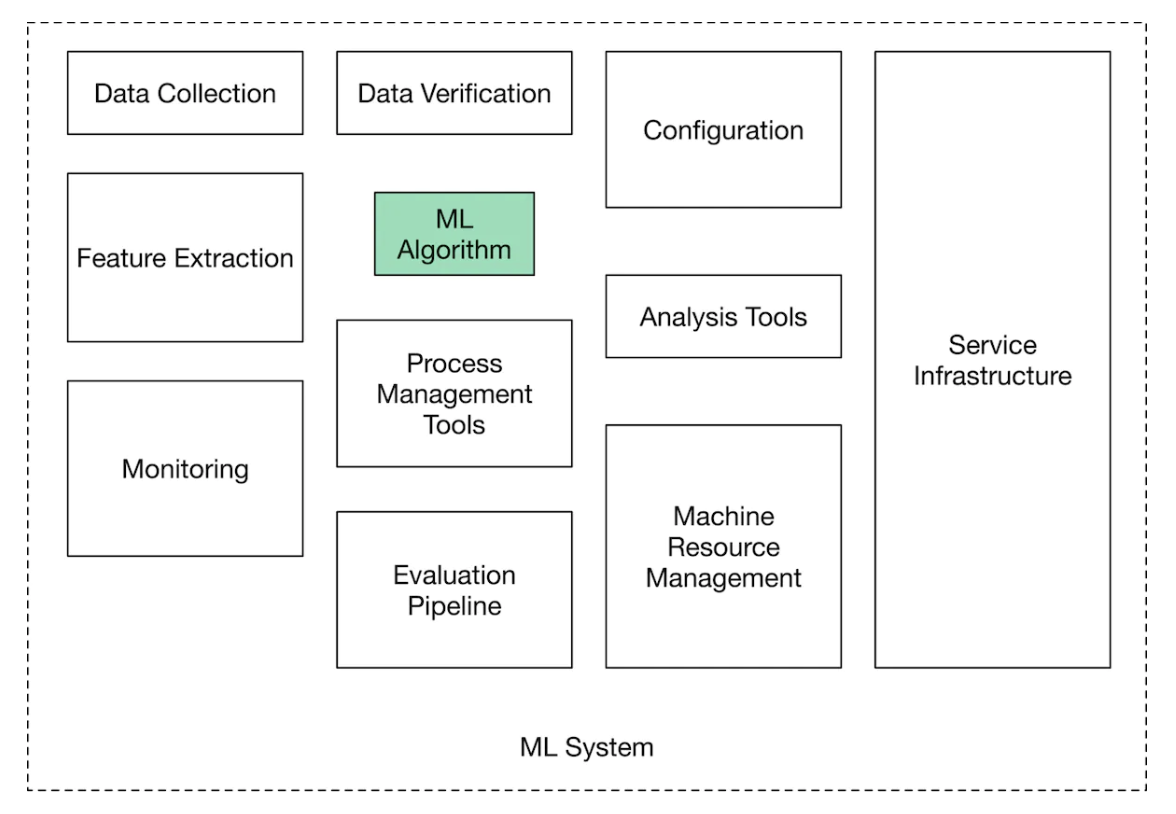
Figure 1:Components of a production-ready ML system

Figure 2:ML system design steps
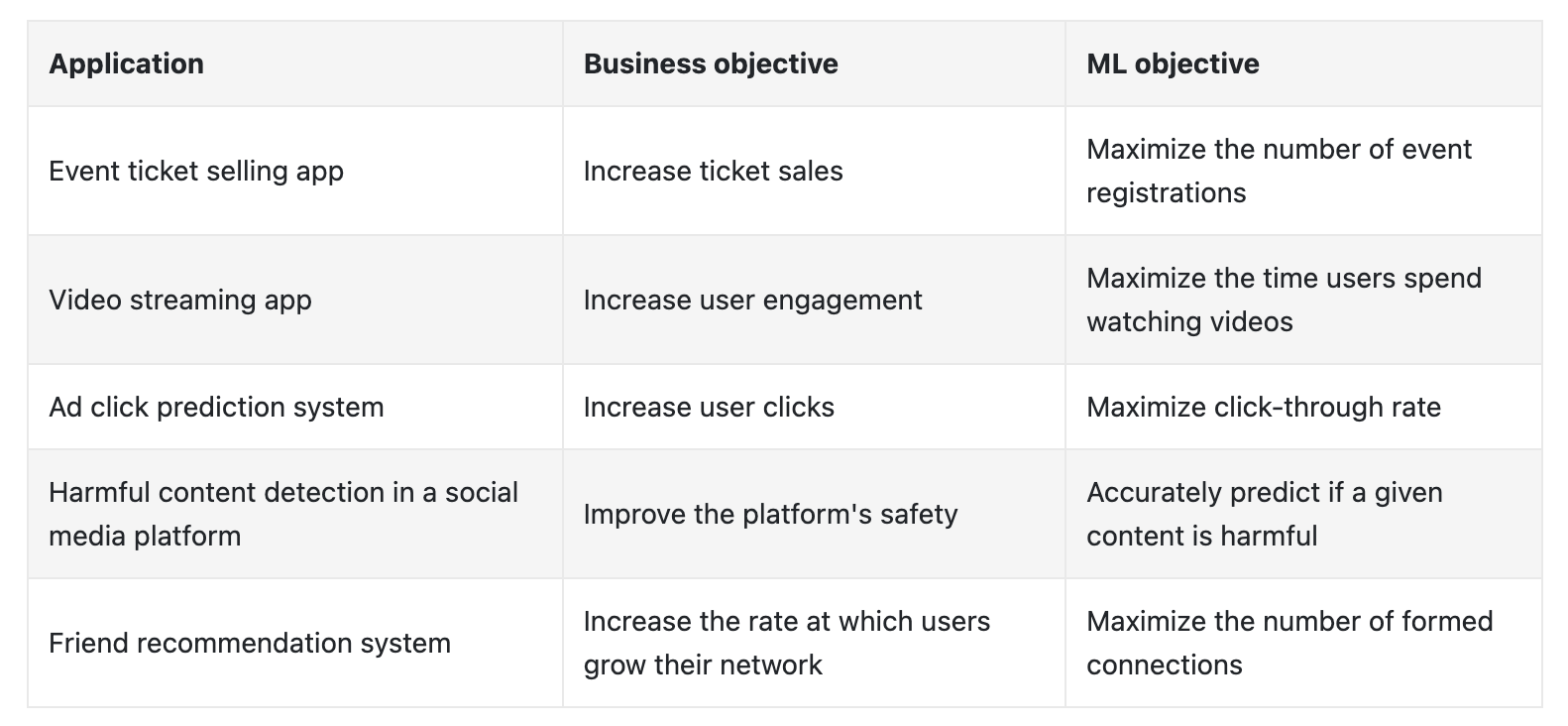
Figure 3:Translate the business objective to an ML objective
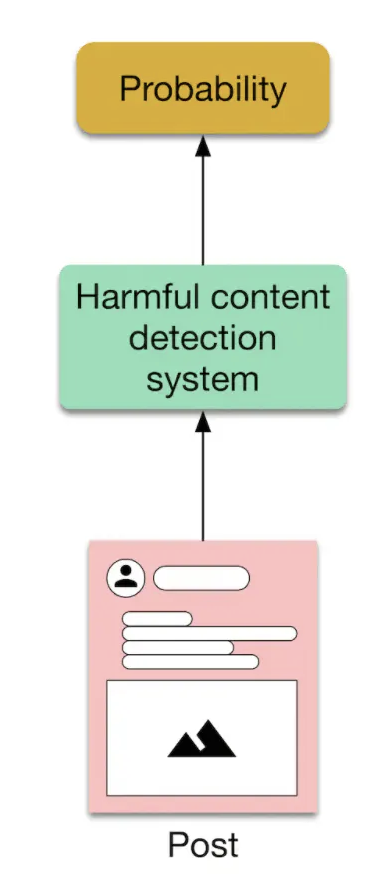
Figure 4:Harmful content detection system input-output
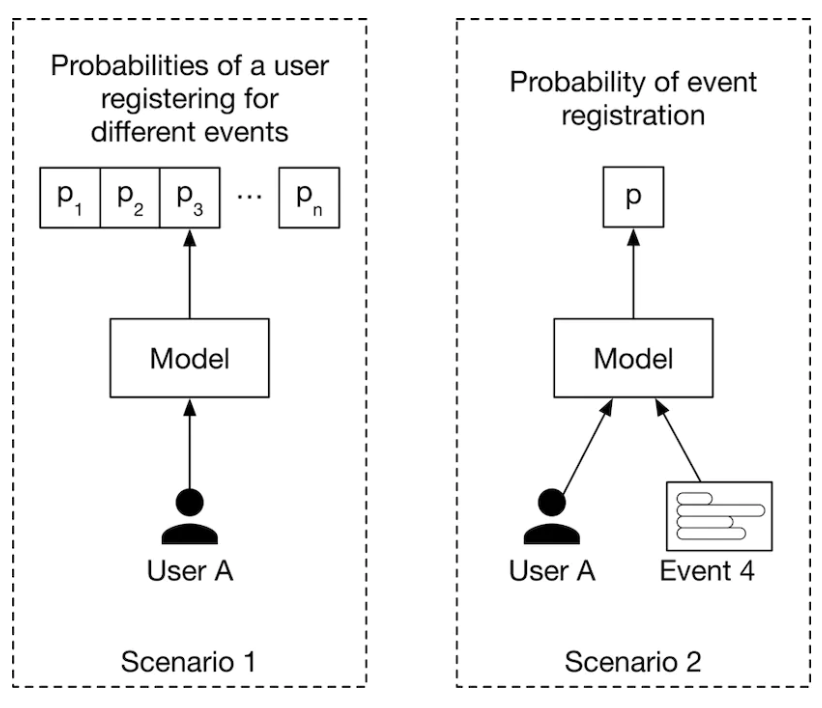
Figure 5:Different ways to specify the model’s input-output
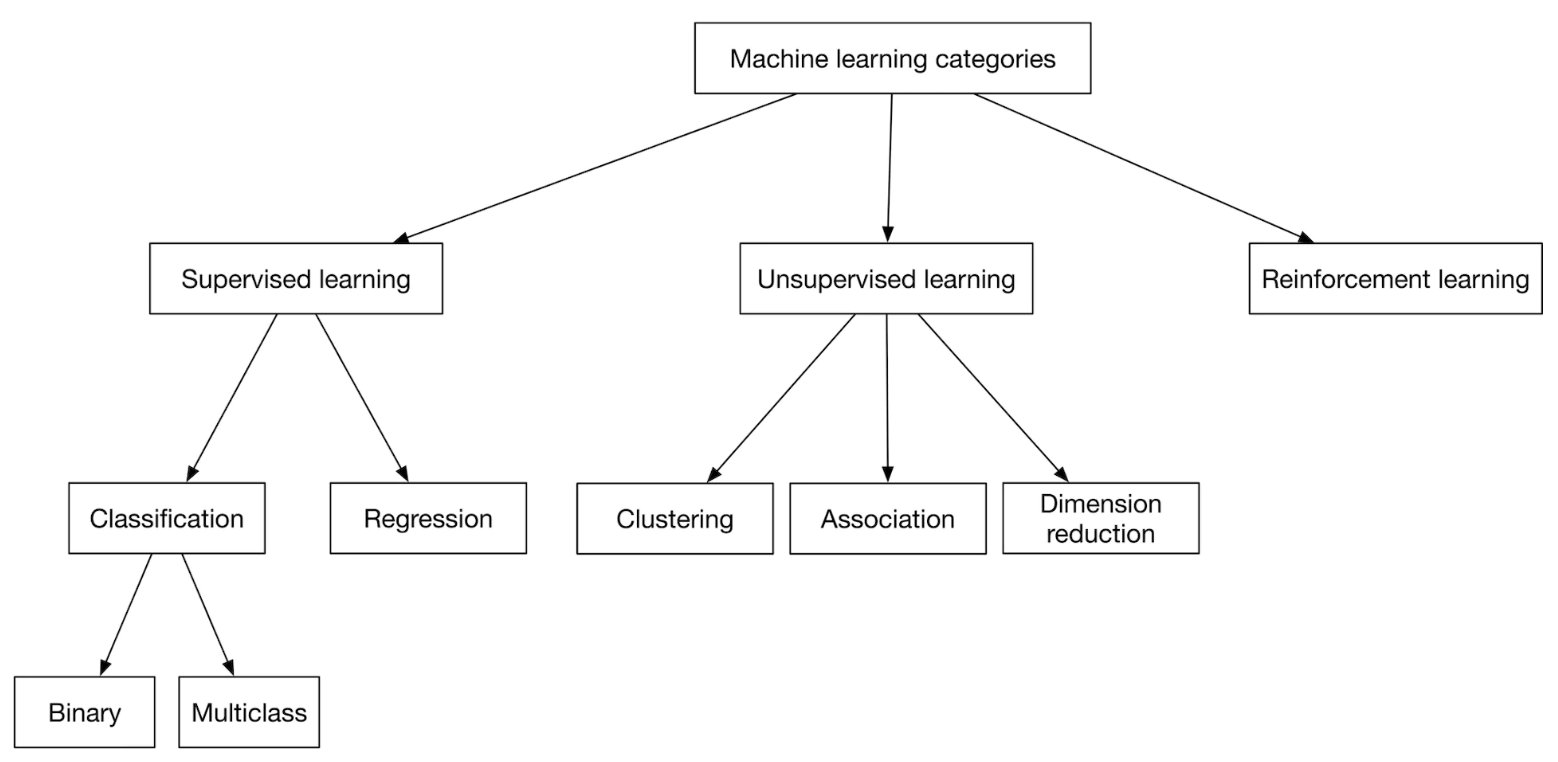
Figure 6:Common ML categories
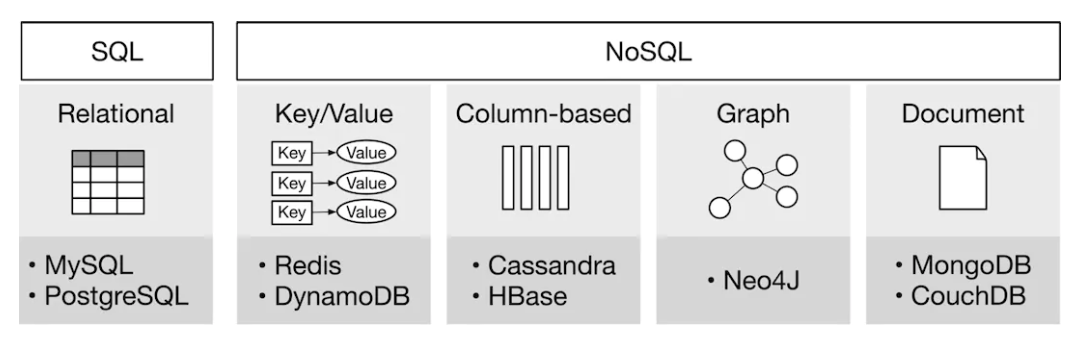
Figure 7:Different types of databases
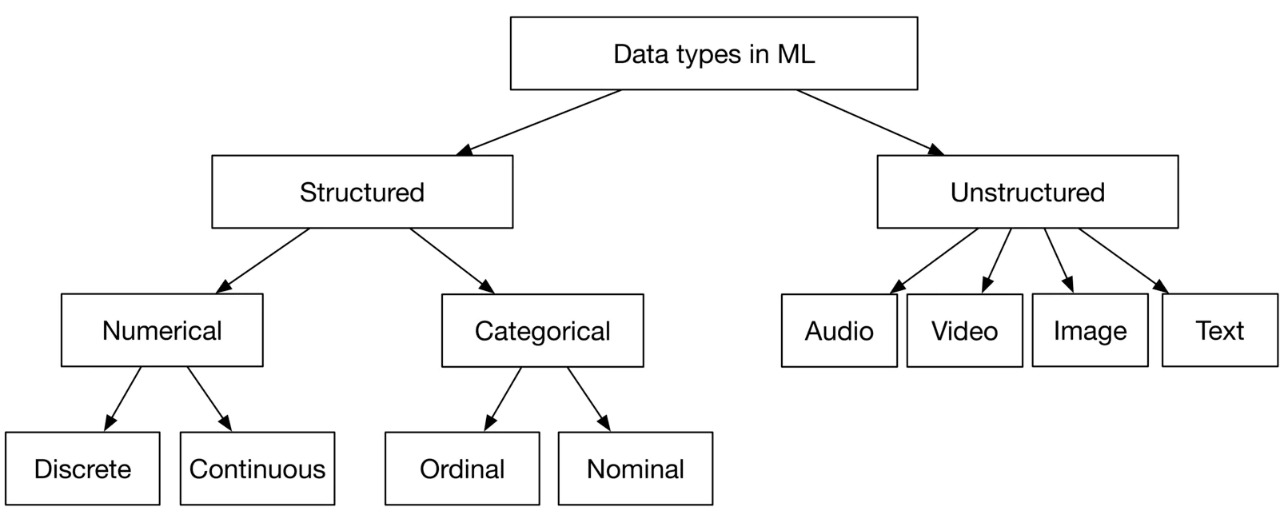
Figure 8:Data types in ML
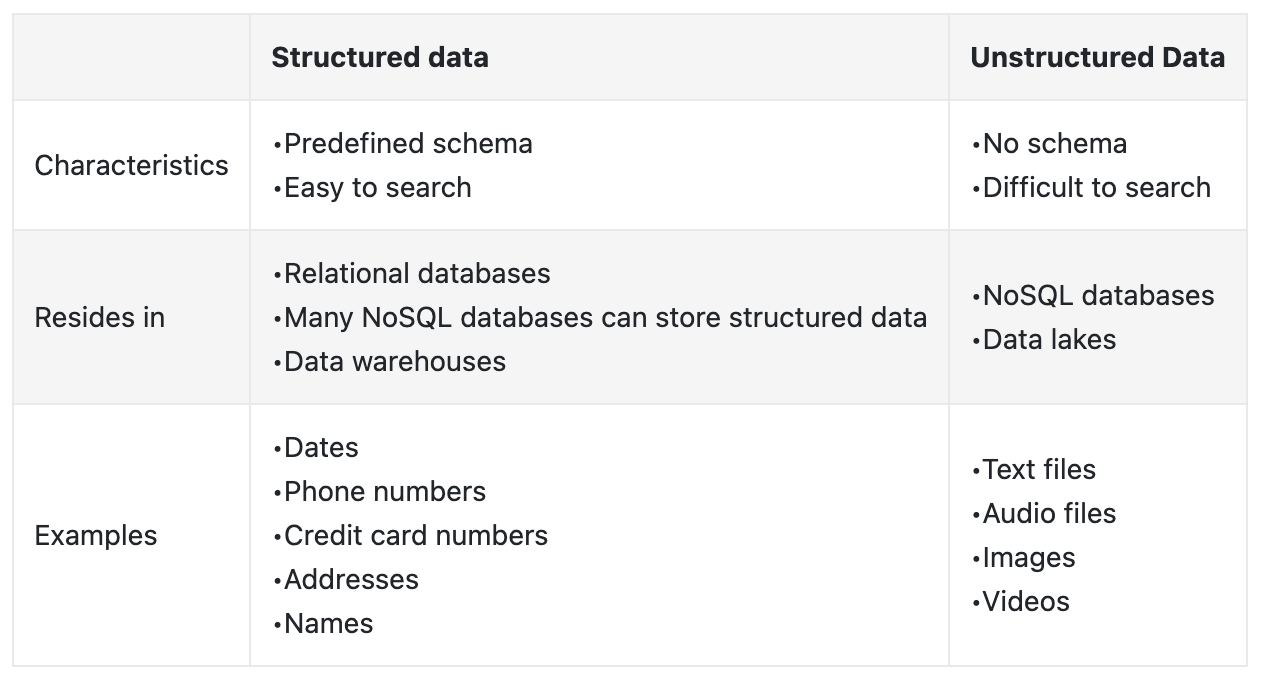
Figure 9:Summary of structured and unstructured data
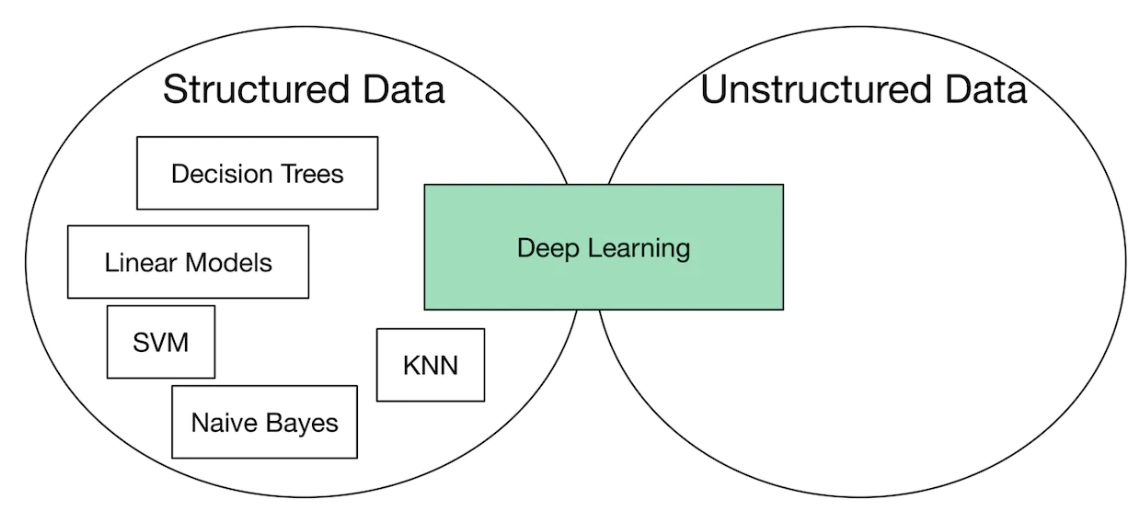
Figure 10:Models for structured and unstructured data (source [ 2 ])

Figure 11:Dataset construction steps
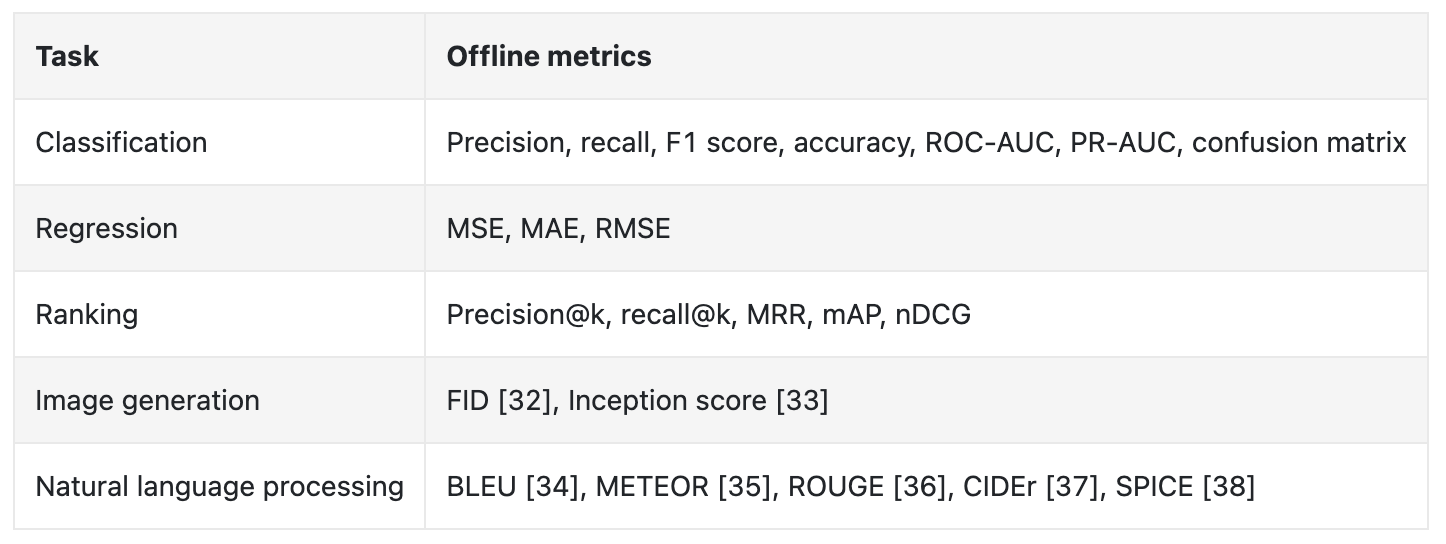
Figure 12:Popular metrics in offline evaluation

Figure 13:Possible metrics in online evaluation
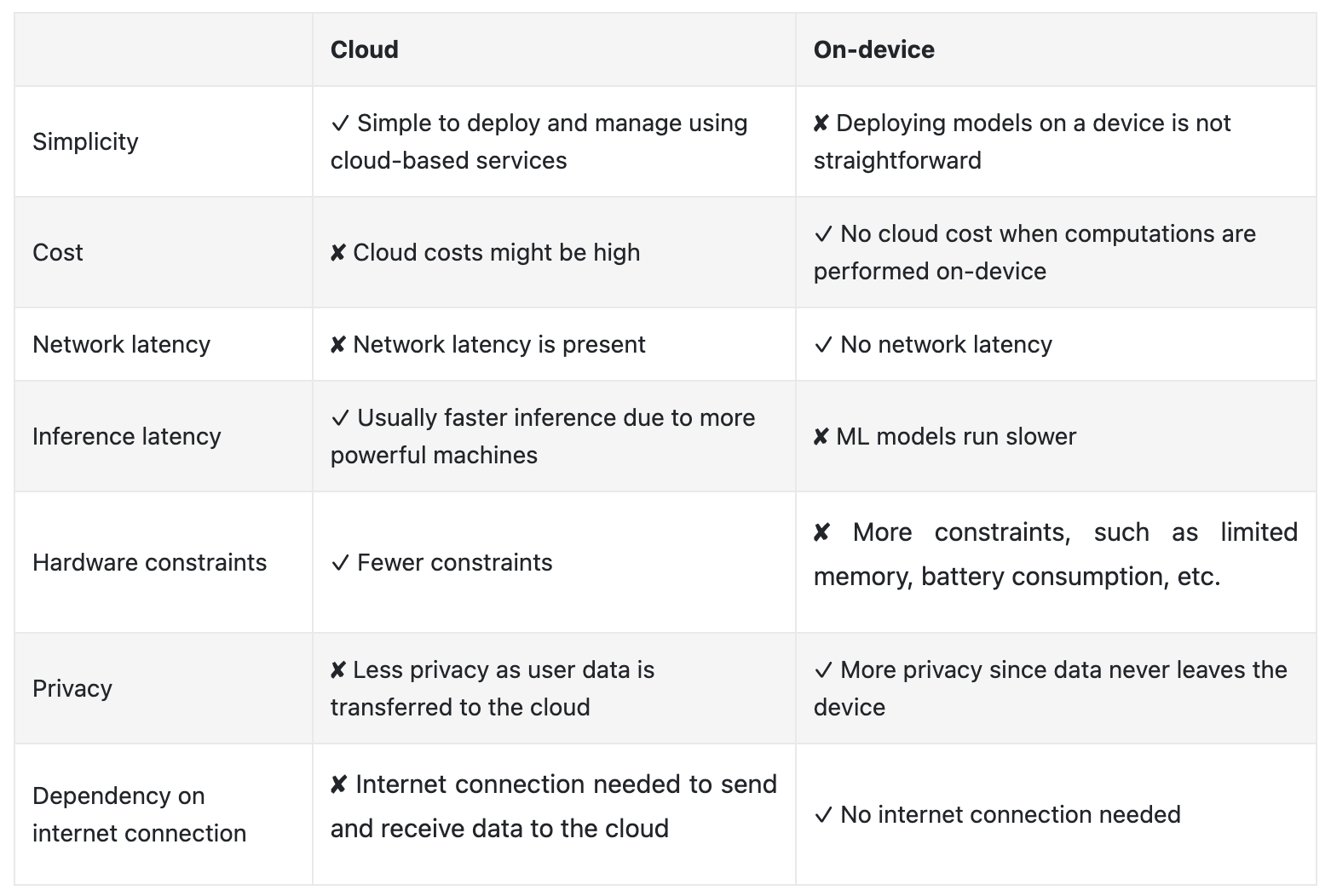
Figure 14:Trade-offs between cloud and on-device deploy
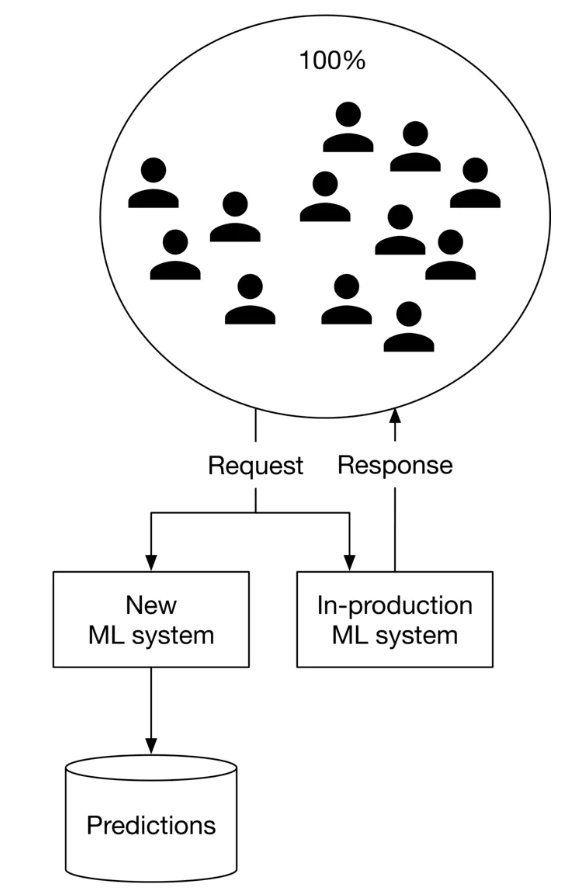
Figure 15:Shadow deployment
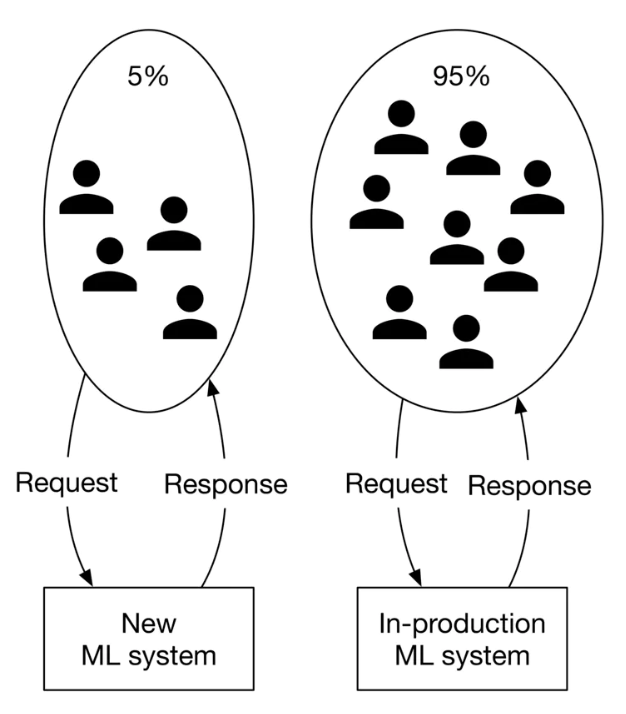
Figure 16:A/B testing
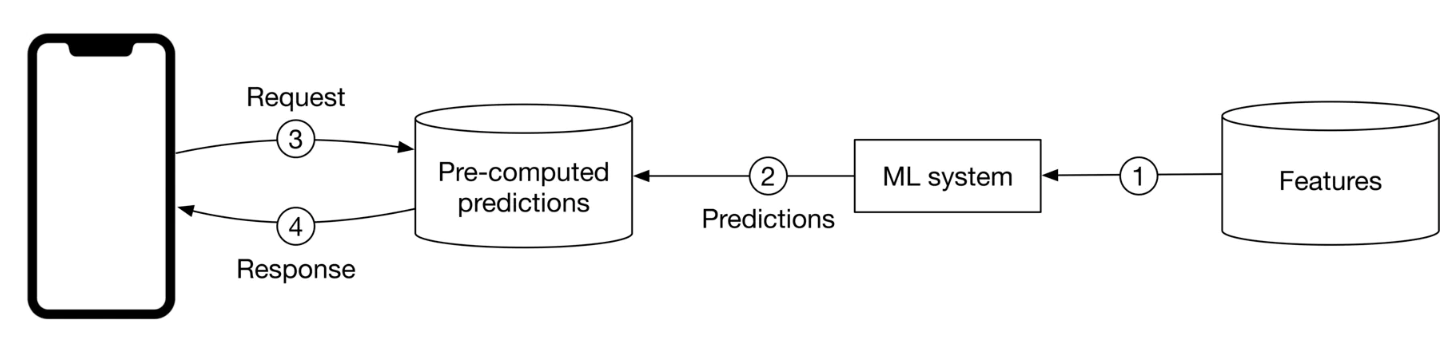
Figure 17:Batch prediction workflow
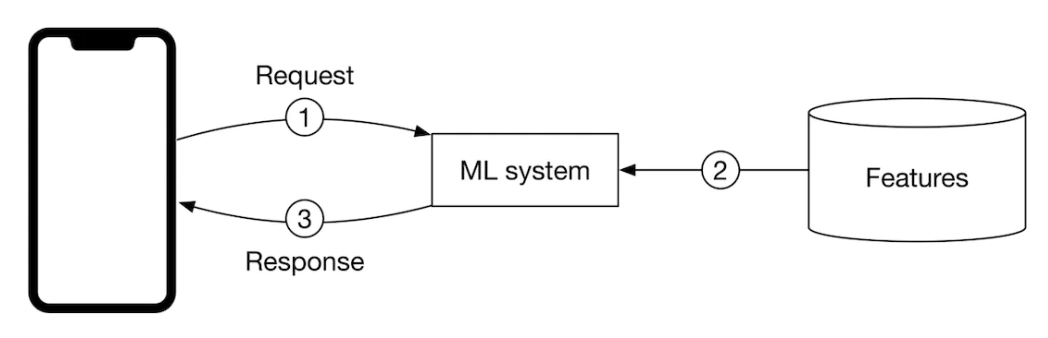
Figure 18:Online prediction workflow
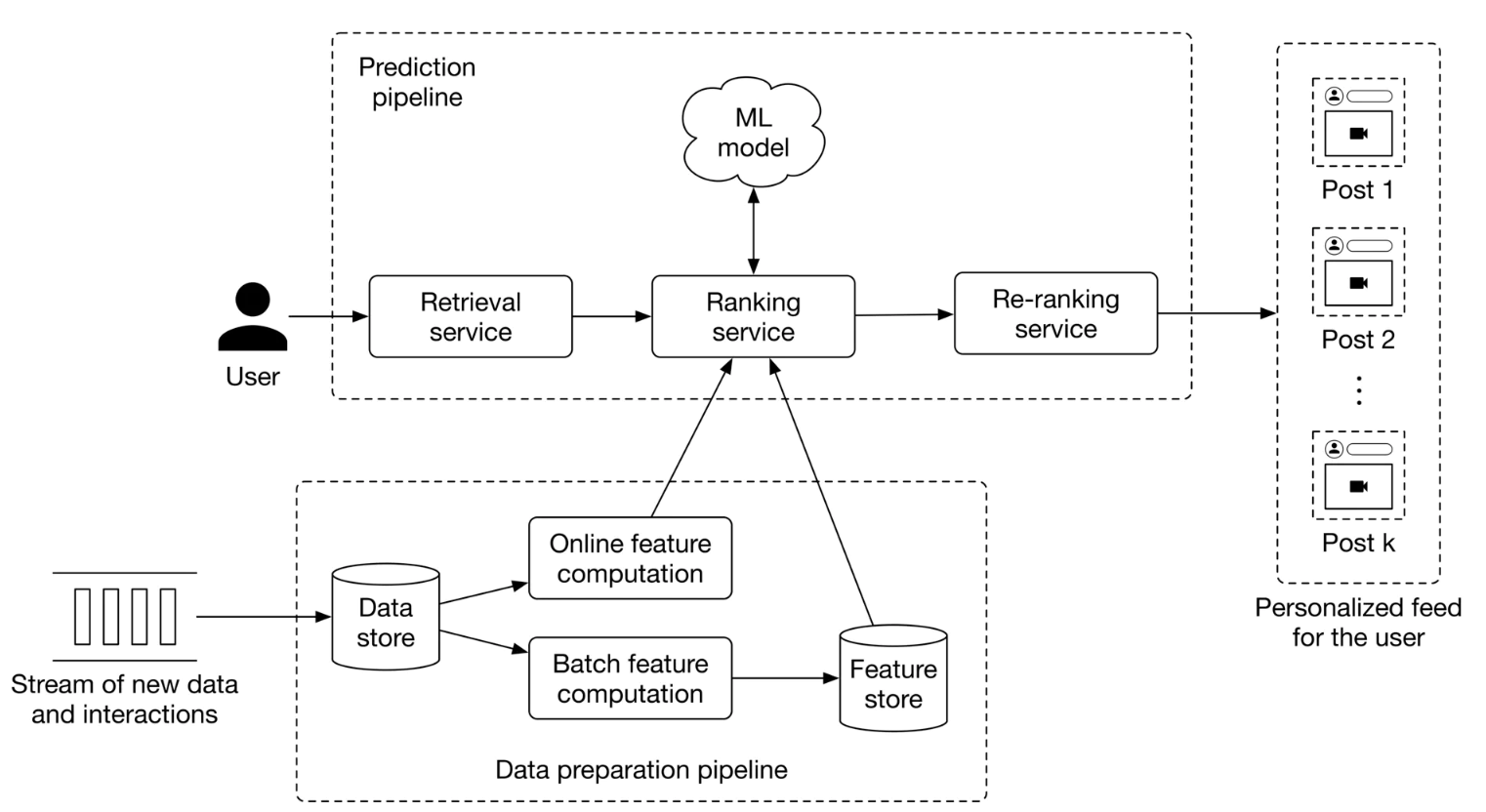
Figure 19:ML system design for a personalized news feed system
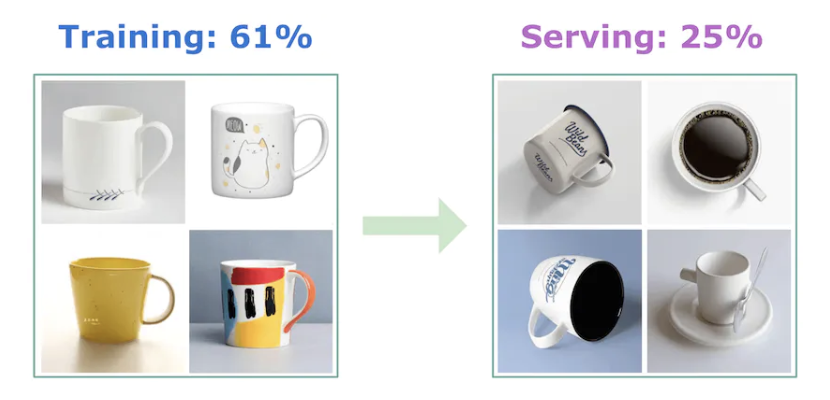
Figure 20:Data distribution shift
1
Data warehouse
2
Structured vs. unstructured data
3
Bagging technique in ensemble learning
4
Boosting technique in ensemble learning
5
Stacking technique in ensemble learning
6
Interpretability in Machine Learning
7
Traditional machine learning algorithms
8
Sampling strategies
9
Data splitting techniques
10
Class-balanced loss
11
Focal loss paper
12
Focal loss
13
Data parallelism
14
Model parallelism
15
Cross entropy loss
16
Mean squared error loss
17
Mean absolute error loss
18
Huber loss
19
L1 and l2 regularization
20
Entropy regularization
21
K-fold cross validation
22
Dropout paper
23
Overview of optimization algorithm
24
Stochastic gradient descent
25
AdaGrad optimization algorithm
26
Momentum optimization algorithm
27
RMSProp optimization algorithm
28
ELU activation function
29
ReLU activation function
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48