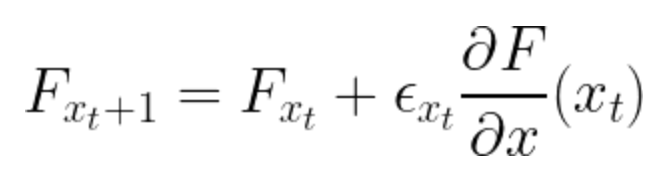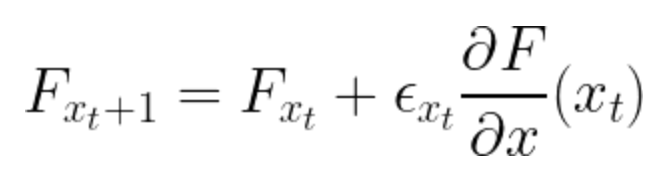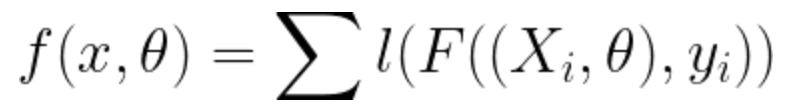Source1. Introduction• XGBoost is a popular gradient-boosting library for GPU training, distributed computing, and parallelization. It’s precise, it adapts well to all types of data and problems, it has excellent documentation, and overall it’s very easy to use. • It’s the fastest gradient-boosting library for R, Python, and C++ with very high accuracy.2. Ensemble Algorithms• Ensemble learning combines several learners (models) to improve overall performance, increasing predictiveness and accuracy in machine learning and predictive modeling.• Technically speaking, the power of ensemble models is simple: it can combine thousands of smaller learners trained on subsets of the original data. This can lead to interesting observations that, like:– The variance of the general model decreases significantly thanks to bagging– The bias also decreases due to boosting– And overall predictive power improves because of stacking2.1. Types of Ensemble Methods• Ensemble methods can be classified into two groups based on how the sub-learners are generated:– Sequential ensemble methods – learners are generated sequentially. * These methods use the dependency between base learners. * Each learner influences the next one, likewise, a general paternal behavior can be deduced. A popular example of sequential ensemble algorithms is AdaBoost. – Parallel ensemble methods – learners are generated in parallel. * The base learners are created independently to study and exploit the effects related to their independence and reduce error by averaging the results. * An example implementing this approach is Random Forest.• • Ensemble methods can use homogeneous learners (learners from the same family) or heterogeneous learners (learners from multiple sorts, as accurate and diverse as possible).2.2. Homogenous and Heterogenous ML Algorithms • Generally speaking, homogeneous ensemble methods have a single-type base learning algorithm. – The training data is diversified by assigning weights to training samples, but they usually leverage a single type base learner. • Heterogeneous ensembles on the other hand consist of members having different base learning algorithms which can be combined and used simultaneously to form the predictive model. • • A general rule of thumb: – Homogeneous ensembles use the same feature selection with a variety of data and distribute the dataset over several nodes.– Heterogeneous ensembles use different feature selection methods with the same data• Homogeneous Ensembles:– Ensemble algorithms that use bagging like Decision Trees Classifiers– Random Forests, Randomized Decision Trees• • Heterogeneous Ensembles:– Support Vector Machines, SVM– Artificial Neural Networks, ANN– Memory-Based Learning methods– Bagged and Boosted decision Trees like XGBoost2.3. Important Characteristics of Ensemble Algorithms2.3.1. Bagging• Decrease overall variance by averaging the performance of multiple estimates. • Aggregate several sampling subsets of the original dataset to train different learners chosen randomly with replacement, which conforms to the core idea of bootstrap aggregation. • Bagging normally uses a voting mechanism for classification (Random Forest) and averaging for regression.
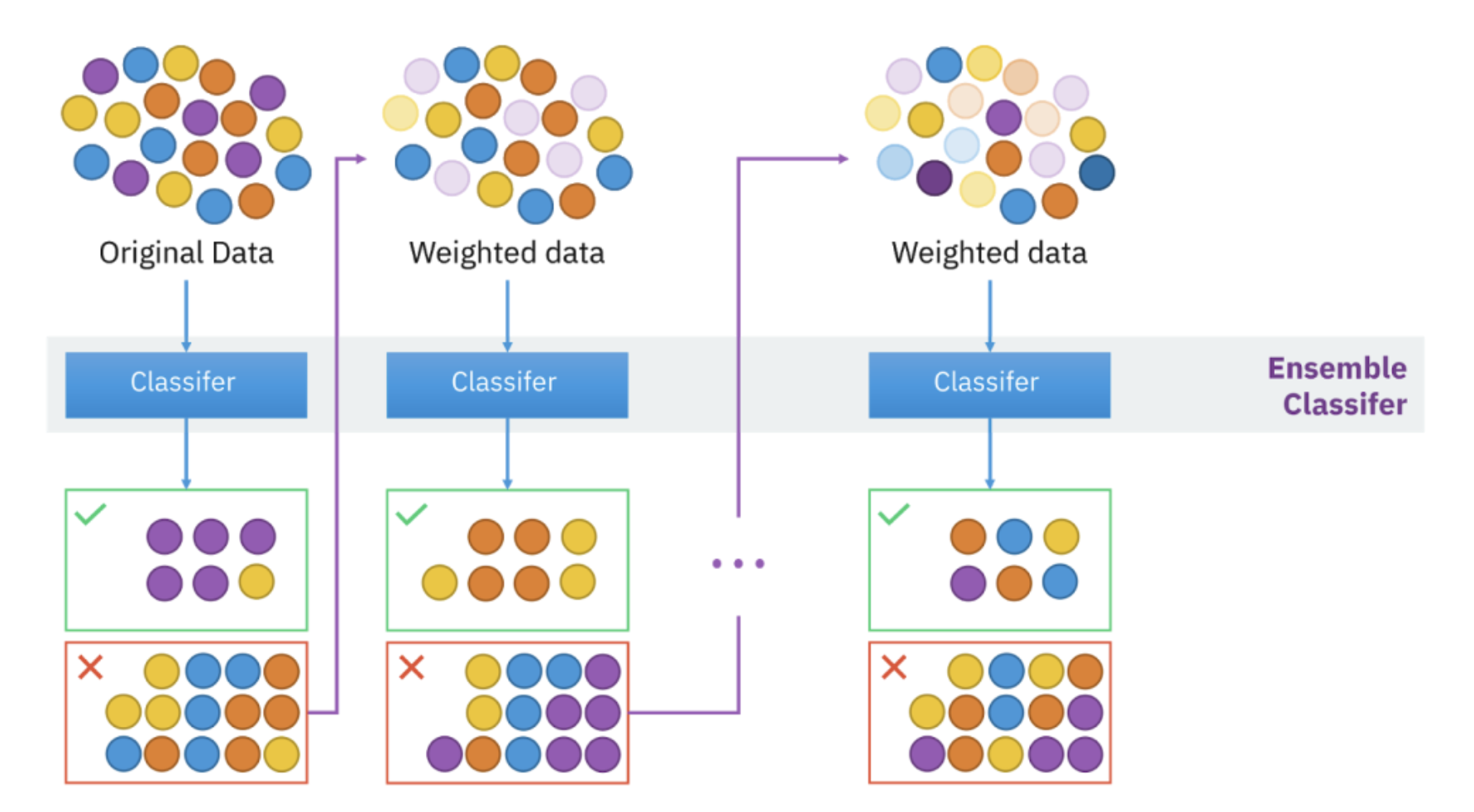
• Note:Remember that some learners are stable and less sensitive to training perturbations. Such learners, when combined, don’t help the general model to improve generalization performance.2.3.2. Boosting• This technique matches weak learners — learners that have poor predictive power and do slightly better than random guessing — to a specific weighted subset of the original dataset. Higher weights are given to subsets that were misclassified earlier.• Learner predictions are then combined with voting mechanisms in case of classification or weighted sum for regression.
2.4. Well-Known Boosting Algorithms2.4.1. AdaBoost• AdaBoost stands for Adaptive Boosting. The logic implemented in the algorithm is:– First-round classifiers (learners) are all trained using weighted coefficients that are equal,– In subsequent boosting rounds the adaptive process increasingly weighs data points that were misclassified by the learners in previous rounds and decrease the weights for correctly classified ones.
Figure 1:AdaBoost Pseudo Algorithm
2.4.2. Gradient Boosting• Gradient Boosting uses differentiable function losses from the weak learners to generalize.• At each boosting stage, the learners are used to minimize the loss function given the current model. • Boosting algorithms can be used either for classification or regression.
3. What is XGBoost Architecture?• XGBoost stands for Extreme Gradient Boosting. • It’s a parallelized and carefully optimized version of the gradient boosting algorithm.– Parallelizing the whole boosting process hugely improves the training time. • Instead of training the best possible model on the data (like in traditional methods), we train thousands of models on various subsets of the training dataset and then vote for the best-performing model.• For many cases, XGBoost is better than usual gradient boosting algorithms. • The Python implementation gives access to a vast number of inner parameters to tweak for better precision and accuracy.• Some important features of XGBoost are:– Parallelization: The model is implemented to train with multiple CPU cores.– Regularization: XGBoost includes different regularization penalties to avoid overfitting. Penalty regularizations produce successful training so the model can generalize adequately.– Non-linearity: XGBoost can detect and learn from non-linear data patterns.– Cross-validation:Built-in and comes out-of-the-box.– Scalability: XGBoost can run distributed thanks to distributed servers and clusters like Hadoop and Spark, so you can process enormous amounts of data. It’s also available for many programming languages like C++, JAVA, Python, and Julia. 4. How Does the XGBoost Algorithm Work?• Consider a function or estimate .• To start, we build a sequence derived from the function gradients. • The equation below models a particular form of gradient descent. • This represents the loss function to minimize hence it gives the direction in which the function decreases. • The rate of change fitted to the loss function. It’s equivalent to the learning rate in gradient descent, expected to approximate the behavior of the loss suitably.
• To iterate over the model and find the optimal definition we need to express the whole formula as a sequence and find an effective function that will converge to the minimum of the function. • This function will serve as an error measure to help us decrease the loss and keep the performance over time. • The sequence converges to the minimum of the function . • This particular notation defines the error function that applies when evaluating a gradient boosting regressor.
• Math of Gradient Boosting5. Other Gradient Boosting Methods5.1. Gradient Boosting Machine (GBM)• GBM combines predictions from multiple decision trees, and all the weak learners are decision trees. • The key idea with this algorithm is that every node of those trees takes a different subset of features to select the best split. • As it’s a Boosting algorithm, each new tree learns from the errors made in the previous ones.• Understanding LightGBM Parameters (and How to Tune Them)5.2. Categorical Boosting (CatBoost)• This particular set of Gradient Boosting variants has specific abilities to handle categorical variables and data in general. • The CatBoost object can handle categorical variables or numeric variables, as well as datasets with mixed types. That’s not all. • It can also use unlabelled examples and explore the effect of kernel size on speed during training.• CatBoost: A machine learning library to handle categorical (CAT) data automatically6. XGBoost Pros and Cons6.1. Advantages• Gradient Boosting comes with an easy to read and interpret algorithm, making most of its predictions easy to handle.• Boosting is a resilient and robust method that prevents and curbs over-fitting quite easily.• XGBoost performs very well on medium, small, data with subgroups and structured datasets with not too many features. • It is a great approach to go for because the large majority of real-world problems involve classification and regression, two tasks where XGBoost is the reigning king. 6.2. Disadvantages• XGBoost does not perform so well on sparse and unstructured data.• A common thing often forgotten is that Gradient Boosting is very sensitive to outlierssince every classifier is forced to fix the errors in the predecessor learners. • The overall method is hardly scalable. This is because the estimators base their correctness on previous predictors, hence the procedure involves a lot of struggle to streamline.